Importar herramientas de cifrado a Rusia: desacreditar los mitos. ¿Existe un único procedimiento de importación para diferentes herramientas de cifrado?
Las características geométricas y de contenido de los campos pueden ser absolutamente independientes o interrelacionadas. Por ejemplo, en una orden de recibo junto a los campos "cantidad" y "precio" hay un campo "monto".
Los documentos que deben escanearse se pueden agrupar según varios criterios. Según el método de aplicación de la información, se pueden distinguir documentos que utilizan marcas, textos impresos o escritos a mano. Así, por ejemplo, en las "papeletas de votación" se utiliza el método de marca, mientras que las "listas de precios" se imprimen y los documentos contables primarios se escriben principalmente a mano.
Realizar una descripción de la configuración del sistema para un tipo específico de documento también implica realizar un desarrollo. configuración del modelo de entrada documento en base de información o en archivo y compilación electrónica establecer la correspondencia entre los campos del formulario del documento y los campos de indexación para su entrada en una base de información o archivo. La construcción de estos escenarios se basa en la existencia de tres enfoques para ingresar datos a la base de datos:
Ingresar palabras clave. En este caso, se utilizarán una o más palabras clave como índices para una imagen en particular. En el futuro, será posible acceder rápidamente a la imagen del documento utilizando las palabras clave ingresadas: índices.
Ingresando el texto completo del documento. Se ingresan todas las palabras del documento y luego es posible realizar una búsqueda de texto completo de la imagen del documento utilizando el índice de texto completo compilado para este documento. Este método se puede utilizar si es necesario obtener una versión de texto de un documento.
Entrada de datos basada en formularios. Este método se utiliza para reemplazo completo entrada manual de datos en sistemas informáticos y se utiliza principalmente para ingresar datos de formularios (documentos estándar, similares). En este caso, los atributos del documento se utilizarán para compilar un índice del documento para buscarlo y almacenarlo en una base de datos o archivo.
La etapa principal de la entrada automatizada de documentos en papel incluye la realización de operaciones tales como:
Exploración;
Control de calidad de imágenes escaneadas y reescaneo;
Preprocesamiento de texto;
Procesamiento básico de textos de documentos;
Control de calidad y edición del reconocimiento;
Exploración– esta es una operación muy responsable y, por lo tanto, la elección de un modelo de escáner específico debe abordarse de manera bastante responsable. Al elegir, se deben considerar los siguientes factores: el tamaño de los documentos, su estado, si el documento es de una o dos caras, el rendimiento de los escáneres, la resolución de imagen requerida, la confiabilidad de las imágenes resultantes y otros.
Actualmente en el mercado medios tecnicos se ofrece suficiente gran número Varios modelos de escáner que se pueden clasificar según su rendimiento. los siguientes tipos(ver tabla 5.1):
Personal;
Superficie de la mesa;
Transmisión de alto rendimiento.
Según la calidad del escaneo, según la resolución, se pueden dividir en los siguientes grupos:
Baja resolución (200–400 ppp);
Con resolución media (600–800 ppp);
Alta resolución (1600–2800 ppp);
Propósito especial.
La entrada de documentos impone exigencias bastante bajas a la calidad del escaneo; normalmente es suficiente una resolución de 200-300 ppp. Los escáneres de publicaciones profesionales tienen una resolución del orden de puntos/pulgada, e incluso los escáneres personales tienen una resolución de aproximadamente 600-800 ppp. La única característica distintiva es la alimentación automática de páginas de documentos y la alta velocidad de escaneo (de 10 a 200 hojas A4 por minuto). Estos escáneres de alta velocidad están diseñados para ingresar documentos impresos.
Para la introducción de documentos antiguos se utilizan escáneres con sujeción de documentos por vacío, que exigen muy poco al documento y lo procesan de forma cuidadosa. En casos muy raros, cuando un documento es tan antiguo que no se puede colocar ni siquiera en escáner de superficie plana, se utilizan escáneres especiales. Estos escáneres le permiten escanear libros parcialmente abiertos y documentos de mala calidad. La velocidad de entrada de dichos dispositivos es de 0,25 a 3 páginas por minuto.
Tratamiento de los datos contenidos en el documento, Implica realizar las siguientes operaciones básicas:
Preprocesamiento de imágenes;
Procesamiento básico de imágenes de documentos.
Preprocesamiento de imágenes de documentos. se utiliza para mejorar las imágenes resultantes y es necesario por las siguientes razones:
Legibilidad de imagen mejorada. Las imágenes procesadas son más comprensibles cuando se ven visualmente.
Mejora de la precisión del reconocimiento. El uso de técnicas especiales de mejora de imágenes puede mejorar significativamente la precisión. reconocimiento óptico personajes.
Reducir el tamaño de la imagen. El tamaño del archivo de las imágenes procesadas puede ser hasta un 80% más pequeño que el tamaño original. Reducir el tamaño significa simplemente comprimir el archivo y eliminar información innecesaria.
El preprocesamiento de imágenes de documentos implica el uso de los siguientes métodos: la limpieza de imágenes se utiliza para eliminar elementos individuales de las imágenes (por ejemplo, puntos, manchas); eliminar fondos y aspectos destacados (por ejemplo, de valores); restauración de letras y símbolos, si se cruzan con elementos del formulario, por ejemplo, una línea (para el reconocimiento posterior de un símbolo, es necesario eliminar la línea para que la letra no se dañe); rotar la imagen en un ángulo arbitrario; escalado de imágenes; control de nivel de grises; Compresión y descompresión de imágenes.
Proceso básico de procesamiento de documentos. prever las siguientes operaciones:
Búsqueda de campos (segmentación de documentos);
Reconocimiento de texto de documentos .
Se pueden realizar de forma secuencial e independiente si los campos están completamente definidos por sus características visuales. Esta situación es típica de formularios y documentos legibles por máquina con separadores de campos obvios en forma de líneas o espacios grandes.
Reconocimiento de documentos, análisis de contenido de documentos y extracción de datos. Se puede realizar mediante los siguientes sistemas de reconocimiento de texto, diferenciándose en coste, calidad y rapidez:
OCR (Reconocimiento óptico de caracteres) es una tecnología para el reconocimiento óptico de caracteres impresos, es decir, convertir una imagen escaneada de caracteres impresos en su representación de texto;
ICR (Reconocimiento inteligente de caracteres): reconocimiento de caracteres impresos individuales escritos a mano;
OMR (Reconocimiento óptico de marcas): reconocimiento de marcas (generalmente cuadrados o círculos tachados transversalmente o con marcas);
Números estilizados: reconocimiento de números escritos a mano según una plantilla, como en los sobres postales;
Existen varios enfoques para implementar tecnologías para ingresar caracteres escritos a mano:
El reconocimiento en línea se realiza en el momento en que una persona escribe con un bolígrafo especial en una pantalla táctil que percibe información adicional sobre la trayectoria del movimiento de la mano, inclinación del lápiz, fuerza de presión, etc. Se utiliza principalmente en electrónica personal. cuadernos escriba 3Com PalmPilot para la entrada manuscrita de datos numéricos y de caracteres.
Reconocimiento fuera de línea: reconocimiento de texto escrito a mano arbitrario ingresado en una computadora a través de un escáner.
El reconocimiento de huellas de manos es un subconjunto de la tecnología de reconocimiento fuera de línea. Este método se utiliza generalmente para ingresar formularios estándar. Reconocer el texto escrito a mano es mucho más difícil que el texto impreso, porque si en este último caso se trata de un número limitado de variaciones de imágenes de fuentes (plantillas), en la versión escrita a mano el número de plantillas es inmensamente mayor.
Para los sistemas OCR se utilizan principalmente tres tipos de tecnologías de reconocimiento de texto impreso:
Basado en matrices
Descriptivo (basado en la descripción de las reglas para la construcción de símbolos),
Neural (basado en el uso de redes neuronales).
El estricto cumplimiento del estándar de apariencia de formulario aumenta significativamente la precisión del reconocimiento de campos del documento.
Control de datos reconocidos es la siguiente operación implementada por el sistema de entrada.
Los sistemas de reconocimiento automático suelen devolver junto con el resultado el llamado "grado de confianza". Para aumentar la confiabilidad de los datos después del reconocimiento, se utilizan métodos de verificación de datos automatizados definidos por el usuario (por ejemplo, puede verificar si la información reconocida está en la base de datos y, si no, marcar el campo como incorrecto). Para mejorar la confiabilidad de los datos, se utilizan mecanismos adicionales, como el uso de diccionarios y tablas definidas por el usuario. Además, los sistemas incluyen herramientas especiales integradas para definir procedimientos de validación específicos para cada campo del documento.
Si los datos se marcan como incorrectos después del reconocimiento, se envían automáticamente para su edición manual. Durante la edición, el operador ve la imagen real del campo no reconocido y tiene la oportunidad de corregirlo. Después de que el operador ingresa nuevos datos, las reglas de verificación de datos se aplican nuevamente, es decir, en todas las etapas de ingreso, tanto automática como manual, los datos se verifican de acuerdo con las reglas definidas por el usuario.
Indexación y carga de datos. La operación final del proceso es la exportación de imágenes de documentos y datos asociados a un sistema de gestión de documentos o base de datos específica y su indexación. Los principales requisitos para la exportación son el apoyo. varios formatos datos y su velocidad.
Una vez que se reconoce un documento, ingresa a una base de datos o sistema de gestión documental donde se indexa. A diferencia de sistema convencional El sistema de reconocimiento para ingresar formularios estándar utiliza una descripción formal. forma original documento, descripción del modelo de entrada y del modelo de correspondencia para campos de entrada e indexación. Esto le permite indexar documentos automáticamente y cargar información en campos o archivos de bases de datos sin intervención del operador.
Dependiendo de la tarea específica y el tipo de documento, se puede cargar en un módulo de texto completo o la información extraída de él deberá ingresar al sistema de indexación de atributos (por ejemplo, los valores de los campos del formulario terminan en una tarjeta de documento). En este caso, se puede guardar una imagen del documento.
5.2 Requisitos para SMV. Características de los sistemas.
El factor principal a la hora de evaluar la eficacia de los sistemas de reconocimiento es el coste de corregir los errores de reconocimiento, más que la precisión y velocidad del sistema. En algunos casos, el costo de corregir errores en el reconocimiento puede cubrir todas las ventajas de la automatización y hacer entrada manual Según la imagen más efectiva. Al desarrollar y utilizar CMS, el diseñador también necesita realizar una gran cantidad de trabajo para integrar este sistema de entrada en un sistema de información existente o desarrollado. El rendimiento del sistema se ve muy afectado. gran influencia La tecnología de entrada utilizada, su adaptación a la tarea actual y el tipo de documentos influyen. Aquí es necesario tener en cuenta la composición del equipo, el software y la compatibilidad del formato de información reconocido con los sistemas existentes.
Hay muchas empresas que ofrecen soluciones o componentes de sistemas de procesamiento de moldes. La decisión de implementar un sistema de procesamiento de formularios, así como la elección de una aplicación en particular, debe tomarse teniendo en cuenta, en primer lugar, los siguientes requisitos:
El tipo de documentos que se procesan y el tipo de datos que contienen;
Precisión del reconocimiento;
Disponibilidad de un sistema de edición eficaz;
Personalización del sistema según los requisitos de un cliente específico y la capacidad de cambiar según los cambios. condiciones externas sin programación;
Disponibilidad de soporte para varios tipos de escáneres, así como para varios tipos de placas de procesamiento de imágenes de documentos;
La presencia de un editor de formularios que configura el sistema para nuevos formularios o cambios a un formulario antiguo para el cual el sistema estaba orientado anteriormente;
Disponibilidad de un editor para esquemas de procesamiento de documentos, interfaz abierta conectando varios módulos de reconocimiento (dependiendo del tipo de formulario, se puede conectar uno u otro módulo que sea más adecuado para de este tipo formularios);
Disponibilidad de un editor para exportar esquemas a una base de datos (los datos que se extraen durante el procesamiento del formulario deben transferirse a una base de datos para su almacenamiento o a otras aplicaciones comerciales para su procesamiento).
Además, se pueden presentar un conjunto de requisitos generales a la hora de elegir un software para CMS:
Franqueza. El sistema debe permitir la inclusión de diversas tecnologías y productos de software dependiendo de la aplicación específica, incluso si estos productos son suministrados por otras empresas. Se requiere la capacidad de integrarse con varios sistemas de flujo de trabajo y sistemas de gestión de documentos.
Posibilidad de personalización. Interfaz de usuario debe ser personalizable para maximizar la eficiencia del operador.
Escalabilidad. Debe poder agregar y reducir recursos del sistema en diferentes niveles de carga del sistema.
Posibilidad de administración. El usuario debe poder controlar el sistema de forma flexible. Es necesario poder controlar los recursos y herramientas utilizados para obtener diversos tipos de informes.
Consideremos como ejemplo dos sistemas de la clase CMB: Cognitive Forms de Cognitive Technologies y FineReader.
Formas cognitivas – sistema ruso Entrada industrial (a veces llamada streaming) de formularios de documentos estándar, que se ejecuta en los sistemas operativos Windows 95/NT y MacOS. El sistema pertenece a la clase OCR/ICR/OMR y le permite ingresar y sistemas de información formularios con relleno impreso, escrito a mano y marcas (casilla de verificación).
Cognitive Forms está diseñado para la entrada automatizada en sistemas de información y bases de datos de formularios arbitrarios de documentos de una o varias páginas que cumplen con ciertos requisitos de diseño y finalización y se preparan en impresoras láser, de inyección de tinta y matriciales o en formularios estándar utilizando máquinas de escribir.
Este sistema permite el procesamiento de subprocesos distribuidos (escaneo, reconocimiento, edición y control) en una red con un rendimiento de reconocimiento de hasta páginas A4 por turno en una computadora y control automático de los resultados del reconocimiento. Los datos se pueden exportar a bases de datos, sistemas bancarios como “Operational Day” y sistemas para la creación de archivos electrónicos y automatización de documentos.
La implementación del sistema permite acelerar la entrada de formularios de documentos estándar entre 5 y 10 veces en comparación con la entrada manual.
Las imágenes escaneadas se pueden guardar en el archivo electrónico del banco para mantener el historial de registros de la organización.
Cognitive Forms consta de tres módulos principales:
Cognitive FormDesigner es responsable de diseñar descripciones de formularios de documentos para programas de reconocimiento y edición.
Cognitive FormReader proporciona reconocimiento automático del flujo de formularios estándar provenientes del escáner. En modo automático, realiza un reconocimiento continuo de formas mediante descripción dada y verificación contextual de los resultados.
Cognitive FormEditor está diseñado para el control del operador de formularios reconocidos y para guardar información de los formularios ingresados en registros de bases de datos y permite al operador controlar y editar visualmente los campos de formulario reconocidos.
Cognitive Forms permite llevar a cabo el procesamiento distribuido de formularios de entrada dentro de una red local y lograr un acceso efectivo a los datos en tiempo real. Por ejemplo, en un Pentium II-233, el tiempo que le toma al sistema Cognitive Forms reconocer una forma es de aproximadamente 2 segundos. Para la entrada industrial se utilizan escáneres de alto rendimiento: Kodak, Bell+Howell, BancTec, Fujitsu, etc., así como dispositivos de red (Hewlett-Packard). El rendimiento de algunos modelos alcanza cientos de páginas por minuto.
La efectividad de utilizar un sistema para ingresar documentos en papel en un EIS se basa, en primer lugar, en una reducción significativa de la participación humana en la entrada de datos. Como resultado, se puede observar una disminución en el tiempo de entrada de documentos y en la cantidad de errores. Para organizaciones que procesan grandes flujos formularios (departamentos centrales de impuestos y correos, organizaciones estadísticas, centros de autorización de pagos con tarjetas de crédito), el uso de las tecnologías descritas resolverá los problemas de procesamiento eficiente de cientos de miles e incluso millones de formularios en poco tiempo.
El sistema FineReader, desarrollado por ABBYY, se basa en tres principios de reconocimiento, formulados a partir de la observación del comportamiento de animales y humanos: Integridad, Propósito y Adaptabilidad, lo que permitió obtener una solución basada en los principios de reconocimiento característicos de los sistemas vivos. - el reconocimiento de tecnología Integrity Purposeful Adaptive (tecnología IPA).
Integridad. Un objeto se describe como un todo utilizando elementos significativos y relaciones entre ellos. Un objeto se reconoce como objeto de una clase determinada sólo si están presentes todos los elementos de la descripción y las relaciones necesarias entre ellos.
Enfocar. El reconocimiento se construye como un proceso de plantear y probar hipótesis de manera deliberada. El enfoque tradicional de interpretar lo que se observa en una imagen será reemplazado por un enfoque de búsqueda deliberada de lo que se espera en la imagen.
Adaptabilidad. La capacidad del sistema de autoaprendizaje, es decir, primero el sistema FineReader plantea una hipótesis sobre el objeto de reconocimiento (un símbolo, parte de un símbolo o varios símbolos pegados) y luego la confirma o refuta, tratando de detectar consistentemente todos elementos estructurales en las relaciones correctas. Los elementos estructurales utilizados son aquellos que son importantes para la percepción de un objeto desde el punto de vista humano: segmentos, arcos, anillos y puntos.
Siguiendo el principio de adaptabilidad, el programa se "adapta" de forma independiente a una nueva fuente (o a una nueva escritura), aprovechando la experiencia positiva adquirida con los primeros caracteres reconocidos con seguridad.
La búsqueda dirigida y el conocimiento del contexto ayudan a identificar imágenes rotas y distorsionadas, lo que hace que el sistema sea resistente a los defectos de impresión.
Estos principios se utilizan tanto para reconocer caracteres individuales como para analizar el diseño de la página (seleccionar secciones de texto, imágenes, tablas). Utilizando la tecnología IPA, FineReader demuestra alta calidad En la mayoría de los casos se observa un reconocimiento con baja sensibilidad a los defectos de impresión y un análisis impecable del diseño de la página. pruebas comparativas. ABBYY recibió una patente para el uso de la tecnología IPA. El sistema FineReader tiene dos opciones de implementación: FineReader Office y FineReader from Pro, que se desarrollan constantemente.
El sistema FineReader tiene los siguientes formatos de archivo de entrada: BMP: blanco y negro, gris, color; PCX, DCX: blanco y negro, gris, color; JPEG: gris, color; PNG: blanco y negro, gris, color; TIFF: blanco y negro, gris, color, varias páginas.
Al recibir documentos, se utilizan varios métodos de compresión de texto: sin comprimir, CCITT Grupo 3, CCITT Grupo 3 FAX (2D), CCITT Grupo 4, PackBits, JPEG.
El sistema FineReader guarda el resultado del reconocimiento en los siguientes formatos: Microsoft Word 95, Microsoft Excel 95, Microsoft Word 97, Microsoft Excel 97, Microsoft Word 2000, Microsoft Excel 2000, texto, formato de texto enriquecido, texto Unicode, DBF, HTML, CSV. , HTML Unicode, PDF.
Requisitos del sistema: sistema operativo Windows 2000, Windows NT Workstation 4.0 SP3 o superior, o Windows 95/98.
El sistema admite 19 tipos de escáneres, incluidos Acer, Samsung, Mitsubishi, Scanpaq, Canon, Syscan, E-Lux, Nikon, Silitek, Epson, Storm, Fujitsu, Packard Bell, HP, IBM, Xerox, Kodak, etc. y más. de 100 modelos de escáneres 100% compatibles con TWAIN de otras empresas.
Tema 6. Automatización del almacenamiento electrónico.
documentos
6.1 El concepto de sistema de recuperación de información (IRS). Composición de componentes y tecnología para trabajar con IPS.
En curso empresas modernas papel importante Juega con sus recursos de información, que pueden entenderse como documentación del proyecto, correspondencia con socios, órdenes e instrucciones internas, datos financieros y otros documentos que sirven de base para la toma de nuevas decisiones y se utilizan en los procesos de gestión empresarial. Y si los sistemas de información especializados (como los de contabilidad o sistema de comercio o sistemas del departamento de planificación) basados en el uso de un DBMS, entonces, para datos no estructurados, necesitamos sistemas de propósito general: archivos electrónicos que funcionen según los principios de un sistema de recuperación de información.
Un sistema de recuperación de información (IRS) es un sistema diseñado para almacenar y recuperar documentos con texto, información gráfica y tabular sobre atributos, palabras clave del documento y contenido en cualquier área temática.
Existen dos tipos de sistemas de información: los fácticos y los documentalográficos. Los sistemas de recuperación de información de tipo fáctico están diseñados para almacenar y recuperar hechos, indicadores, características de cualquier objeto o proceso (por ejemplo, información sobre empleados, empresas, accionistas, etc.). Los sistemas de recuperación de información documental se diferencian en que los objetos de almacenamiento y búsqueda en estos sistemas son documentos, informes, resúmenes, reseñas, revistas, libros, etc. El guión para buscar un documento utilizando un sistema de recuperación de información generalmente se reduce a ingresar una consulta de búsqueda. que consta de una o varias palabras, tras lo cual se presenta una lista de nombres de los documentos encontrados. El usuario puede abrir cualquiera de los documentos encontrados y, si el sistema de búsqueda lo permite, las apariciones de las palabras buscadas en el documento se resaltan - "resaltadas".
Puedes seleccionar siguientes características Organización y funcionamiento del sistema de información documental, distinguiéndolo de los sistemas gestores de bases de datos de datos estructurados:
Los documentos pueden almacenarse en papel, medios micrográficos o existir en formatos electrónicos. Los formatos micrográficos incluyen microfilmes, microfichas, diapositivas y otras microformas producidas por una variedad de cámaras de documentos. Los formatos electrónicos son aún más numerosos e incluyen documentos preparados en procesadores de texto, sistemas de correo electrónico y otros programas de computadora, imágenes digitalizadas de documentos escaneados, etc. Esto requiere el almacenamiento obligatorio tanto de copias electrónicas de los documentos como de sus originales en papel.
Si los documentos son grandes y completos. copias electrónicas No es posible emitirlos para su visualización o almacenamiento, luego se crean y almacenan direcciones de almacenamiento electrónico para dichos documentos.
La búsqueda se realiza encontrando un documento según dos principios: por los atributos del documento (fecha de creación, tamaño, autor, etc.) y por su contenido (texto). Normalmente, la búsqueda del contenido de un documento se realiza de dos formas: por palabras clave y por el texto completo, lo que se denomina texto completo, enfatizando así que para la búsqueda se utiliza todo el texto del documento, y no solo sus detalles. . –
Para buscar documentos, se crean y almacenan imágenes de búsqueda. La imagen de documento de búsqueda (SID) es un conjunto de códigos de palabras clave principales (descriptores) que describen el significado y el contenido del documento.
Las palabras clave y sus códigos se almacenan en un diccionario especial: un tesauro.
Para buscar documentos, es necesario crear un lenguaje de recuperación de información (IRL), que incluye un tesauro y una gramática del lenguaje, es decir, un conjunto de reglas para especificar un conjunto de declaraciones utilizando un conjunto de palabras clave.
Para encontrar un documento, debe crear una imagen de consulta de búsqueda (SQI), que es un conjunto de palabras clave codificadas que describen los documentos que deben encontrarse, utilizando el lenguaje IP. El diagrama de interacción de los componentes IPS se muestra en la Fig. 6.1.
servidor de archivos", por lo tanto, para resolver las tareas y problemas asignados, la opción más prometedora es elegir la opción de arquitectura para sistemas integrados de gestión de documentos - "cliente-servidor", lo que aumenta significativamente la eficiencia de los usuarios, ya que los sistemas de esta clase proporcionar no solo una búsqueda rápida de los documentos necesarios para los usuarios, sino también ayudarlos a organizar y compartir información y, lo más importante, el DMS crea una estructura fácil de usar para presentar toda la información almacenada en la red. se ahorrará la necesidad de averiguar cada vez dónde almacenarlo, cómo protegerlo y qué derechos otorgar a sus colegas.
Los sistemas de gestión documental deberían resolver el problema de gestionar grandes volúmenes de documentos basándose en los siguientes principios:
1. La gestión deberá ejercerse sobre los documentos electrónicos creados en distintos programas de aplicacion Para computadoras personales tales como: procesadores de texto, hojas de cálculo, correo electrónico.
Seminario
Diseño de sistemas de gestión documental.
El concepto de sistema de recuperación de información (IRS).
Composición de componentes y tecnología de trabajo con IPS.
En el trabajo de las empresas modernas, sus recursos de información juegan un papel importante, que puede entenderse como documentación del proyecto, correspondencia con socios, órdenes e instrucciones internas, datos financieros y otros documentos que sirven de base para la toma de nuevas decisiones y son utilizado en los procesos de gestión empresarial. Y si para almacenar datos estructurados se pueden utilizar sistemas de información especializados (como un sistema de contabilidad o comercio o un sistema de departamento de planificación) basados en el uso de un DBMS, entonces para los datos no estructurados se necesitan sistemas de uso general: archivos electrónicos que funcionan en el Principios de un sistema de recuperación de información.
Sistema de recuperación de información (IRS) – es un sistema diseñado para almacenar y buscar documentos con texto, gráficos, información tabular sobre atributos, palabras clave del documento y contenido en cualquier área temática. Existen dos tipos de sistemas de información: los fácticos y los documentalográficos. Los sistemas de recuperación de información de tipo fáctico están diseñados para almacenar y recuperar hechos, indicadores, características de cualquier objeto o proceso (por ejemplo, información sobre empleados, empresas, accionistas, etc.). Los sistemas de información documental se diferencian en que los objetos de almacenamiento y recuperación en estos sistemas son documentos, informes, resúmenes, reseñas, revistas, libros, etc. El script para buscar un documento utilizando un sistema de recuperación de información generalmente se reduce a ingresar una consulta de búsqueda que consta de una o varias palabras, después de lo cual se presenta una lista de los nombres de los documentos encontrados. El usuario puede abrir cualquiera de los documentos encontrados y, si el sistema de búsqueda lo permite, las apariciones de las palabras buscadas en el documento se resaltan - "resaltadas". Se pueden distinguir las siguientes características de la organización:
funcionamiento del sistema de información documental, distinguiéndolo de los sistemas de gestión de bases de datos de datos estructurados: – Los documentos pueden almacenarse en papel, soporte micrográfico o existir en formatos electrónicos. Los formatos micrográficos incluyen microfilmes, microfichas, diapositivas y otras microformas producidas por una variedad de cámaras de documentos. Los formatos electrónicos son aún más numerosos e incluyen documentos preparados en procesadores de texto, sistemas de correo electrónico y otros programas informáticos, imágenes digitalizadas de documentos escaneados, etc. Esto requiere el almacenamiento obligatorio tanto de copias electrónicas de los documentos como de sus originales en papel.
Si los documentos ocupan un gran volumen y no es posible emitir copias electrónicas completas para verlos o almacenarlos, se crean y almacenan direcciones de almacenamiento electrónico para dichos documentos.
La búsqueda se realiza encontrando un documento según dos principios: por
atributos del documento – fecha de creación, tamaño, autor, etc. y según su contenido(texto). Normalmente, la búsqueda del contenido de un documento se realiza de dos formas: por palabras clave y en todo el texto, lo que se denomina texto completo, enfatizando así que para la búsqueda se utiliza todo el texto del documento, y no solo sus detalles.
Para buscar documentos, se crean y almacenan sus imágenes de búsqueda. . Buscar imagen de documento (SID) – un conjunto de códigos de palabras clave principales (descriptores) que describen el significado y el contenido del documento.
Las palabras clave y sus códigos se almacenan en un diccionario especial. tesauro.
Para buscar documentos, debe crear lenguaje de recuperación de información (IRL), que incluye un diccionario de sinónimos y una gramática del idioma, es decir un conjunto de reglas para especificar un conjunto de declaraciones sobre un conjunto de palabras clave.
Para encontrar un documento, debe crearlo utilizando IPA. imagen de consulta de búsqueda (POZ), que es un conjunto de palabras clave codificadas que describen los documentos que deben encontrarse.
El diagrama de interacción de los componentes IPS se muestra en la Fig. 1.
Arroz. 1. Esquema de interacción entre componentes IPS.
El IPS consta de los siguientes subsistemas de soporte:
Apoyo lingüístico, que incluye un lenguaje de recuperación de información;
Apoyo técnico sistemas, incluidos ordenadores y dispositivos para crear, almacenar, leer y reproducir copias en papel, en microformatos y en formulario electrónico;
Soporte de información compuesto por una base de datos de documentos (DB Doc.), direcciones (DB Adr.) y una base de datos de imágenes de búsqueda de documentos (DB DB) y listas de descriptores y sus códigos - tesauro;
El software IPS está diseñado para automatizar las siguientes funciones principales que debe realizar este sistema:
Compilación, codificación y carga de la base de datos AML;
Cargando una base de datos de documentos y sus direcciones de almacenamiento;
Elaboración, codificación de POS;
Realizar una operación de búsqueda y emitir una respuesta a una solicitud en forma de documento o direcciones de almacenamiento de documentos en una pantalla de computadora, en papel, en un archivo;
Actualización de bases de datos, documentos y direcciones ALD;
Actualización del tesauro;
Emisión de certificados.
Consideremos los conceptos básicos utilizados en el campo de la búsqueda de documentos.
Relevancia - grado de correspondencia del documento encontrado con la solicitud . Un documento encontrado mediante solicitud puede estar relacionado con la solicitud, es decir, contener la información necesaria (solicitada), o puede no tener ninguna relación. En el primer caso, el documento se llama importante(en inglés relevante - "importante"), en el segundo - irrelevante, o ruido. Como regla general, en cualquier motor de búsqueda, previa solicitud, se devuelven varios (generalmente muchos) documentos encontrados. Es posible que muchos de ellos estén contando la historia equivocada. Por el contrario, es posible que durante la búsqueda se pierdan algunos documentos importantes y relevantes. Está claro que la cantidad de ambos determina la calidad de la búsqueda, que puede determinarse con bastante precisión. Los conceptos principales en el mundo de las herramientas de búsqueda son las ideas de precisión e integridad de la búsqueda.
Precisión de búsqueda (T) está determinado por qué parte de la información devuelta en respuesta a la solicitud es relevante, es decir relacionado con esta consulta y es un parámetro que muestra cuál es la proporción de documentos relevantes en el número total de documentos encontrados. Este indicador se calcula mediante la fórmula:

Si, por ejemplo, todos los documentos emitidos a pedido son relevantes para el caso, entonces la precisión es del 100%; si, por el contrario, todos los documentos tienen ruido, entonces la precisión de la búsqueda es cero.
Completitud de la búsqueda (P)- un parámetro adicional que muestra cuál es la proporción (o porcentaje) de documentos relevantes que se encuentran en el número total de documentos relevantes, es decir caracterizado por la relación entre todos información relevante, disponible en la base de datos, y aquella parte de la misma que se incluye en la respuesta y se calcula mediante la fórmula:

Si en el área de búsqueda hay realmente 100 documentos que contienen la información necesaria y la consulta solo encontró 30 de ellos, entonces la integridad de la búsqueda es del 30%. Además, al evaluar los motores de búsqueda, se tiene en cuenta con qué tipos de datos puede trabajar un sistema en particular, en qué forma se presentan los resultados de la búsqueda y qué nivel de capacitación del usuario se requiere para trabajar en este sistema. Cabe señalar que la precisión de la búsqueda y su integridad dependen no solo de las propiedades del sistema de búsqueda, sino también de la correcta construcción. solicitud específica, así como de la idea subjetiva que tiene el usuario de qué información necesita. Si surge el problema de evaluar varios sistemas y elegir el más efectivo, puede calcular los valores promedio de integridad y precisión de los sistemas específicos en consideración probándolos en una base de datos de documentos de referencia.
Indexación documentos (es decir, elaboración de AML), lo que significa preparación preliminar textos para búsqueda y se utiliza principalmente para acelerar la búsqueda; Como regla general, las bases de datos de texto destinadas a búsquedas repetidas se procesan de antemano, creando los llamados índice(BAJO ) . Al indexar, el sistema de búsqueda compila listas de palabras encontradas en el texto y asigna a cada palabra su código: coordenadas en el texto (generalmente el número de documento y el número de palabra en el documento). Al buscar, la palabra se busca en el índice y, según las coordenadas encontradas, documentos necesarios. Si hay varias palabras en la consulta, se realiza una operación de intersección en sus coordenadas. . Si se reponen muchos documentos, también se debe reponer el índice.
Unidad de búsqueda- se trata de una cantidad de texto dentro del cual se realiza una búsqueda en un motor de búsqueda determinado, cuyo valor determina el indicador de precisión de la búsqueda, la cantidad de ruido y el tiempo de respuesta a una solicitud. La unidad de búsqueda puede ser un documento, una oración o un párrafo. En la tecnología de uso de IPS, se pueden distinguir tres grupos de operaciones:
Operaciones relacionadas con la obtención de imágenes de búsqueda de documentos (SID) que describen el contenido de los documentos y su carga en la base de datos (SID DB), así como la carga de los propios documentos o sus direcciones de almacenamiento en BDDoc y BDAdr.;
Operaciones de compilación de imágenes de consultas de búsqueda (SQI) utilizando un diccionario de sinónimos, búsqueda y emisión de resultados para visualización y selección de un archivo o impresión de documentos encontrados o una lista de direcciones;
Operaciones de mantenimiento de un sistema de recuperación de información, incluida la actualización de la base de datos de POD, BDDDoc., BDAdr. y tesauros debido a la aparición y necesidad de reponer la memoria del sistema con nuevos documentos o palabras clave. Las operaciones de mantenimiento de una IPS también incluyen el procedimiento de emisión de certificados sobre el funcionamiento del sistema, su estructura, métodos de búsqueda y clases y tipos de documentos almacenados u1076.
Tan pronto como el paquete llegue a uno de nuestros almacenes en el extranjero o en Rusia, recibirás una notificación por correo electrónico. En el futuro, podrá rastrear su paquete en nuestro sitio web en la sección "Seguimiento" para ello, deberá ingresar su número de seguimiento.
Asegúrese de haber ingresado su dirección postal correctamente en su perfil IPS y de que su bandeja de entrada de correo electrónico no esté llena.
Si tu vendedor (tienda online) te ha informado que tu paquete ha llegado a una de nuestras oficinas, pero aún no puedes rastrearlo, por favor contáctanos, si es posible, proporcionando información completa sobre su paquete (nombre de la tienda, remitente y dirección de envío, número de identificación, fecha de salida, etc.).
- Quiere recibir uno o dos paquetes por ahora:
- Tiene previsto recibir periódicamente (varias veces al mes) cartas, revistas o paquetes del extranjero:
- Las tarifas de nuestros servicios para nuestros clientes habituales son entre un 10% y un 30% más bajas que las tarifas para clientes no habituales (dependiendo del tipo de servicio).
- Las tarifas para la entrega de paquetes desde el extranjero se calculan de acuerdo con el peso real del paquete y no sobre el peso redondeado al número total de kilogramos.
- Se aplican descuentos acumulativos.
- El embalaje y reenvasado de cartas/paquetes para nuestros clientes habituales es gratuito.
- Para clientes habituales, las cartas/paquetes se entregan o reenvían desde nuestro direcciones extranjeras a cualquier otra dirección internacional o en manos de cualquier persona en el extranjero.
- Un cliente habitual recibe información sobre todos los cambios con antelación.
- Un cliente habitual puede solicitar el servicio no estándar que necesita, incluso si este servicio no está indicado en la lista de servicios de IPS y debe realizarse fuera de Rusia.
- Almacenamiento gratuito a largo plazo de cartas/paquetes en nuestras oficinas en el extranjero.
- Recoja sus paquetes usted mismo en nuestras oficinas en el extranjero.
-
¿Puedo utilizar un buzón de correo suscrito en su oficina para recibir correo ordinario, correspondencia, facturas, suscripciones de Moscú o Rusia?
Ciertamente. Nuestra tarifa de suscripción es más barata que la del Correo Ruso. En este caso, aparte de la cuota de suscripción, no pagas nada más.
Necesito enviar un paquete al extranjero. ¿En qué se diferencian los servicios de envío de IPS de otras empresas de mensajería?
- A través de nosotros, el cliente puede realizar envíos en 3 modalidades:
- modo postal: el más barato, pero también el más lento: de 10 a 12 días hábiles;
- modo mensajería velocidad promedio entrega – 4-5 días laborables (Express Smart);
- modo mensajería velocidad máxima entrega - 1-2 días hábiles (negocio Express).
- Preparamos de forma independiente todos los documentos aduaneros para el cliente.
- Brindamos consulta gratuita sobre cómo optimizar el proceso logístico de envío de cualquier carga a cualquier país del mundo.
- A través de nosotros, el cliente puede realizar envíos en 3 modalidades:
-
Tengo 4 paquetes pequeños. ¿Puedes empaquetar estos paquetes en uno?
Podemos. Proporcionaremos consolidación de paquetes. Para clientes habituales (suscriptores de buzones de correo), este servicio es gratuito.
¿Cómo puedo pagar la entrega?
En en este momento Hay disponibles métodos de pago en efectivo y sin efectivo.
¿Qué compensación me pagarán si mi paquete se pierde?
Nuestra entrega tiene alto grado fiabilidad. Sin embargo, si esto sucediera y el paquete estuviera asegurado, el importe asegurado total.
¿Cuánto tiempo se tarda en entregar un paquete?
La entrega suele tardar entre 7 y 12 días a partir de la fecha en que el paquete llega a nuestro almacén en el país respectivo.
¿Puedo almacenar mi paquete en su almacén en EE. UU./Reino Unido/Alemania durante 1 o 2 meses? ¿Hay un cargo adicional por esto?
Si no se suscribe a un buzón, IPS almacenará su paquete de forma gratuita solo durante 7 días a partir de la fecha de recepción en el almacén. Si el paquete se almacena durante más de 7 días, se cobrará una tarifa adicional. IPS se reserva el derecho, a su discreción, de disponer de los paquetes que se encuentren almacenados en un almacén durante más de 60 días y cuyos propietarios no hayan pagado el almacenamiento.
¿Cuáles son los beneficios de realizar envíos con IPS?
Ventajas de la entrega con IPS:
- confiabilidad de la entrega;
- costos de envío razonables y comprensibles;
- El tiempo de entrega es de 7 a 12 días;
- presencia de una oficina en Moscú donde siempre están dispuestos a ayudar;
- la posibilidad de comprar bienes que no están disponibles en Rusia;
- la posibilidad de comprar productos en tiendas que no entregan productos a Rusia;
- la oportunidad de ahorrar en la entrega utilizando el servicio de consolidación y reembalaje de envíos.
-
¿Qué información debo indicar en el campo “Dirección de entrega” al comprar productos en tiendas online?
Debe ingresar: la dirección de nuestra oficina en el extranjero que le proporcionó nuestra empresa, su apellido y nombre, su número de buzón.
¿Debo decirles algo después de realizar una compra y enviar el paquete a la dirección que me proporcionaron?
Después de realizar un pedido, debe informarnos sobre el pedido completado, proporcionar los datos del pedido: descripción del archivo adjunto, su peso y costo. Esta información es necesaria para procesar sus paquetes.
¿Existen restricciones a posibles inversiones?
Con IPS puedes enviar un paquete con cualquier archivo adjunto no prohibido por la ley Federación Rusa.
Las inversiones prohibidas incluyen:
- explosivos,
- artículos inflamables,
- materiales radioactivos,
- gas comprimido,
- armas de fuego,
- cualquier artículo que, por la naturaleza del embalaje, pueda causar lesiones al personal de IPS o causar daños a otros artículos.
Puede encontrar una lista completa de archivos adjuntos prohibidos.
Antes de realizar una compra en una tienda online, asegúrese de que su compra no entre en la categoría de mercancías peligrosas.
¿IPS garantiza la autenticidad y calidad del producto que compro?
IPS no es responsable ante el cliente de la autenticidad y calidad de los bienes adquiridos por él. Por su propia seguridad, compre productos únicamente en tiendas en línea de confianza.
¿Cómo empaquetar un paquete correctamente?
Sin embargo, si es necesario, asegúrese de que su paquete esté correctamente embalado o informe a IPS que se requiere embalaje adicional para su paquete.
No somos responsables de ninguna pérdida o daño que pueda ocurrir durante la manipulación, transporte o entrega debido a un embalaje inadecuado por parte del remitente.
¿Qué documentos se deben proporcionar para confirmar el costo de envío estimado?
Se debe proporcionar una factura preparada por el remitente y los montos indicados deben incluir todos los impuestos, así como todos los demás cargos posibles.
¿En qué tiendas online puedo comprar?
¿Qué debo hacer si el vendedor envió el artículo o la cantidad incorrecta?
Dado que la empresa IPS sólo entrega su paquete a Rusia, todas las cuestiones relativas al embalaje y la conformidad de la mercancía, así como a la posibilidad de cambio o devolución, deben resolverse directamente con el vendedor o remitente.
Quiero comprar joyas hechas de metales preciosos con piedras preciosas. ¿Es esto posible?
No. No entregamos artículos fabricados con metales preciosos y/o piedras preciosas.
¿Cuándo sabré el coste final de envío?
Sólo después de que el paquete llegue a nuestro almacén extranjero elegido por usted.
Una vez que su paquete haya sido procesado, se le notificará por correo electrónico sobre los tiempos de entrega y los costos de envío finales. Su paquete será asignado numero personal, puede seguir las instrucciones de la carta para pagar el costo de envío y rastrear el estado de su envío.
Si desea consolidar su envío, deberá realizar el pago después de la formación final del paquete.
Un cliente que se suscribe a un buzón no necesita realizar ningún pago antes de recibir su correspondencia/paquetes en la oficina del IPS de Moscú.
Si decido rechazar la entrega a Rusia de un paquete que llegó a mi nombre a una oficina de IPS en el extranjero, ¿se me retendrá algún importe si es necesario devolver el paquete al remitente o destruirlo?
Si por algún motivo decide suspender la entrega de su paquete a Rusia, hable inmediatamente con su remitente para que no envíe su paquete a la dirección IPS.
Si el paquete llega a la dirección del almacén de IPS, podemos, según sus indicaciones, devolver el paquete (o reenviarlo a otra dirección) con una tarifa administrativa de $10, así como el 100% del costo de devolución/entrega del paquete. .
También podemos disponer del paquete con una deducción de 10 $ en concepto de gastos administrativos (para paquetes que no excedan los 15 kg). Si un paquete se almacena por más de 21 días, IPS cobrará una tarifa de $0.50 por día por paquete.
¿Cuál es el peso mínimo a pagar de un paquete entregado?
Para clientes de buzón de correo: el peso mínimo cobrable es 1 libra, seguido de incrementos de 0,1 libra.
Entrega de paquetes desde el extranjero. ¿Cómo funciona esto?
Proporcionamos a todos nuestros clientes (ya sean clientes habituales o clientes que desean recibir un paquete una sola vez) direcciones postales en tres ciudades de todo el mundo: Londres, Nueva York y Hannover. A cualquiera de ellos, tu interlocutor (tienda online, amigo, familiar, colega, etc.) puede enviarte un paquete y entre 7 y 10 días hábiles después de su llegada a una de estas direcciones, lo recibirás en Moscú.
¿Cómo puedo obtener direcciones?
Hay dos opciones:
Necesitas venir con tu pasaporte a oficina de IPS. Aquí te harán una fotocopia de tu pasaporte y anotarán tu numeros de contacto y te dará la dirección que necesitas (en Londres, Nueva York o Hannover).
Tiene sentido que usted celebre un acuerdo de servicio permanente. Para hacer esto, debe suscribirse a un buzón y realizar un pago de suscripción periódicamente. Tamaño mínimo mensual tarifa de suscripción– 755,2 rublos (IVA incluido 18%). (Existen otras tarifas de suscripción, dependen del conjunto de servicios gratuitos adicionales ya incluidos en el servicio de suscripción). En este caso, recibirá las tres direcciones y podrá utilizarlas a su discreción.
Para obtener una dirección, ¿no puedo acudir a usted y enviarle una copia de mi pasaporte por correo electrónico?
Puedes, pero luego necesitas un pago por adelantado.
En los dos casos anteriores (ver pregunta 2), atendemos a los clientes en efectivo contra reembolso: entregamos (es decir, primero brindamos el servicio) y luego solo recibimos el pago del cliente. Por lo tanto, es importante para nosotros asegurarnos de que nuestro cliente sea una persona real.
Si desea enviarnos una copia de su pasaporte electrónicamente, entonces es importante que realice un pago por adelantado de al menos 4000,0 rublos para poder seguir brindando servicios. Si después de proporcionar y pagar el servicio de entrega aún le queda un monto, en su primera solicitud, este monto le será devuelto a los detalles desde donde nos lo envió. O en el futuro podrás utilizarlo para pagar servicios en nuestra empresa.
¿Por qué es beneficioso suscribirse a un buzón?
Un cliente que se suscribe a un buzón se convierte en nuestro cliente habitual.
Los clientes habituales tienen los siguientes beneficios:
Buenas tardes, mis queridos lectores. Hoy tocaremos un tema extremadamente interesante e importante: los sistemas de recuperación de información. La capacidad de trabajar con ellos correctamente, el conocimiento de los conceptos básicos y los principios operativos ayudarán a los usuarios novatos a aprender a buscar de forma rápida y eficaz. información diversa en línea, obtenga los datos necesarios y desarrolle rápidamente su negocio en línea.
En este artículo hablaré sobre la historia de la creación de los sistemas de búsqueda, los principios de su funcionamiento y estructura. Además, me detendré en características muy importantes que debes conocer cuando trabajas con IPS.
Entonces, estudiemos con más detalle qué es IPS y qué componentes se incluyen en su composición.
Sistemas de recuperación de información (IRS) y sus tipos.
Este concepto surgió allá por finales de los 80 y principios de los 90 del siglo pasado. Fue entonces cuando surgieron sus primeros prototipos, tanto en Rusia como en el extranjero. Según la definición, es un sistema que permite buscar, procesar y seleccionar los datos requeridos de la solicitud en su propia base de datos especial, que contiene descripciones de diversas fuentes de información, así como reglas para su uso.
Su tarea principal es buscar requerido por el usuario información. Para hacerlo más efectivo, se utiliza el concepto de relevancia, es decir, la precisión con la que los resultados de la búsqueda coinciden con una consulta en particular.
Los principales tipos de IPS incluyen los siguientes conceptos:
La indexación del catálogo se puede realizar de forma manual o automática con la actualización del índice. A su vez, el resultado del funcionamiento del sistema incluye una lista especial. Incluye un hipervínculo a los recursos requeridos y una descripción de un documento particular en Internet.
Los catálogos más populares incluyen: yahoo, Magallanes(extranjero) yLista web, Caracol y @Rusia de los domésticos.

Los sistemas de recuperación de información extranjeros más comunes incluyen Google, Altavista, Excite. Rusos: Yandex y Rambler.
- En el mundo existe una gran cantidad de tipos diferentes de sistemas de información que contienen muchas fuentes de información. Por supuesto, incluso la presencia de los más modernos y servidor potente no puede satisfacer las necesidades de millones de usuarios. Por eso especial Metabuscadores. Pueden reenviar simultáneamente las solicitudes de los usuarios a varios servidores de búsqueda y, basándose en su generalización, pueden proporcionar al usuario un documento que contiene enlaces al recurso requerido. Estos incluyen MetaCrawler o SavvySearch.
Historia de la creación de la IPS.
El primer IPS apareció a mediados de los años 90 del siglo XX. Se parecían mucho a los índices habituales que se encuentran en cualquier libro, una especie de libros de referencia. Su base de datos contenía palabras clave especiales (palabras) que de varias maneras recopilados de numerosos sitios. Como las tecnologías de Internet no eran perfectas, la búsqueda en sí se realizaba únicamente mediante palabras clave.
Mucho más tarde, se desarrolló una búsqueda especial de texto completo para que al usuario le resultara más fácil encontrar la información que necesitaba. El sistema registró palabras clave. Gracias a él, los usuarios podrían realizar las consultas necesarias sobre determinadas palabras y diversas frases.

Uno de los primeros fue Wandex. Estuve muy involucrado en su desarrollo. programador famoso Matthew Graham en 1993. Además, ese mismo año apareció una nueva "búsqueda" "Aliweb" (por cierto, todavía funciona con éxito hasta el día de hoy). Sin embargo, todos tenían una estructura bastante compleja y no contaban con tecnologías modernas.
Uno de los más exitosos fue WebCrawler, que se lanzó por primera vez en 1994. rasgo distintivo y la principal ventaja que lo diferencia de otros motores de búsqueda es que puede encontrar cualquier palabra clave en una página determinada. Después de esto, se convirtió en una especie de estándar para todos los demás IPS que se desarrollaron posteriormente.
Mucho más tarde surgieron otros motores de búsqueda, que en ocasiones competían entre sí. Estos fueron Excite, AltaVista, InfoSeek, Inktomi y muchos otros. Desde 1996, los internautas rusos comenzaron a trabajar con Rambler y Aport. Pero, un verdadero triunfo para internet ruso, se convirtió en Yandex, creado en 1997.
Este análogo ruso de Google se ha convertido en un verdadero orgullo de los programadores rusos. Hoy en día, está superando con confianza a su competidor en RuNet y también es uno de los líderes en consultas de búsqueda entre los IPS en Rusia.
Hoy en día, existen numerosos "motores de búsqueda" especiales que se crean para resolver problemas específicos. Por ejemplo, el sistema de información y recuperación "Patron" fue diseñado para almacenar y buscar datos sobre cartuchos de diversas armas y ahora lo utilizan tanto el Ministerio del Interior y los servicios de inteligencia como los cazadores profesionales y aficionados.
Hay otros pensados para notarios, médicos, ingenieros, militares, aficionados a los coches, etc.
¿Cómo funciona IPS?

El trabajo de un sistema de recuperación de información es muy complejo. Sin embargo, si lo deseas, puedes comprender su estructura. Lo primero que hay que tener en cuenta es que existe un programa especial: se llama robot de búsqueda (araña). Este programa monitorea sistemáticamente varias páginas y las indexa.
El servidor web crea una solicitud de usuario para recibir tal o cual información y luego proporciona esta solicitud máquina de búsqueda. El motor de búsqueda examina la base de datos requerida y luego compila lista completa páginas y luego lo envía al servidor web. Éste, a su vez, finalmente convierte todos los resultados de la consulta en un formato "legible" y luego los transfiere a la "computadora" del usuario.
IPS está destinado a los siguientes fines:
- Almacenar cantidades significativas de datos;
- Realizar una búsqueda rápida de la información necesaria;
- Agregar y eliminar varios datos;
- Muestre información de una forma sencilla y cómoda.
Hay varios tipos principales de IPS:
- Automatizado
- Bibliográfico
- Conversacional
- Documental
¿Qué motores de búsqueda son los más populares hoy en día?

En primer lugar, sin lugar a dudas, está el líder indiscutible: Google. Hoy en día, a él se dirigen alrededor del 80 por ciento de las diversas solicitudes del mundo en los más diversos ámbitos. En cuanto al segundo lugar, también lo ocupa merecidamente la estadounidense eBay.
En tercer lugar está nuestro “Yandex” ruso y nacional. En cuarto lugar está Yahoo y en quinto lugar está MSN. Otro navegador nacional, pero que ocupa sólo el décimo lugar en el ranking europeo, es el ruso "Rambler".
Este motor de búsqueda es conocido por una gran cantidad de usuarios. ¡Hoy es el primer sistema más popular del mundo! Procesa más de 41 mil millones de consultas mensuales e indexa 25 mil millones de páginas.
En cuanto a la historia de la creación de Google, allá por 1996, un par de estudiantes de la Universidad de Stanford, Larry Page y Sergey Brin, desarrollaron un navegador basado en nuevos métodos de búsqueda. Lo llamaron de forma sencilla y concisa, igual que el diseño del buscador Google. De hecho nombre de google es un googol distorsionado (el número diez elevado a la centésima potencia).

Se basa en un especial robot de búsqueda, que se llama "Googlebot". Escanea páginas y las indexa. Como algoritmo de autoridad, este PS. De hecho, es él quien garantiza cómo se mostrarán las páginas al visitante en los resultados de búsqueda.
Uno de los primeros que desarrolló esta empresa y en varios idiomas, lo que facilita enormemente la entrada de datos al sistema. Bueno, y finalmente, sirvió de base para la palabra "google", que se encuentra cada vez más en la jerga de los jóvenes adolescentes.
« yahoo» - el segundo más popular en EE. UU. Fue fundada en 1994 por dos estudiantes graduados de Stanford, David Filo y Jerry Yang. A finales de los 90 adquirieron el portal RocketMail y en base a él crearon el servidor de correo gratuito Yahoo. Hoy en día, puedes almacenar cualquier cantidad de correos electrónicos en sus servidores. En 2010, apareció un recurso de correo en ruso: Yahoo! Correo.
yandex
Uno de los mejores buscadores rusos, sin duda, es Yandex. Hoy ocupa el cuarto lugar en cuanto al número total de solicitudes. Al mismo tiempo, en términos de popularidad, Yandex hoy ocupa el primer lugar en la Federación de Rusia. El número total de consultas generadas supera los 250 millones cada día
Se introdujo en septiembre de 1997 y ya en mayo de 2011, al colocar sus acciones en una oferta pública inicial, esta empresa logró obtener el mayor número de acciones entre otras empresas de Internet.

Hoy en día, Yandex tiene 50 servicios, algunos de los cuales son únicos: Yandex.Search, Yandex.Maps, Yandex.Market. Además, los usuarios rusos están muy interesados en servicios como "Búsqueda de blogs" y "Tráfico Yandex". Consultas básicas para usuarios principalmente de los siguientes países vecinos: Rusia, Bielorrusia, Türkiye y Kazajstán.
Históricamente, la empresa fue fundada por el empresario y programador Arkady Volozh en 1989. El nombre de la empresa fue inventado por Ilya Segalovich, director de Yandex. Gracias a la cooperación con el Instituto para Problemas de Transmisión de Información, se creó un diccionario de referencia con capacidad de búsqueda.
A diferencia de otros navegadores, también tiene en cuenta la morfología del idioma ruso. Por lo tanto, el sistema en sí está diseñado específicamente para funcionar en el segmento de Internet de habla rusa.
Desde 2010, además del navegador Yandex.ru, apareció otro motor de búsqueda: Yandex.com. Este recurso de Internet se utiliza para buscar en portales extranjeros.
Motor de búsqueda "Ebay»
Ebay es una empresa de Internet de Estados Unidos que se especializa en realizar subastas en línea. Gestiona el portal eBay.com, así como versiones en otros países del mundo. Además, la empresa posee otra empresa eBay.

El fundador de la empresa es el programador estadounidense Pierre Omidyar, quien a mediados de los años 90 desarrolló una subasta online para su portal personal. Al mismo tiempo, eBay es una especie de intermediario en la compra y venta. Para utilizarlo, los vendedores hacen una determinada contribución y los compradores tienen la oportunidad. uso gratuito sitio.
Los principios generales de su funcionamiento son los siguientes:
- Básicamente todas las personas son decentes.
- Todos pueden contribuir
- EN comunicación abierta la gente muestra sus mejores cualidades
Ya en 1995 se vendieron millones de artículos diferentes en miles de subastas en línea. Hoy en día es una poderosa plataforma de compra y venta, tanto por parte de personas físicas como jurídicas.
Desde 2010, apareció una versión en ruso del popular recurso, que comenzó a llamarse "Centro de Comercio Internacional eBay". El pago en la subasta se realiza a través de sistema de pago"PayPal".
Para vender artículos en este portal debe escribir cuánto cuesta, su precio inicial, cuándo comenzará la subasta y también cuánto durará la subasta. Como en una subasta normal, el mejor postor se queda con el artículo seleccionado.
Una de las ventajas de dicha subasta es que el vendedor y el comprador pueden ubicarse en cualquier lugar. globo, y la presencia de sucursales locales y plazos brindan la oportunidad de participar en subastas para una gran cantidad de vendedores y compradores.

Este motor de búsqueda es un navegador de Internet líder desarrollado por Microsoft. Apareció simultáneamente con el lanzamiento del primer Sistema operativo Windows 95. Posteriormente este nombre empezó a ser utilizado por el servicio electrónico. hotmail, así como varios sitios web de Microsoft. A principios de 2002, era uno de los más importante internet– proveedores en EE. UU. y tenía 9 millones de suscriptores.
motor de búsquedaExcursionista
el segundo mas grande motor de búsqueda ruso, es el portal de Internet “Rambler”. En esencia, junto con Yandex, es el fundador de Runet, así como el principal actor en el mercado de servicios de medios.
Su fundador es Sergei Lysakov, quien en 1994 desarrolló motor de búsqueda, y en 1996 se registró el dominio www.rambler.ru. Desde 2012, Rambler comenzó a funcionar como portal de noticias.
Hoy ocupa el puesto 11 en popularidad entre otros sitios rusos. Además, se desarrolló un clasificador especial Rambler Top-100. De hecho, fue el primero en Rusia. hoy es catálogo conveniente objetos inmobiliarios "Rambler - bienes raíces".
motor de búsquedacorreo

Uno de los más grandes servicios postales Apareció, creado en 1998, Mail.ru. Hoy es un servicio de correo electrónico, un catálogo de recursos de Internet y secciones de información. además muy correo conveniente, tiene una serie de proyectos especiales que son muy populares y necesarios para los suscriptores: “Auto Mail.ru”, Poster “Mail.ru”, “Children of mail.ru”, “Health mail.ru”, “Lady mail. ru”, “ Noticias mail.ru" y "Inmobiliaria mail.ru".
Para los aficionados a los deportes y la alta tecnología existen secciones correspondientes.
Con esto concluye mi material. Si te gustó, suscríbete a mi blog e invita a tus familiares, amigos y conocidos.
(Aún no hay valoraciones)
Leer: 469 veces
En este artículo me gustaría considerar varias técnicas busque información sobre dispositivos VoIP en la red y luego demuestre varios ataques a VoIP.
Introducción
En los últimos años se ha visto una rápida adopción de VoIP (VoIP). La mayoría de las organizaciones que han implementado VoIP ignoran los problemas de implementación y seguridad de VoIP o simplemente los desconocen. Como cualquier otra red, una red VoIP es susceptible de sufrir un mal uso. En este artículo, me gustaría analizar varias técnicas para encontrar información sobre dispositivos VoIP en la red y luego demostrar varios ataques a VoIP. Deliberadamente no profundicé en los detalles del nivel de protocolo, ya que este artículo está destinado a pentesters que desean probar las técnicas básicas primero. Sin embargo, recomiendo encarecidamente conocer los protocolos utilizados en las redes VoIP.
Posibles ataques a VoIP
- Denegación de servicio (DoS)
- Robar y manipular datos de registro
- Ataques al sistema de autenticación
- Sustitución (suplantación de identidad) Identificador de llamadas
- Ataques de intermediario
- "Chamanismo sobre VLAN" (salto de VLAN)
- Pasivo y escucha activa
- Spam a través de telefonía por Internet (SPIT)
- Phishing de VoIP (Vishing)
Configuración del laboratorio de pruebas de VoIP
Para demostrar los problemas de seguridad de VoIP a los efectos de este artículo, utilicé la siguiente configuración de laboratorio:
- Trixbox i(192.168.1.6) - Servidor IP-PBX con abierto código fuente
- Backtrack 4 R2 (192.168.1.4): sistema operativo en la máquina del atacante
- ZoIPer ii (192.168.1.3) - softphone para Windows (usuario A- víctima)
- teléfono III(192.168.1.8) - softphone para Windows (usuario B- víctima)
Nuestra configuración de laboratorio

Figura 1
Considere el diagrama de laboratorio presentado arriba. Esta es una configuración de red VoIP típica. pequeña organización con un enrutador que asigna direcciones IP a dispositivos, sistema IP-PBX y usuarios. Si el usuario A esta red quisiera contactar B, sucederá lo siguiente:
- Llamar A enviado al servidor IP-PBX para la autenticación del usuario.
- Después de una autenticación exitosa A El servidor IP-PBX comprueba la presencia de la extensión ( numero interno) usuario B. Si la extensión está presente, la llamada se redirige B.
- Basado en la respuesta B(por ejemplo, aceptar una llamada, colgar, etc.) El servidor IP-PBX responde al usuario A.
- si todo esta bien A comienza a comunicarse con B.
Ahora que tenemos una idea clara de la interacción, pasemos a la parte divertida: los ataques VoIP.
Buscar dispositivos VoIP
La enumeración es la base de todo ataque/pentest exitoso, ya que proporciona al atacante tanto los detalles necesarios como una idea general de la configuración de la red. VoIP no es una excepción. En una red VoIP, la información sobre puertas de enlace/servidores VoIP, sistemas IP-PBX, software de cliente y teléfonos VoIP y números de usuario (extensiones) nos será útil como atacantes. Echemos un vistazo a algunas herramientas de uso común para buscar dispositivos y crear huellas digitales. Para simplificar la demostración, supongamos que ya conocemos las direcciones IP de los dispositivos.
pequeño mapa
pequeño mapa IV exploraciones dirección IP separada o subred para dispositivos SIP habilitados. Usemos smap contra un servidor IP-PBX. La Figura 2 muestra que pudimos encontrar el servidor y obtener su información de Agente de Usuario.

Figura 2
Svmapa
Svmap - otro potente escáner del kit de herramientas sipviciosas v. Esta herramienta le permite configurar el tipo de solicitud utilizada al buscar dispositivos SIP. El tipo de solicitud predeterminado es OPCIONES. Ejecutemos un escáner para un grupo de 20 direcciones. Como puede ver, svmap puede detectar direcciones IP e información de usuario-agente.

Figura 3
Swar
Al buscar dispositivos VoIP, la búsqueda por números de usuario puede ayudar a determinar qué extensiones SIP están activas. Suecia vi le permite escanear la gama completa de direcciones IP. La Figura 4 muestra el resultado de escanear números de usuario en el rango de 200 a 300. Como resultado, obtenemos extensiones de usuario registradas en el servidor IP-PBX.

Figura 4
Entonces, analizamos el proceso de búsqueda de dispositivos VoIP y obtuvimos algunos detalles de configuración interesantes. Ahora usemos esta información para atacar la red cuya configuración acabamos de examinar.
Ataque a VoIP
Como ya se mencionó, una red VoIP es susceptible a muchas amenazas y ataques a la seguridad. En este artículo, analizaremos tres ataques críticos a VoIP que pueden tener como objetivo comprometer la integridad y confidencialidad de la infraestructura de VoIP.
Los siguientes ataques se demuestran en las siguientes secciones:
- Ataque a la autenticación VoIP
- Escucha a través de suplantación de identidad ARP
- Simular identificador de llamadas
1. Ataque a la autenticación VoIP
Cuando un teléfono VoIP nuevo o existente se une a la red, envía una solicitud de REGISTRO al servidor IP-PBX para registrar la ID de usuario/extensión asociada con el teléfono. Esta solicitud de registro contiene información importante (como información del usuario, datos de autenticación, etc.) que podría ser de gran interés para un atacante o un probador de penetración. La Figura 5 muestra el paquete de solicitud de autenticación capturado. protocolo SIP. El paquete interceptado contiene información valiosa para el atacante. Usemos los datos del paquete para atacar la autenticación.

Figura 5
Demostración de ataque
Escenario de ataque
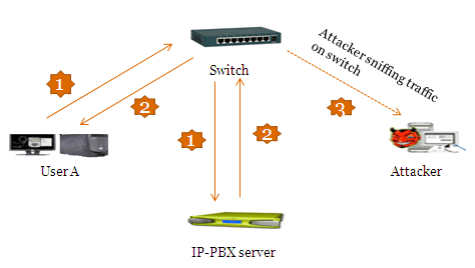
Figura 6
Paso 1: Para simplificar la demostración, supongamos que tenemos acceso físico a la red VoIP. Ahora, utilizando las herramientas y técnicas descritas en las secciones anteriores del artículo, escanearemos y buscaremos dispositivos para obtener la siguiente información:
- Dirección IP del servidor SIP
- ID de usuario y extensiones existentes
Paso 2: Interceptemos algunas solicitudes de registro usando Wirehark viii. Los guardaremos en un archivo llamado auth.pcap. La Figura 7 muestra el archivo wirehark con los resultados de la captura (auth.pcap).

Figura 7
Paso 3:
Ahora estamos usando el kit de herramientas sipcrack. viii. El conjunto es parte de Backtrack y está ubicado en el directorio /pentest/VoIP. La Figura 8 muestra las herramientas de la suite sipcrack.
Figura 8
Paso 4: Usando sipdump, volquemos los datos de autenticación en un archivo llamado auth.txt. La Figura 9 muestra un archivo de captura de Wirehark que contiene las credenciales de autenticación del usuario 200.

Figura 9
Paso 5: Estos datos de autenticación incluyen el ID de usuario, la extensión SIP, el hash de contraseña (MD5) y la dirección IP de la víctima. Ahora usamos sipcrack para descifrar hashes de contraseñas mediante un ataque de diccionario preparado. La Figura 10 muestra que el archivo wordlist.txt se utiliza como diccionario para descifrar hashes. Guardaremos los resultados del hack en un archivo llamado auth.txt.

Figura 10
Paso 6:¡Genial, ahora tenemos contraseñas para extensiones! Podemos utilizar esta información para volver a registrarnos en el servidor IP-PBX desde nuestro propio teléfono SIP. Esto nos permitirá hacer lo siguiente:
- Hacerse pasar por un usuario legítimo y llamar a otros suscriptores
- Escuchar y manipular llamadas legítimas salientes y entrantes a la extensión de la víctima (usuario) A en este caso).
2. Escuchar mediante suplantación de identidad Arp
Cada dispositivo de red tiene una dirección MAC única. Al igual que otros dispositivos de red, los teléfonos VoIP son vulnerables a la suplantación de MAC/ARP. EN esta sección Analizaremos cómo detectar llamadas de voz activas escuchando y grabando conversaciones actuales a través de VoIP.
Demostración de ataque
Escenario de ataque

Figura 11
Paso 1: Para fines de demostración, supongamos que ya hemos determinado la dirección IP de la víctima utilizando las técnicas descritas anteriormente. A continuación, usando ucsniff ix Como medio de suplantación de ARP, falsificaremos la dirección MAC de la víctima.
Paso 2: Es importante determinar la dirección MAC del objetivo que debe falsificarse. Aunque las herramientas mencionadas anteriormente pudieron determinar la dirección MAC automáticamente, es una buena práctica determinar la MAC de forma independiente, de forma separada. Usemos nmap para esto incógnita. La Figura 12 muestra los resultados del escaneo de la dirección IP de la víctima y la dirección MAC resultante.

Figura 12
Paso 3: Ahora que tenemos la dirección MAC de la víctima, usemos ucsniff para falsificar su MAC. ucsniff admite varios modos de suplantación de identidad (modo de observación, modo de estudio y modo MiTM, es decir, "man-in-the-middle"). Usemos el modo MiTM especificando la dirección IP de la víctima y la extensión SIP en un archivo llamado target.txt. Este modo garantiza que solo se monitoreen las llamadas (entrantes y salientes) de la víctima (usuario). A), sin afectar el resto del tráfico de la red. Las figuras 13 y 14 muestran que ucsniff ha falsificado la MAC del usuario. A(en la tabla ARP).

Figura 13

Figura 14
Paso 4: Hemos reemplazado con éxito la dirección MAC de la víctima y ahora estamos listos para escuchar las llamadas entrantes y salientes del usuario. A a través del teléfono VoIP.
Paso 5: Ahora que el usuario B llama al usuario A y comienza un diálogo, ucsniff comienza a grabar su conversación. Cuando finaliza la llamada, ucsniff guarda toda la conversación grabada en un archivo wav. La Figura 15 muestra que ucsniff detectó una nueva llamada desde la extensión 200 a la extensión 202.
Figura 15
Paso 6: Cuando terminamos, llamamos a ucsniff nuevamente con el parámetro -q para detener la suplantación de MAC en el sistema y así asegurarnos de que todo encaje en su lugar una vez que se complete el ataque.
Paso 7: El archivo de audio guardado se puede reproducir utilizando cualquier reproductor multimedia conocido como medios de windows jugador.
Falsificación del identificador de llamadas
Este es uno de los ataques más simples a las redes VoIP. La suplantación de identidad de suscriptor corresponde al escenario en el que usuario desconocido puede hacerse pasar por un usuario legítimo de la red VoIP. Para implementar este ataque, pueden ser suficientes cambios simples en la solicitud INVITE. Hay muchas maneras de generar distorsionados. de la manera correcta Mensajes SIP INVITE (usando scapy, SIPp, etc.). Para la demostración utilizamos el módulo auxiliar sip_invite_spoof del framework metasploit. xi .
Escenario de ataque

Figura 16
Paso 1: Ejecutemos metasploit y carguemos el módulo auxiliar voip/sip_invite_spoof.
Paso 2: A continuación, establezca el valor de la opción MSG en Usuario B. Esto nos dará la posibilidad de suplantar al usuario. B. Anotemos también la dirección IP del usuario. A en la opción RHOSTS. Después de configurar el módulo, lo lanzamos. La Figura 17 muestra todos los ajustes de configuración.

Figura 17
Paso 3: El módulo de ayuda enviará solicitudes de invitación modificadas a la víctima (usuario A). La víctima recibirá llamadas de mi teléfono VoIP y responderles, pensando que está hablando con el usuario B. La Figura 18 muestra el teléfono VoIP de la víctima ( A), que recibe una llamada supuestamente del usuario B(pero en realidad de mi parte).

Figura 18
Paso 4: Ahora A cree que fue una llamada normal de B y comienza a hablar con alguien que se presenta como Usuario B.
Conclusión
Muchos amenazas existentes La seguridad también se aplica a VoIP. Usando la búsqueda de dispositivos, puede obtener información crítica relacionada con la red VoIP, ID/extensiones de usuario, tipos de teléfonos, etc. Usando herramientas especiales, es posible llevar a cabo ataques a la autenticación, robar llamadas VoIP, espiar, manipular llamadas, enviar VoIP. - spam, realizar phishing VoIP y comprometer el servidor IP-PBX.
Espero que este artículo haya sido lo suficientemente informativo como para generar conciencia sobre los problemas de seguridad de VoIP. Me gustaría pedirles a los lectores que tengan en cuenta que este artículo no ha analizado todas las posibles herramientas y técnicas utilizadas para buscar dispositivos VoIP en la red y realizar pentesting.
Sobre el autor
Sohil Garg es pentester en PwC. Sus áreas de interés incluyen el desarrollo de nuevos vectores de ataque y pruebas de penetración en entornos seguros. Participa en evaluaciones de seguridad. varias aplicaciones. Ha presentado temas de seguridad de VoIP en conferencias CERT-In a las que asistieron altos funcionarios gubernamentales y de defensa. Recientemente descubrió una vulnerabilidad en el producto de una gran empresa que permite la escalada de privilegios y el acceso directo a un objeto.
Campo de golf
i http://fonality.com/trixbox/ii http://www.zoiper.com/
III http://www.linphone.org/
IV http://www.wormulon.net/files/pub/smap-blackhat.tar.gz
v
vi http://code.google.com/p/sipvicious/
viii http://www.wireshark.org/
viii Esta herramienta se puede encontrar en Backtrack 5 en el directorio /pentest/voip/sipcrack/.
ix http://ucsniff.sourceforge.net/
incógnita http://nmap.org/download.html
xi http://metasploit.com/download/



