Expresiones de tabla. Consultas complejas de bases de datos MySQL. Consultas simples de ACTUALIZACIÓN contra una base de datos MySQL
Expresiones de tabla llamadas subconsultas, que se utilizan donde se espera una tabla. Hay dos tipos de expresiones de tabla:
tablas derivadas;
Expresiones de tablas generalizadas.
Estas dos formas de expresiones de tabla se analizan en las siguientes subsecciones.
tablas derivadas
tabla derivada es una expresión de tabla incluida en la cláusula FROM de una consulta. Las tablas derivadas se pueden usar cuando no es posible usar alias de columna porque el traductor de SQL procesa otra declaración antes de que se conozca el alias. El siguiente ejemplo muestra un intento de usar un alias de columna en una situación en la que se procesa otra cláusula antes de que se conozca el alias:
UTILIZAR SampleDb; SELECCIONE MES (EnterDate) como enter_month FROM Works_on GROUP BY enter_month;
Intentar ejecutar esta consulta devolverá el siguiente mensaje de error:
Mensaje 207, Nivel 16, Estado 1, Línea 5 Nombre de columna no válido "enter_mes". (Mensaje 207: Nivel 16, Estado 1, Línea 5 Nombre de columna no válido enter_mes)
El motivo del error es que la cláusula GROUP BY se procesa antes de que se procese la lista correspondiente de la declaración SELECT, y el alias de la columna enter_month no se conoce cuando se procesa el grupo.
Este problema se puede resolver usando una vista que contenga la consulta anterior (sin la cláusula GROUP BY), porque la cláusula FROM se ejecuta antes que la cláusula GROUP BY:
UTILIZAR SampleDb; SELECCIONE enter_month FROM (SELECCIONE MES(EnterDate) as enter_month FROM Works_on) AS m GROUP BY enter_month;
El resultado de esta consulta será así:
Por lo general, una expresión de tabla se puede colocar en cualquier parte de una declaración SELECT donde pueda aparecer el nombre de la tabla. (El resultado de una expresión de tabla siempre es una tabla o, en casos especiales, una expresión). El siguiente ejemplo muestra el uso de una expresión de tabla en la lista de selección de una declaración SELECT:
El resultado de esta consulta es:

Expresiones de tablas genéricas
Expresión de tabla común (OTB) (CTE para abreviar) es una expresión de tabla con nombre compatible con el lenguaje Transact-SQL. Las expresiones de tabla comunes se utilizan en los siguientes dos tipos de consultas:
no recursivo;
recursivo
Estos dos tipos de solicitudes se analizan en las siguientes secciones.
Consultas OTB y no recursivas
La forma no recursiva de OTB se puede utilizar como alternativa a las tablas y vistas derivadas. Por lo general, OTB se define por CON cláusulas y una consulta adicional que hace referencia al nombre utilizado en la cláusula WITH. En Transact-SQL, el significado de la palabra clave WITH es ambiguo. Para evitar la ambigüedad, la instrucción que precede a la instrucción CON debe terminar con un punto y coma.
UTILICE AdventureWorks2012; SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue > (SELECT PROMEDIO(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") Y Flete > (SELECT PROMEDIO(TotalDue) FROM Sales.SalesOrderHeader WHERE AÑO(OrderDate) = "2005 ")/2.5;
La consulta de este ejemplo selecciona pedidos cuyos impuestos totales (TotalDue) son mayores que el promedio de todos los impuestos y cuyos cargos de flete (Freight) son mayores que el 40 % del promedio de impuestos. La propiedad principal de esta consulta es su voluminosidad, ya que la consulta anidada debe escribirse dos veces. Una forma posible de reducir el alcance de la construcción de consulta sería crear una vista que contenga una subconsulta. Pero esta solución es un poco complicada porque requiere que se cree la vista y luego se elimine una vez finalizada la consulta. El mejor enfoque sería crear un OTB. El siguiente ejemplo muestra el uso de OTB no recursivo, que acorta la definición de consulta anterior:
UTILICE AdventureWorks2012; WITH price_calc(year_2005) AS (SELECT PROMEDIO(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue > (SELECCIONE year_2005 FROM price_calc) AND Flete > (SELECT year_2005 FROM price_calc) /2,5;
La sintaxis de la cláusula WITH en consultas no recursivas es la siguiente:
El parámetro cte_name es el nombre OTB que define la tabla resultante y el parámetro column_list es la lista de columnas en la expresión de la tabla. (En el ejemplo anterior, OTB se llama price_calc y tiene una columna, year_2005.) El parámetro inner_query representa una instrucción SELECT que especifica el conjunto de resultados de la expresión de tabla correspondiente. La expresión de tabla definida se puede usar en la consulta externa. (La consulta externa del ejemplo anterior utiliza la columna precio_calculador de OTB y su columna año_2005 para simplificar la consulta anidada doble).
OTB y consultas recursivas
Esta sección presenta material de mayor complejidad. Por lo tanto, cuando lo lea por primera vez, se recomienda omitirlo y volver a él más tarde. Los OTB pueden ser recursivos porque los OTB pueden contener referencias a sí mismos. La sintaxis básica de OTB para una consulta recursiva se ve así:
Los parámetros cte_name y column_list tienen el mismo significado que en OTB para consultas no recursivas. El cuerpo de la cláusula WITH consta de dos consultas unidas por la instrucción UNIÓN TODOS. La primera consulta se llama solo una vez y comienza a acumular el resultado de la recursividad. El primer operando del operador UNION ALL no hace referencia a un OTB. Esta consulta se denomina consulta de referencia u origen.
La segunda consulta contiene un enlace a OTB y representa su parte recursiva. Debido a esto, se le llama miembro recursivo. En la primera llamada a la parte recursiva, la referencia OTB representa el resultado de la consulta de referencia. El miembro recursivo usa el resultado de la primera llamada a la consulta. Después de eso, el sistema vuelve a llamar a la parte recursiva. Una llamada a un miembro recursivo finaliza cuando una llamada anterior devuelve un conjunto de resultados vacío.
El operador UNION ALL une las filas que se han acumulado hasta el momento, así como las filas adicionales agregadas por la llamada actual al miembro recursivo. (La presencia del operador UNION ALL significa que las filas duplicadas no se eliminarán del resultado).
Finalmente, el parámetro outside_query define la consulta externa que usa OTB para obtener todas las llamadas a la unión de ambos miembros.
Para demostrar la forma recursiva de OTB, usamos una tabla Avión definida y completada con el código que se muestra en el siguiente ejemplo:
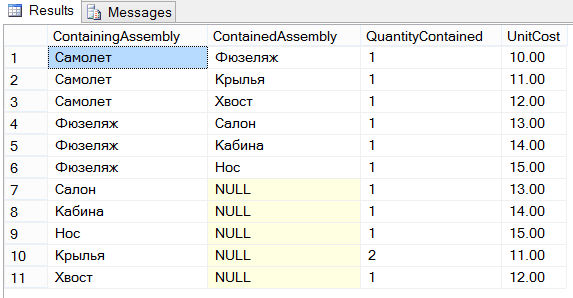
UTILIZAR SampleDb; CREATE TABLE Avión (ContainingAssembly VARCHAR(10), ContainedAssembly VARCHAR(10), CantidadContenida INT, UnitCost DECIMAL(6,2)); INSERTAR EN LOS VALORES del avión ("Avión", "Fuselaje", 1, 10); INSERTAR EN LOS VALORES del avión ("Avión", "Alas", 1, 11); INSERTAR EN LOS VALORES del avión ("Avión", "Cola", 1, 12); INSERTAR EN LOS VALORES del avión ("Fuselage", "Salon", 1, 13); INSERTAR EN LOS VALORES del avión ("Fuselage", "Cockpit", 1, 14); INSERTAR EN LOS VALORES del avión ("Fuselage", "Nose", 1, 15); INSERTAR EN LOS VALORES del avión ("Salón", NULL, 1,13); INSERTAR EN LOS VALORES del avión ("cabina", NULL, 1, 14); INSERTAR EN LOS VALORES del avión ("Nariz", NULL, 1, 15); INSERTAR EN LOS VALORES del avión ("Alas", NULL, 2, 11); INSERTAR EN LOS VALORES del avión ("Cola", NULL, 1, 12);
La tabla Avión tiene cuatro columnas. La columna ContainingAssembly define el ensamblaje y la columna ContainedAssembly define las partes (una por una) que componen el ensamblaje correspondiente. La siguiente figura muestra una ilustración gráfica de un posible tipo de aeronave y sus partes constituyentes:

La tabla Avión consta de las siguientes 11 filas:
El siguiente ejemplo usa la cláusula WITH para definir una consulta que calcula el costo total de cada compilación:
UTILIZAR SampleDb; CON lista_de_piezas(ensamblaje1, cantidad, costo) AS (SELECCIONE ensamblaje contenedor, cantidad contenida, costo unitario DESDE avión DONDE ensamblaje contenido ES NULL UNION ALL SELECCIONE a. ensamblaje contenedor, a. cantidad contenida, CAST (l. cantidad * l. costo AS DECIMAL (6,2) ) FROM list_of_parts l, Airplane a WHERE l.assembly1 = a.ContainedAssembly) SELECCIONE ensamblaje1 "Parte", cantidad "Cantidad", costo "Precio" FROM list_of_parts;
La cláusula WITH define una lista OTB denominada list_of_parts, que consta de tres columnas: ensamblaje 1, cantidad y costo. La primera instrucción SELECT del ejemplo se llama solo una vez para almacenar los resultados del primer paso del proceso de recurrencia. La declaración SELECT en la última línea del ejemplo muestra el siguiente resultado.
SQL se utiliza para recuperar datos de la base de datos. SQL es un lenguaje de programación que se parece mucho al inglés pero está diseñado para programas de administración de bases de datos. SQL se usa en cada consulta en Access.
Comprender cómo funciona SQL lo ayuda a crear consultas más precisas y facilita la corrección de consultas que devuelven resultados incorrectos.
Este artículo es parte de la serie de artículos de SQL para Access. Describe los conceptos básicos del uso de SQL para recuperar datos y proporciona ejemplos de sintaxis SQL.
En este articulo
¿Qué es SQL?
SQL es un lenguaje de programación diseñado para trabajar con conjuntos de hechos y las relaciones entre ellos. Los programas de bases de datos relacionales como Microsoft Office Access usan SQL para manipular datos. A diferencia de muchos lenguajes de programación, SQL es fácil de leer y comprender incluso para principiantes. Como muchos lenguajes de programación, SQL es un estándar internacional reconocido por comités de estándares como ISO y ANSI.
Los conjuntos de datos se describen en SQL para ayudar a responder preguntas. Al usar SQL, se debe usar la sintaxis correcta. La sintaxis es un conjunto de reglas que permiten combinar correctamente los elementos de un lenguaje. La sintaxis SQL se basa en la sintaxis inglesa y comparte muchos elementos con la sintaxis del lenguaje Visual Basic para Aplicaciones (VBA).
Por ejemplo, una declaración SQL simple que recupera una lista de los apellidos de los contactos llamados Mary podría verse así:
SELECCIONA Apellido
DE Contactos
WHERE First_Name = "María";
Nota: El lenguaje SQL se usa no solo para realizar operaciones en los datos, sino también para crear y modificar la estructura de los objetos de la base de datos, como las tablas. La parte de SQL que se usa para crear y modificar objetos de base de datos se llama DDL. DDL no está cubierto en este artículo. Para obtener más información, consulte Crear y modificar tablas o índices mediante una consulta de definición de datos.
sentencias SELECCIONAR
La instrucción SELECT se utiliza para describir un conjunto de datos en SQL. Contiene una descripción completa del conjunto de datos que se recuperarán de la base de datos, incluidos los siguientes:
tablas que contienen datos;
enlaces entre datos de diferentes fuentes;
campos o cálculos a partir de los cuales se seleccionan los datos;
condiciones de selección que deben cumplir los datos incluidos en el resultado de la consulta;
necesidad y método de clasificación.
Sentencias SQL
Una instrucción SQL consta de varias partes denominadas cláusulas. Cada cláusula en una instrucción SQL tiene un propósito. Algunas ofertas son obligatorias. La siguiente tabla enumera las sentencias SQL más utilizadas.
|
Cláusula SQL |
Descripción |
Obligatorio |
|
Define los campos que contienen los datos requeridos. |
||
|
Define las tablas que contienen los campos especificados en la cláusula SELECT. |
||
|
Define los criterios de selección de campos que deben cumplir todos los registros incluidos en los resultados. |
||
|
Especifica el orden de clasificación de los resultados. |
||
|
En una instrucción SQL que contiene funciones agregadas, especifica los campos para los que no se calcula ningún valor de resumen en la cláusula SELECT. |
Solo si hay tales campos. |
|
|
En una instrucción SQL que contiene funciones agregadas, define las condiciones que se aplican a los campos para los que se calcula el valor de resumen en la cláusula SELECT. |
Términos SQL
Cada oración SQL se compone de términos que se pueden comparar con partes del discurso. La siguiente tabla enumera los tipos de términos SQL.
|
término SQL |
Parte comparable del discurso |
Definición |
Ejemplo |
|
identificador |
sustantivo |
Un nombre utilizado para identificar un objeto de base de datos, como un nombre de campo. |
Clientes.[Número de teléfono] |
|
operador |
verbo o adverbio |
Una palabra clave que representa o modifica una acción. |
|
|
constante |
sustantivo |
Un valor que no cambia, como un número o NULL. |
|
|
expresión |
adjetivo |
Una combinación de identificadores, operadores, constantes y funciones que se evalúa como un solo valor. |
>= Bienes.[Precio] |
Cláusulas SQL básicas: SELECT, FROM y WHERE
El formato general de las sentencias SQL es:
SELECCIONAR campo_1
DESDE tabla_1
DONDE criterio_1
;
Notas:
El acceso no respeta los saltos de línea en la instrucción SQL. A pesar de esto, se recomienda comenzar cada oración en una nueva línea para que la declaración SQL sea fácil de leer tanto para la persona que la escribió como para todos los demás.
Cada declaración SELECT termina con un punto y coma (;). El punto y coma puede estar al final de la última oración o en una línea separada al final de la instrucción SQL.
Ejemplo en Acceso
El siguiente ejemplo muestra el aspecto que podría tener una instrucción SQL en Access para una consulta de selección simple.
1. Cláusula SELECT
2. Cláusula DESDE
3. Cláusula WHERE
Desglosemos el ejemplo por oraciones para comprender cómo funciona la sintaxis SQL.
Cláusula SELECCIONAR
SELECCIONE , Empresa
Esta es una cláusula SELECT. Contiene una instrucción (SELECT) seguida de dos identificadores ("[Dirección de correo electrónico]" y "Compañía").
Si el identificador contiene espacios o caracteres especiales (por ejemplo, "Dirección de correo electrónico"), debe estar entre corchetes.
En la cláusula SELECT, no necesita especificar las tablas que contienen los campos, y no puede especificar las condiciones de selección que deben cumplir los datos para ser incluidos en los resultados.
En una declaración SELECT, la cláusula SELECT siempre viene antes de la cláusula FROM.
Cláusula DESDE
DE Contactos
Esta es la cláusula FROM. Contiene una declaración (FROM) seguida de un identificador (Contactos).
La cláusula FROM no especifica los campos a seleccionar.
Dónde cláusula
DONDE Ciudad="Seattle"
Esta es la cláusula WHERE. Contiene un operador (DÓNDE) seguido de una expresión (Ciudad="Rostov").
Puede hacer muchas cosas con las cláusulas SELECT, FROM y WHERE. Para obtener más información sobre cómo utilizar estas ofertas, consulte los siguientes artículos:
Ordenar resultados: ORDENAR POR
Al igual que Microsoft Excel, Access le permite ordenar los resultados de una consulta en una tabla. Con la cláusula ORDER BY, también puede especificar cómo se ordenarán los resultados cuando se ejecute la consulta. Si se utiliza una cláusula ORDER BY, debe estar al final de la instrucción SQL.
La cláusula ORDER BY contiene una lista de campos para ordenar, en el mismo orden en que se aplicará la ordenación.
Supongamos, por ejemplo, que desea ordenar los resultados primero por el campo "Empresa" en orden descendente y luego, si hay registros con el mismo valor en el campo "Empresa", ordenarlos por la "Dirección de correo electrónico". " campo en orden ascendente. La cláusula ORDER BY se vería así:
ORDEN POR EMPRESA DESC,
Nota: De forma predeterminada, Access ordena los valores en orden ascendente (de la A a la Z, de menor a mayor). Para ordenar los valores en orden descendente, debe especificar la palabra clave DESC.
Para obtener más información sobre la cláusula ORDER BY, consulte la cláusula ORDER BY.
Trabajar con datos de resumen: cláusulas GROUP BY y HAVING
A veces es necesario trabajar con datos resumidos, como las ventas mensuales totales o los artículos más caros en stock. Para hacer esto, la cláusula SELECT aplica una función agregada al campo. Por ejemplo, si el resultado de una consulta es devolver el número de direcciones de correo electrónico de cada empresa, la cláusula SELECT podría verse así:
La capacidad de usar una función agregada particular depende del tipo de datos en el campo y la expresión deseada. Para obtener más información sobre las funciones agregadas disponibles, consulte el artículo Funciones agregadas de SQL.
Especificación de campos no utilizados en una función agregada: cláusula GROUP BY
Cuando usa funciones agregadas, generalmente necesita crear una cláusula GROUP BY. La cláusula GROUP BY especifica todos los campos a los que no se aplica la función de agregación. Si las funciones agregadas se aplican a todos los campos de una consulta, no necesita crear una cláusula GROUP BY.
La cláusula GROUP BY debe seguir inmediatamente a la cláusula WHERE o FROM si no hay una cláusula WHERE. En la cláusula GROUP BY, los campos se especifican en el mismo orden que en la cláusula SELECT.
Sigamos con el ejemplo anterior. Si la cláusula SELECT solo aplica la función agregada al campo [Dirección de correo electrónico], entonces la cláusula GROUP BY se vería así:
AGRUPAR POR Empresa
Para obtener más información sobre la cláusula GROUP BY, consulte la cláusula GROUP BY.
Restricción de valores agregados con condiciones de agrupación: la cláusula HAVING
Si desea especificar condiciones para restringir los resultados, pero el campo al que desea aplicarlos se usa en una función agregada, no puede usar una cláusula WHERE. En su lugar, se debe utilizar la cláusula HAVING. La cláusula HAVING funciona igual que la cláusula WHERE pero se usa para datos agregados.
Supongamos, por ejemplo, que la función AVG (que calcula el valor promedio) se aplica al primer campo de la cláusula SELECT:
SELECT COUNT(), Empresa
Si desea restringir los resultados de la consulta según el valor de la función COUNT, no puede aplicar una condición de filtro a este campo en la cláusula WHERE. En cambio, la condición debe colocarse en una cláusula HAVING. Por ejemplo, si desea que la consulta devuelva filas solo si la empresa tiene varias direcciones de correo electrónico, puede usar la siguiente cláusula HAVING:
TENIENDO CUENTA()>1
Nota: Una consulta puede incluir tanto una cláusula WHERE como una cláusula HAVING, con las condiciones para los campos que no se usan en las funciones agregadas especificadas en la cláusula WHERE, y las condiciones para los campos que se usan en las funciones agregadas se especifican en la cláusula HAVING .
Para obtener más información sobre la cláusula HAVING, consulte la cláusula HAVING.
Combinación de resultados de consultas: el operador UNION
El operador UNION se usa para ver simultáneamente todos los datos devueltos por varias consultas de selección similares como un conjunto combinado.
El operador UNION le permite combinar dos sentencias SELECT en una sola. Las instrucciones SELECT combinadas deben tener el mismo número y orden de campos de salida con tipos de datos iguales o compatibles. Cuando se ejecuta una consulta, los datos de cada conjunto de campos coincidentes se combinan en un solo campo de salida, por lo que la salida de la consulta tiene tantos campos como cada instrucción SELECT individualmente.
Nota: En las consultas de unión, los tipos de datos numéricos y de texto son compatibles.
Con el operador UNION, puede especificar si las filas duplicadas, si las hay, deben incluirse en los resultados de la consulta. Para ello, utilice la palabra clave ALL.
Una consulta para unir dos sentencias SELECT tiene la siguiente sintaxis básica:
SELECCIONAR campo_1
DESDE tabla_1
UNIÓN
SELECCIONA campo_a
DESDE table_a
;
Supongamos, por ejemplo, que hay dos tablas llamadas "Productos" y "Servicios". Ambas tablas contienen campos con el nombre del producto o servicio, precio e información de garantía, así como un campo que indica la exclusividad del producto o servicio ofrecido. Aunque las tablas de Productos y Servicios proporcionan diferentes tipos de garantías, la información básica es la misma (si se proporciona una garantía de calidad para productos o servicios individuales). Para unir cuatro campos de dos tablas, puede usar la siguiente consulta de unión:
SELECCIONE nombre, precio, garantía_disponible, oferta_exclusiva
DESDE Productos
UNIÓN TODOS
SELECCIONE nombre, precio, garantía_disponible, oferta_exclusiva
DESDE Servicios
;
Para obtener más información sobre la combinación de instrucciones SELECT mediante el operador UNION, consulte el artículo
Cada uno de nosotros se encuentra y utiliza regularmente varias bases de datos. Cuando seleccionamos una dirección de correo electrónico, estamos trabajando con una base de datos. Las bases de datos utilizan servicios de búsqueda, bancos para almacenar datos de clientes, etc.
Pero, a pesar del uso constante de bases de datos, incluso para muchos desarrolladores de sistemas de software existen muchos "puntos blancos" debido a las diferentes interpretaciones de los mismos términos. Daremos una breve definición de los términos básicos de la base de datos antes de ver el lenguaje SQL. Entonces.
Base de datos - un archivo o conjunto de archivos para almacenar estructuras de datos ordenadas y sus relaciones. Muy a menudo, una base de datos se denomina sistema de gestión: es solo un depósito de información en un formato determinado y puede funcionar con varios DBMS.
Mesa - Imaginemos una carpeta que almacena documentos agrupados según un determinado atributo, por ejemplo, una lista de pedidos del último mes. Esta es la tabla en la computadora.Una tabla separada tiene su propio nombre único.
Tipo de datos - el tipo de información que se permite almacenar en una columna o fila en particular. Pueden ser números o texto de cierto formato.
columna y fila- todos hemos trabajado con hojas de cálculo que también tienen filas y columnas. Cualquier base de datos relacional funciona con tablas de la misma manera. Las filas a veces se denominan registros.
Clave primaria- cada fila de la tabla puede tener una o más columnas para identificarla de manera única. Sin una clave principal, es muy difícil actualizar, modificar y eliminar las filas deseadas.
¿Qué es SQL?
sql(Inglés - lenguaje de consulta estructurado) se desarrolló solo para trabajar con bases de datos y actualmente es el estándar para todos los DBMS populares. La sintaxis del lenguaje consta de un pequeño número de operadores y es fácil de aprender. Pero, a pesar de la simplicidad externa, permite la creación de consultas sql para operaciones complejas con una base de datos de cualquier tamaño.
Desde 1992 existe un estándar generalmente aceptado llamado ANSI SQL. Define la sintaxis básica y las funciones de los operadores y es compatible con todos los líderes del mercado de DBMS, como ORACLE. Es imposible cubrir todas las posibilidades del lenguaje en un pequeño artículo, por lo que consideraremos brevemente solo las consultas SQL básicas. Los ejemplos muestran claramente la simplicidad y las posibilidades del lenguaje:
- creación de bases de datos y tablas;
- muestreo de datos;
- agregar registros;
- modificación y eliminación de información.
Tipos de datos SQL
Todas las columnas de una tabla de base de datos almacenan el mismo tipo de datos. Los tipos de datos en SQL son los mismos que en otros lenguajes de programación.
Creación de tablas y bases de datos.

Hay dos formas de crear nuevas bases de datos, tablas y otras consultas en SQL:
- Sentencias SQL a través de la consola DBMS
- Utilizando las herramientas de administración interactiva incluidas con el servidor de base de datos.
El operador crea una nueva base de datos. CREAR BASE DE DATOS<наименование базы данных>; . Como puede ver, la sintaxis es simple y concisa.
Creamos tablas dentro de la base de datos usando la sentencia CREATE TABLE con los siguientes parámetros:
- nombre de la tabla
- nombres de columnas y tipos de datos
Como ejemplo, vamos a crear una tabla de productos básicos con las siguientes columnas:
Creamos una tabla:
CREAR TABLA
(commodity_id CHAR(15) NO NULO,
id_vendedor CHAR(15) NO NULO,
nombre_mercancía CHAR(254) NULL,
precio_mercancía DECIMAL(8,2) NULO,
mercancía_desc VARCHAR(1000) NULL);
La tabla tiene cinco columnas. Después del nombre viene el tipo de datos, las columnas están separadas por comas. El valor de una columna puede estar vacío (NULL) o debe llenarse (NOT NULL), y esto se determina cuando se crea la tabla.
Selección de datos de una tabla

El operador de selección de datos es la consulta SQL más utilizada. Para obtener información, debe especificar qué queremos seleccionar de dicha tabla. Primero un ejemplo sencillo:
SELECCIONE nombre_producto DESDE Producto
Después de la declaración SELECT, especificamos el nombre de la columna para obtener información, y FROM define la tabla.
El resultado de la ejecución de la consulta serán todas las filas de la tabla con valores de Commodity_name en el orden en que se ingresaron en la base de datos, es decir sin ningún tipo de clasificación. Se utiliza una cláusula ORDER BY adicional para ordenar el resultado.
Para consultar varios campos, enumérelos separados por comas, como en el siguiente ejemplo:
SELECCIONE id_producto, nombre_producto, precio_producto DESDE Producto
Es posible obtener el valor de todas las columnas de una fila como resultado de una consulta. Para ello, se utiliza el signo "*":
SELECCIONE * DE Producto
- Además, SELECT admite:
- Clasificación de datos (sentencia ORDER BY)
- Seleccionar según condiciones (DÓNDE)
- Término de agrupación (GROUP BY)
Agregar una línea

Para agregar una fila a una tabla, se utilizan consultas SQL con la instrucción INSERT. La adición se puede hacer de tres maneras:
- agregar una nueva línea completa;
- parte de una cadena;
- resultados de la consulta.
Para agregar una fila completa, debe especificar el nombre de la tabla y los valores de las columnas (campos) de la nueva fila. Aquí hay un ejemplo:
INSERTAR EN VALORES de productos básicos ("106", "50", "Coca-Cola", "1,68", "Sin alcohol")
El ejemplo agrega un nuevo producto a la tabla. Los valores se especifican después de VALORES para cada columna. Si no hay un valor correspondiente para la columna, se debe especificar NULL. Las columnas se rellenan con valores en el orden especificado cuando se creó la tabla.
Si agrega solo una parte de una fila, debe especificar explícitamente los nombres de las columnas, como en el ejemplo:
INSERTAR EN Producto (commodity_id, vendor_id, commodity_name)
VALORES("106 ", '50", "Coca Cola",)
Introducimos únicamente los identificadores del producto, el proveedor y su nombre, y dejamos el resto de campos vacíos.
Adición de resultados de consulta
INSERT se usa principalmente para agregar filas, pero también se puede usar para agregar los resultados de una instrucción SELECT.
cambiar datos

Para cambiar la información en los campos de una tabla de base de datos, debe usar la instrucción UPDATE. El operador se puede utilizar de dos formas:
- Se actualizan todas las filas de la tabla.
- Sólo para una determinada línea.
UPDATE consta de tres elementos principales:
- la tabla en la que es necesario hacer cambios;
- nombres de campo y sus nuevos valores;
- condiciones para seleccionar filas para cambiar.
Considere un ejemplo. Digamos que el precio de un producto con ID=106 ha cambiado, por lo que esta fila debe actualizarse. Escribimos el siguiente operador:
ACTUALIZAR Mercancía SET precio_mercancía = "3.2" DONDE id_mercancía = "106"
Especificamos el nombre de la tabla, en nuestro caso Commodity, donde se realizará la actualización, luego, después de SET, el nuevo valor de la columna y encontramos el registro deseado especificando el valor de ID deseado en DONDE.
Para cambiar varias columnas, especifique varios pares de valores de columna separados por comas después de la instrucción SET. Veamos un ejemplo en el que se actualiza el nombre y el precio del producto:
ACTUALIZAR Commodity SET commodities_name='Fanta', commodities_price = "3.2" DONDE commodities_id = "106"
Para eliminar información en una columna, puede establecerla en NULL si la estructura de la tabla lo permite. Debe recordarse que NULL es exactamente un valor "no", y no un cero en forma de texto o número. Eliminar descripción del producto:
ACTUALIZAR Mercancía SET commodities_desc = NULL WHERE mercadería_id = "106"
Eliminando filas

Las consultas SQL para eliminar filas en una tabla se ejecutan con la instrucción DELETE. Hay dos casos de uso:
- se eliminan ciertas filas de la tabla;
- se eliminan todas las filas de la tabla.
Un ejemplo de eliminación de una fila de una tabla:
ELIMINAR DE Mercancía DONDE mercancía_id = "106"
Después de DELETE FROM especificamos el nombre de la tabla en la que se eliminarán las filas. La cláusula WHERE contiene una condición por la cual las filas se seleccionarán para su eliminación. En el ejemplo, estamos eliminando la línea de productos con ID=106. Especificar DÓNDE es muy importante. omitir esta declaración eliminará todas las filas de la tabla. Esto también se aplica a cambiar el valor de los campos.
La sentencia DELETE no especifica nombres de columna ni metacaracteres. Elimina filas por completo, pero no puede eliminar una sola columna.
Usando SQL en Microsoft Access

Por lo general, se usa de forma interactiva para crear tablas, bases de datos, administrar, modificar, analizar datos en la base de datos e implementar consultas de SQL Access a través de un conveniente diseñador de consultas interactivas (Query Designer), mediante el cual puede crear y ejecutar inmediatamente declaraciones SQL de cualquier complejidad.
También se admite el modo de acceso al servidor, en el que Access DBMS se puede utilizar como generador de consultas SQL a cualquier fuente de datos ODBC. Esta capacidad permite que las aplicaciones de Access interactúen con cualquier formato.
Extensiones SQL
Dado que las consultas SQL no tienen todas las funciones de los lenguajes de programación de procedimientos, como bucles, ramas, etc., los proveedores de DBMS desarrollan su propia versión de SQL con funciones avanzadas. En primer lugar, se trata de soporte para procedimientos almacenados y operadores estándar de lenguajes de procedimientos.
Los dialectos más comunes del idioma:
- Base de datos Oracle - PL/SQL
- Interbase, Firebird - PSQL
- Servidor Microsoft SQL - Transact-SQL
- PostgreSQL - PL/pgSQL.
SQL a la web
MySQL DBMS se distribuye bajo la Licencia Pública General GNU. Existe una licencia comercial con la capacidad de desarrollar módulos personalizados. Como parte integral, se incluye en los ensamblajes más populares de servidores de Internet, como XAMPP, WAMP y LAMP, y es el DBMS más popular para desarrollar aplicaciones en Internet.
Fue desarrollado por Sun Microsystems y actualmente lo mantiene Oracle Corporation. Admite bases de datos de hasta 64 terabytes, estándar de sintaxis SQL:2003, replicación de bases de datos y servicios en la nube.
Sintaxis:
* Dónde campos1- campos para la selección separados por comas, también puede especificar todos los campos con *; mesa- el nombre de la tabla de la que extraemos los datos; condiciones— condiciones de muestreo; campos2— campo o campos, separados por comas, por los cuales ordenar; contar— el número de filas para descargar.
* la consulta entre corchetes es opcional para obtener datos.
Casos de uso simples para seleccionar
1. Muestreo de datos normales:
> SELECCIONE * DE usuarios
2. Selección de datos con unión de dos tablas (JOIN):
SELECCIONE u.name, r.* DE usuarios u ÚNASE a users_rights r ON r.user_id=u.id
* en este ejemplo, los datos se seleccionan con tablas de unión usuarios Y derechos_de_los_usuarios. Están agrupados por campos. id_usuario(en la tabla Users_rights) y identificación(usuarios). El campo de nombre se recupera de la primera tabla y todos los campos de la segunda.
3. Muestreo con intervalo de tiempo y/o fecha
a) se conocen el punto de partida y un cierto intervalo de tiempo:
* se seleccionarán los datos de la última hora (campo fecha).
b) se conocen la fecha de inicio y la fecha de finalización:
25.10.2017 Y 25.11.2017 .
c) se conocen las fechas de inicio y fin + la hora:
* seleccionar datos entre 25/03/2018 0 horas 15 minutos Y 25.04.2018 15 horas 33 minutos y 9 segundos.
d) extraer datos para un mes y año específicos:
* extraer datos donde en el campo fecha hay valores para abril 2018 del año.
4. Muestreo del valor máximo, mínimo y promedio:
> SELECCIONE max(área), min(área), avg(área) DESDE el país
* máximo- valor máximo; min- mínimo; promedio- promedio.
5. Usando la longitud de la cadena:
* esta consulta debe mostrar todos los usuarios cuyo nombre consta de 5 caracteres.
Ejemplos de consultas más complejas o poco utilizadas
1. Fusión con agrupación de los datos seleccionados en una sola línea (GROUP_CONCAT):
* de la tabla usuarios obteniendo datos por campo identificación, todos caben en una línea, los valores están separados comas.
2. Agrupación de datos por dos o más campos:
> SELECCIONE * DEL GRUPO DE USUARIOS POR CONCAT (título, "::", nacimiento)
* total, en este ejemplo, descargaremos datos de la tabla de usuarios y los agruparemos por campos título Y nacimiento. Antes de agrupar, fusionamos los campos en una sola línea con un separador :: .
3. Combinar resultados de dos tablas (UNION):
> (SELECCIONE id, fio, dirección, "Usuarios" como tipo DE usuarios)
UNIÓN
(SELECCIONE id, fio, dirección, "Clientes" como tipo DE clientes)
* en este ejemplo, los datos se recuperan de las tablas usuarios Y clientes.
4. Una muestra de promedios agrupados para cada hora:
SELECCIONE avg(temperatura), DATE_FORMAT(datetimeupdate, "%Y-%m-%d %H") como hora_datetime DESDE el archivo GROUP BY DATE_FORMAT(datetimeupdate, "%Y-%m-%d %H")
* aquí extraemos el valor medio del campo temperatura de la mesa archivo y agrupar por campo actualización de fecha y hora(con división horaria para cada hora).
Insertar (INSERTAR)
Sintaxis 1:
> INSERTAR EN
| PROMEDIO(X) | Devuelve el promedio de todas las X no NULL de un grupo. Los valores de cadena y BLOB que no parecen números se tratan como 0. El resultado de AVG() siempre es un valor de punto flotante, incluso si todos los valores de entrada son enteros. |
| La primera forma devuelve el número de veces que X no es NULL en el grupo. La segunda forma (con el argumento *) devuelve el número total de filas en el grupo. | |
| MÁX.(X) | Devuelve el valor máximo de todos los valores del grupo. El orden de clasificación normal se utiliza para determinar el valor máximo. |
| MARTA) | Devuelve el valor mínimo no NULL de todos los valores del grupo. El orden de clasificación normal se utiliza para determinar el valor mínimo. Si todos los valores del grupo son NULL, se devuelve NULL. |
| Devuelve la suma de los números de todos los valores no NULL del grupo. Si todos los valores son NULL, entonces SUM() devuelve NULL y TOTAL() devuelve 0.0. El resultado de TOTAL() siempre es un valor de coma flotante. El resultado de SUM() es un valor entero si todos los valores de entrada que no son NULL son enteros. Si algún valor de entrada para SUM() no es un número entero ni NULL, SUM() devuelve un valor de punto flotante. Este valor puede ser un número aproximado de la cantidad correcta. |
En cualquiera de las funciones estáticas anteriores que toman un solo argumento, puede usar la palabra clave DISTINCT antes de ese argumento. En este caso, los elementos duplicados se filtran antes de pasar a la función estática. Por ejemplo, llamar a COUNT(DISTINCT x) devuelve la cantidad de valores diferentes en la columna X, no la cantidad total de valores no NULL en la columna x.
Funciones escalares
Las funciones escalares realizan operaciones en valores de una fila a la vez. La siguiente es una lista de estas funciones:
| ABS(X) | Devuelve el valor absoluto del argumento X. |
| UNIRSE (X, Y, ...) | Devuelve una copia del primer argumento no NULL. Si todos los argumentos son NULL, se devuelve NULL. Requiere al menos dos argumentos. |
| GLOBO(X, Y) | Esta función se utiliza para implementar la sintaxis X GLOB Y. |
| SI LLAMA(X, Y) | Devuelve una copia del primer argumento no NULL. Si ambos argumentos son NULL, se devuelve NULL. Esta función funciona igual que COALESCE() . |
| HEXAGONAL(X) | El argumento se trata como un valor del tipo de almacenamiento BLOB. El resultado es una visualización hexadecimal del contenido de ese valor. |
| LAST_INSERT_ROWID() | Devuelve el identificador (clave principal creada) de la última fila insertada en la base de datos a través de la instancia actual de SQLConnection. Este valor es el mismo que el valor devuelto por la propiedad SQLConnection.lastInsertRowID. |
| LONGITUD(X) | Devuelve la longitud de la cadena X en caracteres. |
| COMO(X, Y [, Z]) | Esta función se utiliza para implementar la sintaxis SQL X LIKE Y. Si la cláusula ESCAPE opcional está presente, la función se llama con tres argumentos. De lo contrario, se llama con solo dos argumentos. |
| INFERIOR (X) | Devuelve una copia de la cadena X con todos los caracteres convertidos a minúsculas. |
| Devuelve una cadena con espacios eliminados a la izquierda de X . Si se proporciona el argumento Y, la función elimina cualquier carácter en Y a la izquierda de X. | |
| MÁX (X, Y, ...) | Devuelve el argumento con el valor máximo. Los argumentos pueden ser cadenas añadidas a números. El valor máximo está determinado por el orden de clasificación especificado. Cabe señalar que la función MAX() es simple cuando tiene 2 o más argumentos, pero con un argumento es una función estática. |
| MÍN(X, Y, ...) | Devuelve el argumento con el valor mínimo. Los argumentos pueden ser cadenas añadidas a números. El valor mínimo está determinado por el orden de clasificación especificado. Cabe señalar que la función MIN() es simple cuando tiene 2 o más argumentos, pero con un argumento es una función estática. |
| NULLIF(X, Y) | Devuelve el primer argumento si los argumentos son diferentes; de lo contrario, devuelve NULL. |
| COTIZAR(X) | Esta rutina devuelve una cadena que representa el valor de su argumento, adecuada para insertarla en otra sentencia SQL. Las cadenas se encierran entre comillas simples con caracteres de escape entre comillas internas según sea necesario. Las clases de almacenamiento BLOB se codifican como literales hexadecimales. Esta función es útil cuando se escriben disparadores para implementar funciones de deshacer o rehacer. |
| ALEATORIO(*) | Devuelve un entero pseudoaleatorio del intervalo -9223372036854775808 - 9223372036854775807. Este es un valor aleatorio No es resistente al cifrado. |
| BLOB ALEATORIO(N) | Devuelve N bytes de un BLOB con bytes pseudoaleatorios. N debe ser un número entero positivo. Este es un valor aleatorio No es resistente al cifrado. Si N es negativo, se devuelve un byte. |
| Redondea un número X a Y lugares decimales a la derecha del punto decimal. Si se omite el argumento Y, se utiliza 0. | |
| Devuelve una cadena con espacios eliminados a la izquierda de X . Si se proporciona el argumento Y, la función elimina cualquier carácter en Y a la derecha de X . | |
| SUBSTR(X, Y, Z) | Devuelve una subcadena de la cadena de entrada X que comienza en el carácter Y y tiene una longitud de Z caracteres. El carácter más a la izquierda de X representa la posición del índice 1. Si Y es negativo, el primer carácter de la subcadena se encuentra contando desde la derecha, no desde la izquierda. |
| Devuelve una cadena con espacios en blanco eliminados a la izquierda y a la derecha de X . Si se proporciona el argumento Y, la función elimina cualquier carácter en Y a la izquierda y derecha de X . | |
| TIPO DE(X) | Devuelve el tipo de la expresión X . Los posibles valores devueltos son "null", "integer", "real", "text" y "blob". Consulte la sección para obtener más información sobre los tipos de datos. |
| SUPERIOR (X) | Devuelve una copia de la cadena de entrada X con todos los caracteres convertidos a mayúsculas. |
| ZEROBLOB(N) | Devuelve un BLOB con N bytes 0x00. |
Funciones de formato de fecha y hora
Las funciones de formato de fecha y hora son un grupo de funciones escalares que se utilizan para crear datos de fecha y hora con formato. Cabe señalar que estas funciones trabajan con cadenas y valores numéricos y los devuelven. Estas funciones no están diseñadas para usarse con el tipo de datos DATE. Si se utilizan con datos en una columna cuyo tipo de datos declarado es DATE, su comportamiento no será el esperado.
| FECHA(T, ...) | La función DATE() devuelve una cadena que contiene la fecha en el siguiente formato: AAAA-MM-DD. El primer parámetro (T) especifica la cadena de tiempo del formato ubicado en el archivo . Se puede especificar cualquier número de modificadores después de la cadena de tiempo. Los modificadores se encuentran en el archivo . |
| HORA(T, ...) | La función TIME() devuelve una cadena que contiene la hora en formato HH:MM:SS. El primer parámetro (T) especifica la cadena de tiempo del formato ubicado en el archivo . Se puede especificar cualquier número de modificadores después de la cadena de tiempo. Los modificadores se encuentran en el archivo . |
| FECHA HORA (T, ...) | La función DATETIME() devuelve una cadena que contiene la fecha y la hora en formato AAAA-MM-DD HH:MM:SS. El primer parámetro (T) especifica la cadena de tiempo del formato ubicado en el archivo . Se puede especificar cualquier número de modificadores después de la cadena de tiempo. Los modificadores se encuentran en el archivo . |
| DÍA DE JULIÁN (T, ...) | La función DÍAJULIO() devuelve un número que representa el número de días desde el mediodía GMT del 24 de noviembre de 4714 a. C. y la fecha indicada. El primer parámetro (T) especifica la cadena de tiempo del formato ubicado en el archivo . Se puede especificar cualquier número de modificadores después de la cadena de tiempo. Los modificadores se encuentran en el archivo . |
| STRFTIME(V, T, ...) | La subrutina STRFTIME() devuelve la fecha dada en la cadena de formato dada como el primer argumento de F . La cadena de formato admite los siguientes comodines: El segundo parámetro (T) especifica la cadena de tiempo del formato ubicado en el archivo . Se puede especificar cualquier número de modificadores después de la cadena de tiempo. Los modificadores se encuentran en el archivo . |
Formatos de tiempo
El formato de cadena de tiempo puede ser cualquiera de los siguientes:
| AAAA-MM-DD | 2007-06-15 |
| AAAA-MM-DD HH:MM | 2007-06-15 07:30 |
| AAAA-MM-DD HH:MM:SS | 2007-06-15 07:30:59 |
| AAAA-MM-DD HH:MM:SS,SSS | 2007-06-15 07:30:59.152 |
| AAAA-MM-DDTHH:MM | 2007-06-15T07:30 |
| AAAA-MM-DDTHH:MM:SS | 2007-06-15T07:30:59 |
| AAAA-MM-DDTHH:MM:SS,SSS | 2007-06-15T07:30:59.152 |
| HH:MM | 07:30 (fecha: 2000-01-01) |
| HH:MM:SS | 07:30:59 (fecha: 2000-01-01) |
| HH:MM:SS,SSS | 07:30:59:152 (fecha: 2000-01-01) |
| ahora | Fecha y hora actual en formato UTC. |
| DDDD.DDDD | Día juliano como número de punto flotante |
Símbolo T en estos formatos, representa el carácter literal "T" que separa la fecha y la hora. Los formatos de solo tiempo asumen la fecha 2001-01-01.
Modificadores
La cadena de tiempo puede ir seguida de cero o más modificadores que cambien la fecha o la interpretación de la fecha. Están disponibles los siguientes modificadores:
| NNN días | El número de días que se van a sumar a la hora. |
| NNN horas | El número de horas que se van a sumar al tiempo. |
| NNN minutos | La cantidad de minutos que se agregarán a la hora. |
| NNN,NNNN segundos | La cantidad de segundos o milisegundos que se agregarán a la hora. |
| NNN meses | El número de meses a sumar al tiempo. |
| NNN años | El número de años a sumar al tiempo. |
| principio de mes | Compensación de tiempo hasta el comienzo del mes. |
| inicio del año | Cambiando el tiempo de regreso al comienzo del año. |
| comienzo del dia | Cambie el tiempo de regreso al comienzo del día. |
| día de la semana norte | Adelanta la hora el día de la semana especificado. (0 = domingo, 1 = lunes, etc.) |
| hora local | Convertir fecha a hora local |
| UTC | Convertir la fecha al formato UTC |
Operadores
SQL admite una gran cantidad de declaraciones, incluidas las declaraciones comunes que se encuentran en la mayoría de los lenguajes de programación, así como varias declaraciones exclusivas de SQL.
Operadores Generales
Los siguientes operadores binarios están permitidos en un bloque SQL y se enumeran en orden de prioridad, de mayor a menor:
|| * / % + - << >> & | < <= > >= = == != <>EN Y OOperadores de prefijo unario admitidos:
- ! ~ NO
El operador COLLATE se puede considerar como un operador de sufijo unario. El operador COLLATE tiene la prioridad más alta. Siempre tiene un enlace más estricto que el operador unario de prefijo o cualquier operador binario.
Cabe señalar que hay dos tipos de operadores de igualdad y desigualdad. La igualdad puede tomar la forma = o == . El operador de desigualdad puede ser de la forma != o<> .
Operador || es un operador de concatenación de cadenas: concatena dos cadenas de sus operandos.
El operador % devuelve el resto cuando el operando derecho se divide por el operando izquierdo.
Cualquier operador binario da como resultado un valor numérico, pero esto no se aplica al operador de concatenación || , que produce un resultado de cadena.
Sentencias SQL
COMO
El operador LIKE realiza la coincidencia de patrones.
expr::= (nombre-columna | expr) LIKE patrón patrón::= "[ cadena | % | _ ]"
El operando a la derecha del operador LIKE contiene el patrón y el operando de la izquierda contiene la cadena que coincide con el patrón. El carácter de porcentaje (%) en el patrón es un comodín y coincide con cualquier secuencia de caracteres en la cadena (o sin caracteres). El carácter de subrayado (_) en un patrón coincide con cualquier carácter único en la cadena. Cualquier otro carácter coincide consigo mismo o con su carácter equivalente en minúsculas/mayúsculas, lo que significa que las coincidencias se determinan independientemente del caso. (Nota: el motor de la base de datos solo entiende mayúsculas y minúsculas de caracteres latinos de 7 bits. Por lo tanto, el operador LIKE distingue entre mayúsculas y minúsculas para caracteres iso8859 de 8 bits o caracteres UTF-8. Por ejemplo, la expresión "a" LIKE " A" es VERDADERO, pero "æ" COMO "Æ" - FALSO). La distinción entre mayúsculas y minúsculas de los caracteres latinos se puede cambiar mediante la propiedad SQLConnection.caseSensitiveLike.
Si la cláusula ESCAPE opcional está presente, la expresión después de la palabra clave ESCAPE debe dar como resultado una cadena de un solo carácter. Este carácter se puede usar en el patrón LIKE para hacer coincidir el porcentaje literal o guiones bajos. Un carácter de escape después de un carácter de porcentaje, un carácter de subrayado o por sí mismo coincide con un carácter de porcentaje literal, un carácter de subrayado o un carácter de escape en una cadena, respectivamente.
GLOBO
El operador GLOB es similar a LIKE , pero usa la sintaxis de globalización de archivos de Unix para sus comodines. A diferencia de LIKE , GLOB distingue entre mayúsculas y minúsculas.
EN
El operador IN evalúa si su operando izquierdo es igual a uno de los valores del operando derecho (el conjunto de valores entre paréntesis).
In-expr::= expr IN (lista de valores) | expr IN (sentencia de selección) | expr IN nombre-tabla lista-valores::= valor-literal [, valor-literal]*
El operando derecho puede ser un conjunto de valores literales separados por comas o el resultado de una instrucción SELECT. Para obtener una descripción y restricciones sobre el uso de declaraciones SELECT cuando se usan como el operando derecho del operador IN, consulte la descripción de las declaraciones SELECT.
EN MEDIO Y
El operador BETWEEN...AND es equivalente a usar dos expresiones con >= y<= . Например, выражение x BETWEEN y AND z эквивалентно x >= y Y x<= z .
NO
El operador NOT es un operador de negación. Los operadores GLOB, LIKE e IN pueden estar precedidos por la palabra clave NOT para invertir el valor de prueba (en otras palabras, para verificar que el valor No coincide con el patrón especificado).
Opciones
El parámetro especifica un marcador de posición en la expresión para un valor literal que se completa en tiempo de ejecución mediante la asignación de un valor a la matriz asociativa SQLStatement.parameters. Los parámetros pueden adoptar tres formas:
Funciones de SQL no admitidas
- Restricciones de CLAVE EXTRANJERA. Las restricciones FOREIGN KEY se analizan, pero no se aplican.
- disparadores. Los activadores FOR EACH STATEMENT no son compatibles (todos los activadores deben ser FOR EACH ROW). Los disparadores INSTEAD OF no son compatibles con las tablas (solo los disparadores INSTEAD OF están permitidos en las vistas). Los disparadores recursivos (que se llaman a sí mismos) no son compatibles.
- ALTERAR TABLA. Solo se admiten las variantes RENAME TABLE y ADD COLUMN del comando ALTER TABLE. Se omiten otros tipos de operaciones ALTER TABLE como DROP COLUMN , ALTER COLUMN , ADD CONSTRAINT , etc.
- Transacciones anidadas. Solo se permite una transacción activa.
- UNIÓN EXTERNA DERECHA y COMPLETA. RIGHT OUTER JOIN o FULL OUTER JOIN no son compatibles.
- VER actualización. La vista es de solo lectura. La vista no puede ejecutar una declaración DELETE, INSERT o UPDATE. Se admite un disparador INSTEAD OF que se activa cuando se intenta DELETE , INSERT o UPDATE en una vista y se puede usar para actualizar tablas auxiliares en el cuerpo del disparador.
- CONCEDER y REVOCAR. La base de datos es un archivo de disco simple; los únicos permisos de acceso que se aplican son los permisos de archivo normales en el sistema operativo subyacente. Los comandos GRANT y REVOKE que normalmente se encuentran en los DBMS relacionales cliente/servidor no están implementados.
Los siguientes elementos SQL y funciones de SQLite son compatibles con algunas implementaciones de SQLite, pero no son compatibles con Adobe AIR. La mayoría de estas funciones están disponibles a través de los métodos de la clase SQLConnection.
- Elementos SQL relacionados con transacciones (BEGIN, END, COMMIT, ROLLBACK): Las siguientes funciones están disponibles a través de los métodos relacionados con transacciones de la clase SQLConnection: SQLConnection.begin() , SQLConnection.commit() y SQLConnection.rollback() .
- ANALIZAR SQLConnection.analyze() .
- ADJUNTAR: esta característica está disponible a través del método SQLConnection.attach().
- COPIAR
- CREAR MESA VIRTUAL: Esta instrucción no es compatible.
- DESPEGAR: esta característica está disponible a través del método SQLConnection.detach().
- PRAGMA: Esta instrucción no es compatible.
- VACÍO: esta característica está disponible a través del método SQLConnection.compact().
- Sin acceso a la tabla del sistema. Las tablas del sistema, incluidas sqlite_master y otras tablas con el prefijo "sqlite_", no están disponibles en las sentencias de SQL. El tiempo de ejecución incluye una API de esquema, que proporciona una forma orientada a objetos de acceder a los datos del esquema. Consulte la descripción del método SQLConnection.loadSchema() para obtener más información.
- Función SQLITE_VERSION(): La función sqlite_version() no está disponible para su uso en sentencias SQL.
- Funciones de expresiones regulares (MATCH() y REGEX()). Estas funciones no están disponibles en sentencias SQL.
Las siguientes características difieren entre las implementaciones de SQLite y Adobe AIR:
- Parámetros de instrucción indexados. En muchas implementaciones, los parámetros de instrucción indexados están basados en uno. Sin embargo, en Adobe AIR, los parámetros de instrucción que se indexan se basan en cero (es decir, al primer parámetro se le asigna el índice 0, al segundo parámetro se le asigna el índice 1, y así sucesivamente).
Características adicionales de SQL
Los siguientes tipos de afinidad de columna predeterminados no se admiten en SQLite, pero se admiten en Adobe AIR:
Los siguientes tipos de valores literales predeterminados no se admiten en SQLite, pero se admiten en Adobe AIR:
- Significado verdadero. Representa un valor booleano literal verdadero para trabajar con columnas BOOLEAN.
- Significado FALSO. Representa el booleano literal false para trabajar con columnas BOOLEAN.
Tipos de datos admitidos
A diferencia de la mayoría de las bases de datos SQL, el motor de base de datos SQL de Adobe AIR no requiere que los valores en las columnas de nombre de tabla sean de un tipo particular. Por el contrario, el entorno de tiempo de ejecución utiliza dos conceptos para la gestión de tipos de datos: clases de almacenamiento y afinidad de columnas. Esta sección describe las clases de almacenamiento y las afinidades de columna, y cómo se resuelven las diferencias de tipo de datos en diferentes condiciones:
Clases de almacenamiento
Las clases de almacenamiento representan tipos de datos reales que se utilizan para almacenar valores en una base de datos. Están disponibles las siguientes clases de almacenamiento.
- NULO. El valor es NULL.
- ENTERO. El valor es un entero con signo.
- REAL. El valor representa un valor numérico de coma flotante.
- TEXTO. El valor es una cadena de texto (limitado a 256 MB).
- GOTA. El valor representa un objeto grande binario (BLOB); en otras palabras, datos binarios sin procesar (limitados a 256 MB).
Antes de que se ejecute la instrucción SQL, a todos los valores pasados a la base de datos como literales incrustados en la instrucción SQL, o valores vinculados por parámetros a una instrucción SQL preparada, se les asigna una clase de almacenamiento.
A los literales que forman parte de una instrucción SQL se les asigna la clase de almacenamiento TEXTO si están entre comillas simples o dobles, INTEGER si el literal se especifica como un número sin comillas sin punto decimal ni exponente, REAL si el literal es un número sin comillas con punto decimal o exponente, y NULL si el valor es NULL. Los literales con clase de almacenamiento BLOB se indican como X"ABCD" . Consulte la sección para obtener más información.
A los valores que se sustituyen como parámetros mediante la matriz asociativa SQLStatement.parameters se les asigna la clase de almacenamiento que más se parece al enlace con el tipo de datos original. Por ejemplo, los valores int se vinculan como la clase de almacenamiento INTEGER, los valores numéricos se asignan a la clase de almacenamiento REAL, los valores de cadena se asignan a la clase de almacenamiento TEXT y los objetos ByteArray se asignan a la clase de almacenamiento BLOB.
Afinidad de columna
semejanza column es el tipo recomendado para los datos de esa columna. Si un valor se almacena en una columna (a través de una declaración INSERT o UPDATE), el tiempo de ejecución intenta convertir el tipo de datos de ese valor a la afinidad especificada. Por ejemplo, si se inserta un valor de fecha (una instancia de fecha de ActionScript o JavaScript) en una columna con afinidad de TEXTO, el valor de fecha se convierte en una representación de cadena (equivale a llamar al método toString() del objeto) antes de almacenarse en la base de datos. . Si el valor no se puede convertir a la afinidad especificada, se produce un error y la operación falla. Cuando se recupera un valor de la base de datos mediante una declaración SELECT, se devuelve como una instancia de la clase correspondiente a la afinidad, independientemente de si se convirtió de otro tipo en el momento de guardar.
Si la columna acepta valores nulos, el valor nulo de ActionScript o JavaScript se puede utilizar como valor de parámetro para almacenar NULL en la columna. Cuando se recupera un valor de clase de almacenamiento NULL en una sentencia SELECT, siempre se devuelve como un valor ActionScript o JavaScript nulo, independientemente de la afinidad de columna. Si una columna acepta valores nulos, siempre debe verificar los valores recuperados de esa columna para determinar si son nulos antes de intentar convertir el valor a un tipo no nulo (como Número o Booleano).
A cada columna de la base de datos se le asigna una de las siguientes afinidades de tipo:
- TEXTO (o CADENA)
- NUMÉRICO
- ENTERO
- REAL (o NÚMERO)
- BOOLEANO
- LISTA XML
- OBJETO
TEXTO (o CADENA)
Una columna con afinidad TEXT o STRING almacena todos los datos mediante clases de almacenamiento NULL, TEXT o BLOB. Si se insertan datos con afinidad de TEXTO en una columna, se convierten a formato de texto antes de almacenarse.
NUMÉRICO
Una columna con afinidad NUMERIC contiene valores que utilizan las clases de almacenamiento NULL, REAL o INTEGER. Cuando se insertan datos de texto en una columna NUMÉRICA, se intenta convertirlos en un número entero o real antes de almacenarlos. Si la conversión tiene éxito, el valor se almacena utilizando la clase de almacenamiento INTEGER o REAL (por ejemplo, el valor "10.05" se convierte a la clase de almacenamiento REAL antes de almacenarse). Se produce un error si no se puede realizar la conversión. No se realiza un intento de convertir un valor nulo. El valor recuperado de una columna NUMERIC se devuelve como una instancia del tipo numérico más específico en el que se ajusta el valor. En otras palabras, si el valor es un entero positivo o 0, se devuelve como una instancia de uint. Si representa un entero negativo, se devuelve como una instancia de int. Y finalmente, si tiene una parte decimal (no un número entero), entonces se devuelve como una instancia de Número.
ENTERO
Una columna de afinidad INTEGER se comporta como una columna de afinidad NUMERIC, con una excepción. Si el valor que se almacena es un valor real (como una instancia de Número) de la parte de punto flotante, o si el valor es texto que se puede convertir en un valor de punto flotante real, se convierte en un número entero y se almacena con el INTEGER clase de almacenamiento. Se produce un error al intentar almacenar un valor real con una parte después del punto flotante.
REAL (o NÚMERO)
Una columna de afinidad REAL o NUMÉRICA se comporta como una columna de afinidad NUMÉRICA, sin embargo, los valores enteros se ven obligados a convertirse a una representación de punto flotante. El valor de una columna REAL siempre se devuelve desde la base de datos como una instancia de número.
BOOLEANO
Una columna con afinidad BOOLEAN almacena valores verdaderos (verdadero) o falsos (falso). La columna BOOLEAN toma un valor que es una instancia booleana de ActionScript o JavaScript. Cuando el código intenta almacenar un valor de cadena, una cadena que es más larga que cero se considera "verdadera" y un valor de cadena vacío se considera "falso". Si el código intenta almacenar datos numéricos, cualquier valor distinto de cero se almacena como "verdadero" y 0 como "falso". Cuando se recupera un valor booleano mediante una declaración SELECT, se devuelve como una instancia booleana. Los valores que no son NULL se almacenan utilizando la clase de almacenamiento INTEGER (0 para "falso" y 1 para "verdadero") y se convierten en objetos booleanos durante la recuperación de datos.
FECHA
Una columna con afinidad DATE almacena valores de fecha y hora. Una columna FECHA puede tomar valores que son instancias de Fecha de ActionScript o Fecha de JavaScript. Si intenta almacenar un valor de cadena en una columna FECHA, el tiempo de ejecución intentará convertirlo a una fecha juliana. Se produce un error si no se puede realizar la conversión. Si el código intenta almacenar un valor numérico, int o uint, el intento de validación de datos falla y el valor se considera un valor de fecha juliana válido. Cuando recupera un valor de FECHA mediante una instrucción SELECT, se convierte automáticamente en una instancia de Fecha. Los valores de FECHA se almacenan como valores de fecha juliana utilizando la clase de almacenamiento REAL, por lo que los operadores de clasificación y comparación funcionan como se esperaba.
XML o lista XML
Una columna de afinidad XML o XMLLIST contiene estructuras XML. Cuando el código intenta almacenar datos en una columna XML mediante el parámetro SQLStatement, el tiempo de ejecución intentará convertir y validar el valor mediante la función XML() o XMLList() de ActionScript. Se produce un error si el valor no se puede convertir a XML válido. Al intentar almacenar datos utilizando un valor de texto SQL literal (por ejemplo, INSERTAR EN (col1) VALORES (" XML no válido (sin etiqueta de cierre) ") ), el valor no se analiza ni valida porque su forma se considera válida. Si un se almacena un valor no válido, luego devuelve un objeto XML vacío cuando se recupera. El valor de datos XML y datos XMLLIST se almacena utilizando la clase de almacenamiento TEXT o NULL.
OBJETO
Una columna con afinidad de OBJECT contiene objetos ActionScript o JavaScript complejos, incluidas instancias de la clase Object, así como instancias de subclases de Object, como instancias de Array, e incluso instancias de clases personalizadas. Los datos de la columna OBJECT se serializan en formato AMF3 y se almacenan mediante la clase de almacenamiento BLOB. Cuando se recupera un valor, se deserializa de AMF3 y se devuelve como una instancia de la clase tal como se almacenó. Tenga en cuenta que algunas clases de ActionScript, especialmente los objetos de presentación, se pueden deserializar como instancias de su tipo de datos original. Antes de guardar una instancia de una clase personalizada, debe registrar el alias de la clase mediante el método flash.net.registerClassAlias() (o en Flex agregando metadatos a la declaración de la clase). Además, antes de recuperar dichos datos, debe registrar el mismo alias para la clase. Todos los datos que no se pueden deserializar correctamente porque la clase no se puede deserializar inicialmente, o el alias de la clase falta o es incoherente, se devuelven como un objeto anónimo (una instancia de la clase Object) con propiedades y valores que coinciden con la instancia almacenada originalmente. .
NINGUNO
Una columna con afinidad NINGUNA no distingue entre clases de almacenamiento. No se realiza ningún intento de conversión de datos antes de la inserción.
Definición de similitud
La afinidad del tipo de columna está determinada por el tipo declarado de la columna en la sentencia CREATE TABLE. Las siguientes reglas se aplican cuando se define un tipo.
- Si el tipo de datos de una columna contiene cualquiera de las cadenas "CHAR", "CLOB", "STRI" o "TEXT", entonces la columna tiene afinidad TEXT/STRING. Tenga en cuenta que el tipo VARCHAR contiene la cadena "CHAR" y se le asigna la afinidad TEXT.
- Si el tipo de datos de la columna contiene cadenas "BLOB" o no se especifica ningún tipo de datos, entonces la columna no tiene afinidad NINGUNA.
- Si el tipo de datos de una columna contiene la cadena "XMLL", la columna tiene afinidad XMLLIST.
- Si el tipo de datos es una cadena "XML", la columna tiene afinidad XML.
- Si el tipo de datos contiene la cadena "OBJE", entonces la columna tiene afinidad de OBJETO.
- Si el tipo de datos contiene la cadena "BOOL", la columna tiene la afinidad BOOLEAN.
- Si el tipo de datos contiene la cadena "FECHA", la columna tiene afinidad con FECHA.
- Si el tipo de datos contiene la cadena "INT" (incluido "UINT"), se le asigna la afinidad INTEGER.
- Si el tipo de datos de una columna contiene cualquiera de las cadenas "REAL", "NUMB", "FLOA" o "DOUB", entonces la columna tiene afinidad REAL/NUMBER.
- En caso contrario, la similitud será NUMÉRICA.
- Si la tabla se crea mediante la instrucción CREATE TABLE t AS SELECT..., entonces no se especifica ningún tipo de datos para todas las columnas y se les asigna ninguna afinidad.
Tipos de datos y operadores de comparación
Operadores de comparación binarios admitidos = ,< , <= , >= y != , así como el operador de prueba de pertenencia especificado, el operador IN y el operador de comparación ternario BETWEEN. Consulte la sección para obtener detalles sobre estos operadores.
El resultado de la comparación depende de las clases de almacenamiento de los dos valores comparados. Al comparar dos valores, se aplican las siguientes reglas.
- Un valor con una clase de almacenamiento NULL se considera menor que cualquier otro valor (incluido otro valor con una clase de almacenamiento NULL).
- Un valor INTEGER o REAL es menor que cualquier valor TEXT o BLOB. Al comparar un valor INTEGER o REAL con otro valor INTEGER o REAL, se realiza una comparación numérica.
- El valor de TEXTO es menor que el valor de BLOB. Al comparar dos valores de TEXTO, se realiza una comparación binaria.
- Al comparar dos valores BLOB, el resultado siempre está determinado por la comparación binaria.
Al realizar comparaciones binarias entre clases de almacenamiento de números y texto, la base de datos intenta convertir los valores (si es necesario) antes de realizar la conversión. Al comparar clases de almacenamiento de números y texto, se aplican las siguientes reglas (Nota: el término expresión El utilizado en las siguientes reglas incluye cualquier expresión escalar SQL o literal que no sea un valor de columna. Por ejemplo, si X e Y.Z representan nombres de columna, +X e +Y.Z se consideran expresiones):
- Al comparar un valor de columna con el resultado de una expresión, la similitud de la columna se aplica al resultado de la expresión antes de realizar la comparación.
- Al comparar dos valores de columna, si una columna tiene afinidad INTEGER, REAL o NUMERIC y la otra no, la afinidad NUMERIC se aplica a cualquier valor con clase de almacenamiento TEXTO recuperado de una columna no NUMÉRICA.
- Al comparar los resultados de dos expresiones, no se produce ninguna conversión. Los resultados se comparan "tal cual". Al comparar una cadena con un número, este último siempre es menor que la cadena.
El operador ternario BETWEEN siempre se convierte como equivalente a una expresión binaria. Por ejemplo, a ENTRE b Y c se convierte en a >= b Y a<= c , даже если это означает, что разные сходства применяются к a при каждом сравнении, необходимом для вычисления выражения.
Expresiones como a IN (SELECT b ....) siguen las tres reglas enumeradas anteriormente para la comparación binaria, es decir, son lo mismo que a = b . Por ejemplo, si b es un valor de columna y a es una expresión, la similitud de b se aplica a a antes de cualquier comparación. La expresión a IN (x, y, z) se convierte en a = +x O a = +y O a = +z . Los valores a la derecha del operador IN (en este ejemplo, los valores x, y y z) se consideran expresiones, incluso si son valores de columna. Si el valor a la izquierda del operador IN es una columna, se usa la afinidad para esa columna. Si el valor es una expresión, no se realiza ninguna conversión.
El orden en que se realizan las comparaciones también puede verse afectado por la cláusula COLLATE. Consulte la sección para obtener más información.
Tipos de datos y operadores matemáticos
Para cada uno de los operadores matemáticos admitidos * , / , % , + y -, se aplica similitud numérica a cada operando antes de evaluar la expresión. Si algún operando no se puede convertir con éxito a una clase de almacenamiento NUMERIC, la expresión se evalúa como NULL.
Cuando se utiliza el operador de concatenación || cada operando se convierte en una clase de almacenamiento de TEXTO antes de que se evalúe la expresión. Si algún operando no se puede convertir a una clase de almacenamiento NUMERIC, la expresión se evalúa como NULL. La imposibilidad de convertir un valor puede ocurrir en dos casos: si el valor del operando es NULL, o si es un objeto BLOB con una clase de almacenamiento diferente a TEXT.
Tipos de datos y clasificación
Al ordenar valores usando la cláusula ORDER BY, la clase de almacenamiento NULL se coloca primero. A esto le siguen los valores INTEGER y REAL en orden numérico, seguidos de los valores TEXT en orden binario, o según el tipo especificado (BINARY o NOCASE). Terminar la lista de valores BLOB en orden binario. No se realiza ninguna conversión de clase de almacenamiento antes de la clasificación.
Tipos de datos y agrupación
Cuando agrupa valores utilizando la cláusula GROUP BY, los valores con diferentes clases de almacenamiento se consideran diferentes. Las excepciones son los valores INTEGER y REAL, que se consideran iguales si sus números son equivalentes. La cláusula GROUP BY no hace que se aplique afinidad a ningún valor.
Tipos de datos y sentencias SELECT compuestas
Las instrucciones SELECT compuestas UNION , INTERSECT y EXCEPT realizan comparaciones de valores implícitos. La similitud se puede aplicar a cada valor antes de realizar estas comparaciones. La misma afinidad (si la hay) se aplica a todos los valores que se pueden devolver en una sola columna del conjunto de resultados de una instrucción SELECT compuesta. La afinidad aplicada es la afinidad de la columna devuelta por el primer componente de la instrucción SELECT que tiene un valor de columna (en lugar de algún otro tipo de expresión) en esa posición. Si, para una columna dada en una declaración SELECT compuesta, ninguno de los componentes de la declaración SELECT devuelve un valor de columna, la similitud no se aplica a los valores en esa columna antes de que se comparen.
Símbolos utilizados en este documento
Las siguientes convenciones se han utilizado en las definiciones de expresiones de este documento.
- caso de texto
- MAYÚSCULAS: las palabras clave literales de SQL se escriben en mayúsculas
- minúsculas: los términos de marcador de posición o los nombres de oraciones se escriben en minúsculas
- Símbolos de definición
- ::= - denota la definición de una oración o expresión
- Agrupación y personajes alternativos
- | - el carácter de barra de avance se usa entre opciones alternativas y se puede leer como "o"
- — los elementos entre corchetes son opcionales; los corchetes pueden encerrar un solo elemento o un conjunto de elementos alternativos
- () - paréntesis que encierran alternativas (un conjunto de elementos separados por caracteres de barra hacia adelante) denota un grupo de elementos requeridos, es decir, un conjunto de elementos que son valores posibles de un solo elemento requerido
- cuantificadores
- + - un signo más después de un elemento entre paréntesis significa que el elemento que lo precede puede aparecer 1 o más veces
- * - un carácter de asterisco después de un elemento entre corchetes significa que el elemento que lo precede (entre corchetes) puede aparecer 0 o más veces
- Caracteres literales
- * - Un carácter de asterisco en el nombre de una columna o entre paréntesis después del nombre de una función indica un carácter de asterisco, no un cuantificador de "0 o más".
- . - el símbolo de punto representa el punto del literal
- , - el símbolo de coma representa la coma del literal
- () es un par de paréntesis que encierran una sola cláusula o elemento para indicar que los paréntesis son caracteres de paréntesis literales obligatorios.
- Otros símbolos. Si no hay otras designaciones, el resto de los caracteres representan los caracteres correspondientes del literal