Диагностика и устранение неисправностей при работе в локальной сети. Устранения неполадок с сетевыми подключениями
Отправить свою хорошую работу в базу знаний просто. Используйте форму, расположенную ниже
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Размещено на http://www.allbest.ru
Министерство образования Московской области
ГБОУ СПО МО Подмосковный колледж «Энергия»
КУРСОВАЯ РАБОТА
по предмету: Компьютерные сети
тема работы: «Диагностика и устранение неисправностей при работе в локальной сети»
Студент ___3ИС-1-11
Е.А. Мал я ров
Специальность _230401
«Информационные системы (по отра с лям)
Московская область
2014г.
- Введение
- Глава 1. Теоретическая часть. Диагностика локальных сетей
- 1.1. Необходимость создания и применения средств и систем диагностики сетей
- 1.2. Инструменты диагностики
- 2.1. Общая модель решения проблемы поиска неисправностей
- 2.2. Организация диагностики компьютерной сети
- 2.3. Методика упреждающей диагностики
- 2.4. Организация процесса диагностики
- Глава 3. Практическая часть. Устранение неисправностей в локальной сети
- 3.1. Общие положения
- 3.2. Некоторые частные примеры устранения неполадок сети
- 3.3. Коды ошибок в локальной сети и их устранение
- Заключение
- Литература
- Приложение
Введение
За последние десять лет резко возросла потребность в сетевых ресурсах. В современном мире успешная деятельность любой компании во многом зависит от бесперебойного функционирования применяемой в ней сети, поэтому любое нарушение в работе сети считается недопустимым. В связи с этим задача поиска неисправностей в сети стала одним из самых важных направлений работы на многих предприятиях.
В связи с общим усложнением сетевой среды увеличивается вероятность проявления проблем нарушения связности и снижения производительности в объединенных сетях, но при этом первопричины таких проблем подчас очень сложно обнаружить.
Нарушения функционирования объединенных сетей характеризуются определенными признаками. Такие признаки могут быть общими (например, нельзя получить доступ к конкретным серверам с клиентских компьютеров) или более определенными (например, отсутствие информации о маршрутах в таблице маршрутизации). Анализ каждого признака неисправности, проводимый с помощью специальных инструментальных средств и методов поиска неисправностей, может выявить одну или несколько причин или проблем. А каждую причину неисправности после ее распознавания можно устранить путем реализации решения, состоящего из ряда действий.
Системный администратор, специалист на которого зачастую распространяются функции по ведению диагностики и устранения неполадок, должен начинать изучать особенности подведомственной сети уже на фазе её формирования, чтобы знать схему и детальное описание полной конфигурации программного обеспечения с указанием параметров и интерфейсов.
Глава 1 . Диагностика локальных сетей
1.1 Необходимость создания и применения средств и систем ди а гностики сетей
Несмотря на множество способов и инструментов обнаружения и устранения неполадок в узкогрупповых сетях, решительность в данном вопросе сетевых администраторов все еще остается весьма неустойчивой. Узкогрупповые или корпоративные сети все чаще содержат волоконно-оптические и беспроводные компоненты, использование которых делает необоснованным употребление традиционных технологий, предназначенных для общепринятых медных кабелей. Плюс при скорости свыше 100 Мбит/с устоявшиеся подходы к распознаванию проблемы часто прекращают работать, если среда передачи это обычный медный кабель в том числе. Тем не менее, возможно, наиболее основательным изменением в корпоративных сетевых технологиях, с которым пришлось встретится администраторам, стал неминуемый переход от сетей Ethernet с разделяемой средой передачи к коммутируемым сетям, где в качестве коммутируемых сегментов зачастую используются отдельные серверы либо рабочие станции.
Вместе с тем, по мере осуществления технологических перемен некоторые предыдущие проблемы решились автоматически. Коаксиальный кабель, в котором найти электротехнические неисправности было тяжелее, чем в случае витой пары, становится малоупотребительным в корпоративных средах. Сети Token Ring, главным затруднением которых была их различность с Ethernet, со временем заменяются коммутируемыми сетями Ethernet. Вызывающие многочисленные сообщения об ошибках протоколов сетевого уровня протоколы, такие, как SNA, DECnet и AppleTalk, замещаются протоколом IP. Сам же стек протоколов IP стал более стабильным и легким для поддержки, что доказывают миллионы потребителей и миллиарды страниц Web в Internet. Даже злостным оппонетнам Microsoft приходится признаться, что подключение нового клиента Windows к Internet значительно проще и надежнее установки применявшихся ранее стеков TCP/IP сторонних поставщиков и отдельного программного обеспечения коммутируемого доступа.
Насколько многочисленные современные технологии ни усложняют обнаружение неполадок и координацию производительностью сетей, положение могло бы оказаться еще сложнее, если бы технология АТМ получила широкое расширение на уровне ПК. Своё положительное значение дало и то, что в конце 90-х, ещё не получив признания, были отринуты и некоторые другие высокоскоростные технологии обмена данными, наряду с Token Ring с пропускной способностью 100 Мбит/с, 100VG-AnyLAN и усовершенствованные сети ARCnet. Наконец, в США был отклонен очень сложный стек протоколов OSI (который узаконен некоторыми правительствами европейских государств).
Стуктурно-иерархическая система корпоративных сетей с магистральными каналами Gigabit Ethernet и выделенными портами коммутаторов на 10 либо 100 Мбит/с для отдельных пользовательских систем, дала возможность увеличения максимальной пропускной способности, потенциально доступной клиентам минимум в 10--20 раз. Безусловно, в большинстве корпоративных сетей существуют непростые моменты на уровне серверов или маршрутизаторов доступа, ввиду приходящейся на отдельного пользователя пропускной способности существенно меньшей, чем 10 Мбит/с. Потому замена порта концентратора с пропускной способностью 10 Мбит/с на выделенный порт коммутатора на 100 Мбит/с для конечного узла далеко не всегда приводит к значительному увеличению скорости. Как бы то ни было, если учесть, что стоимость коммутаторов в последнее время снизилась, а на большинстве предприятий и организаций проложен кабель Категории 5, поддерживающий технологию Ethernet на 100 Мбит/с, и установлены сетевые карты, способные работать на скорости 100 Мбит/с сразу после перезагрузки системы, то становится очевидно, почему так нелегко устоять перед искушением усовершенствований. В традиционной локальной сети с разделяемой средой передачи анализатор протоколов или монитор может исследовать весь трафик данного сегмента сети.
См. Приложение 1. - Традиционная локальная сеть с разделяемой средой передачи и анализатором протоколов.
Хотя достоинство коммутируемой сети в производительности иногда почти незначительно, генерализация коммутируемых архитектур имело негативные итоги для традиционных средств диагностики. В крайне сегментированной сети анализаторы протоколов имеют способность видеть только одноадресный трафик на отдельном порту коммутатора, в отличие от сети прежней топологии, где они могли досконально исследовать любой пакет в домене коллизий. В таких условиях традиционные способы мониторинга не могут собрать статистику по всем «диалогам», так как каждая «переговаривающаяся» пара оконечных точек пользует, в итоге, свою собственную сеть. сеть компьютерный диагностика неисправность
См. Приложение 2. Коммутируемая сеть. В коммутируемой сети анализатору протоколов в одной точке доступен только единственный сегмент, в случае неспособности коммутатора зеркально отобразить одновременно несколько портов.
Для контроля над сильно сегментированными сетями производители коммутаторов предлагают множество средств для восстановления полной «визуальности» сети, но на этом пути сохраняется немало вопросов. В поставляемых в данное время коммутаторах обычно поддерживается «зеркальное отображение» портов, в то время как трафик одного из них дублируется на ранее незадействованный порт, к которому подключается монитор или анализатор.
Известно, что «зеркальное отображение» обладает рядом недочетов. Во-первых, в данный момент времени виден только один порт, поэтому выявить неполадки, распространяющиеся сразу на несколько портов, проблематично. Во-вторых, зеркальное отражение может привести к снижению производительности коммутатора. В-третьих, на зеркальном порту обычно не воспроизводятся сбои физического уровня, а порой даже теряются обозначения виртуальных локальных сетей. Плюс ко всему, во многих случаях не могут в достаточно полной мере зеркально отображаться полнодуплексные каналы Ethernet.
Частичное решение при анализе агрегированных параметров трафика приобретает применение возможностей мониторинга агентов mini-RMON, строеных в каждый порт большинства коммутаторов Ethernet. Но агенты mini-RMON не поддерживают группу объектов Capture из спецификации RMON II, которые обеспечивают полнофункциональный анализ протоколов, и они позволяют оценить степень использования ресурсов, количество ошибок и объем многоадресной рассылки.
Некоторые недчеты технологии зеркального отображения могут быть преодолены установкой «пассивных ответвителей». Это устройства, с заранее устанавливаемым Y-коннектором, позволяющие отслеживать с помощью анализаторов протокола реальный сигнал.
Следующей насущной проблемой, является проблема со спецификой оптики. Обычно используется специализированное оборудование диагностики оптических сетей только для решения проблем с оптическими кабелями. Стандартное программное обеспечение управления устройствами на базе SNMP или интерфейса командной строки способно выявить проблемы на коммутаторах и маршрутизаторах с оптическими интерфейсами. И только немногие сетевые специалисты сталкиваются с необходимостью проводить диагностику устройств SONET.
Если взять во внимание волоконно-оптические кабели, то причин для возникновения возможных неполадок в них значительно меньше, чем при использовании медного кабеля. Оптические сигналы не вызывают перекрёстных помех. Перекрёстные помехи появляются от того, что сигнал одного проводника индуцирует сигнал на другом, что наиболее усложняет набор диагностическое оборудования для медного кабеля. Оптические кабели нечувствительны к электромагнитным шумам и индуцированным сигналам.
Оптическая мощность сигнала в данной точке на самом деле является единственной переменной, которую требуется измерять при поиске неисправностей в оптических сетях. Если же возможно определить потери сигнала на всем протяжении оптического канала, то появляется шанс идентифицировать практически любую проблему. Недорогие дополнительные модули для тестеров медного кабеля позволяют проводить оптические измерения.
Предприятиям и организациям, которые развернули крупную оптическую инфраструктуру и обслуживают её самостоятельно, может понадобиться оптический временный рефлектометр (Optical Time Domain Reflecto-meter, OTDR), выполняющий те же функции для оптического волокна, что и рефлектометр для медного кабеля (Time Domain Reflectometer, TDR). Этот прибор действует подобно радару: он посылает импульсные сигналы по кабелю, анализирует их отражения, на основании которых выявляет повреждения в проводнике или другую аномалию, затем сообщает эксперту, в каком месте кабеля возможно отыскать источник проблемы.
Поставщики кабельных соединителей и разъемов упростили процессы терминирования и разветвления оптического волокна, но по-прежнему для этого требуется некоторый уровень специальных навыков, потому при рациональной политике предприятие с развитой оптической инфраструктурой будет вынуждено обучать своих сотрудников. В кабельной сети всегда существует возможность физического повреждения кабеля в результате неожиданного происшествия.
Во время диагностики локальных беспроводных сетей стандарта 802.11b также возникают определенные проблемы. Фактически диагностика проста поскольку беспроводная среда передачи информации распределяется между всеми обладателями радиоустройств клиентов. Компания Sniffer Technologies впервые предложила решение для анализа протоколов таких сетей с пропускной способностью до 11 Мбит/с. Впоследствии большинство лидирующих поставщиков анализаторов предоставили аналогичные системы.
Качество клиентских беспроводных соединений далеко от стабильного, отличие от концентратора Ethernet с проводными соединениями. Микроволновые радиосигналы, которые используются во всех вариантах локальной передачи, слабы и непредсказуемы порой. Незначительные изменения положения антенны могут серьезно сказаться на качестве соединения. Точка доступа беспроводной локальной сети снабжается консолью управления устройствами, и это подчас довольно действенный и скоростной метод диагностики против посещения клиентов беспроводной сети для наблюдения за пропускной способностью и условиями возникновения ошибок портативным анализатором.
Известно, что операторы беспроводных корпоративных сетей должны препятствовать развертыванию чрезмерно открытых систем, где каждый пользователь в зоне действия сети, обладающий совместимой интерфейсной картой, получает доступ к любому информационному кадру системы. Протокол безопасности беспроводных сетей WEP (Wired Equivalent Privacy) обеспечивает пользовательскую аутентификацию, как гарантию целостности и шифрования данных, но из-за совершенной системы безопасности усложняется анализ причин неполадок сети. В защищенных сетях с поддержкой WEP специалисты по диагностике должны иметь ключи или пароли, защищающие информацию и контролирующие доступ к системе. При доступе в режиме приема всех пакетов анализатор протоколов сможет видеть все заголовки кадров, однако, содержащаяся в них информация будет бессмысленной, без наличия ключей.
При диагностике виртуальных частных сетей с удаленным доступом, или туннелированных каналов, возникают проблемы аналогичные возникающим при анализе беспроводных сетей с шифрованием. Причину неисправности определить непросто, если трафик не проходит через туннелированный канал. Причиной может служить ошибка аутентификации, затор в общедоступной зоне Internet, поломка на одной из оконечных точек, например. Будет пустой тратой сил попытка использования анализатора протоколов для выявления высокоуровневых ошибок в туннелированном трафике, так как содержание данных, и заголовки прикладного, транспортного и сетевого уровней зашифрованы. В принципе, все меры, принимаемые в целях повышения уровня безопасности корпоративных сетей, обычно только затрудняют выявление неисправностей и проблем производительности. Межсетевые экраны, proxy-серверы и системы выявления вторжений могут дополнительно осложняют локализацию неисправностей.
В результате, проблема диагностики компьютерных сетей является актуальной, а диагностирование неисправностей является задачей управления. Для большинства критически важных систем, проведение продолжительных по времени восстановительных работ не допустимо, потому единственным решением видится использование резервных устройств и процессов, которые немедленно после возникновения сбоев способны взять на себя необходимые функции. На ряде предприятий сети имеют резервный компонент на случай сбоя основного, т. е. nх2 компонентов, где n -- количество основных компонентов, необходимое для обеспечения приемлемой производительности. Если среднее время восстановления (Mean Time To Repair, MTTR) достаточно велико, то может понадобиться еще большая избыточность компонентов. Всё дело в том, что время устранения неисправности предсказать нелегко, и значительные затраты в течение непредсказуемого периода восстановления являются признаком плохого управления.
Резервирование для менее важных систем может оказаться экономически неоправданным, тогда будет целесообразнее вложить средства в наиболее эффективные инструменты, для того чтобы ускорить процесс диагностики и устранения неисправностей. Вместе с тем, поддержку определенных систем возможно доверить сторонним специалистам, привлекая по контракту или пользуясь возможностями внешних центров обработки данных или обращаясь к провайдерам услуг по сопровождению приложений (Application Service Providers, ASP) или провайдерам услуг управления
1.2 Инструменты диагностики
Главной функцией инструмента диагностики служит обеспечение визуального описания существующего состояния сети. Привычно производителями поставляются инструменты визуализации приблизительно соответствующие уровням модели OSI.
Целесообразно начать рассмотрение с физической плоскости. Для решения проблемы на этом уровне и в электрических или оптических средах передачи данных существуют кабельные тестеры и специализированные инструменты - рефлектометры (Time Domain Reflectometers, TDRs). За более чем 15 лет активного развития корпоративных локальных сетей в результате образования потребности профессиональных сетевых интеграторов в кабельных тестерах реализовано множество функций; примером может служить выполнение автоматизированных тестовых последовательностей с возможностью печати сертификационных документов на основании результатов теста. Тем не менее, в сетях Ethernet с пропускной способностью 10 Мбит/с порой допускаются некоторые вольности в отношении качества их прокладки; технологии 100BaseT и Gigabit Ethernet с медным кабелем намного требовательнее. Как результат, современные кабельные тестеры весьма многосложны.
В число основных поставщиков кабельных тестеров входят компании Fluke Networks, Microtest, Agilent, Acterna и Datacom Textron.
Для диагностики проблем на физическом плане уместно использование следующих средств:
1) Разъем-заглушка (Hardware loopback) - это разъем, замыкающий выходную линию на входную, это компьютеру передавать данные самому себе. Разъем-заглушка используется при диагностике оборудования.
2) Расширенный тестер кабеля (Advanced cable tester; Cable tester) - специальное средство для ведения мониторинг трафика сети и отдельного компьютера и выявления определенных видов ошибок, неисправного кабеля или сетевой платы.
3) Рефлектометр (Time-domain reflectometer) - устройство, для выявления дефектов кабельных линий локационным (рефлектометрическим) методом. Рефлектометр посылает по кабелю короткие импульсы, обнаруживает и классифицирует разрывы, короткие замыкания и другие дефекты, плюс, измеряет длину кабеля и его волновое сопротивление и выдает результаты на экран.
4) Тоновый генератор (Tone generator) - прибор, генерирующий в кабеле переменный или непрерывный тоновый сигнал, по которому тоновый определитель проверяет целостность и качество кабеля. Тоновый определитель - прибор, позволяющий определить целостность и качество кабеля, на основе анализа сигналов, испускаемых тоновым генератором.
5) Цифровой вольтметр (Digital voltmeter) - электронное измерительное устройство общего назначения. Вольтметр позволяет измерять напряжение тока, проходящего через резистор, и определять целостность сетевых кабелей.
Для разрешения неполадок канального, сетевого и транспортного уровней традиционным инструментом являются анализаторы протоколов (Protocol analyzer) . Это средства для сбора статистики о работе сети и определением частоты ошибок, позволяют отслеживать и записывать состояния объектов сети. Порой имеют в своем составе встроенный рефлектометр.
Недорогие анализаторы обычно создаются на основе серийно выпускаемых портативных ПК с использованием стандартных сетевых карт с поддержкой режима приема всех пакетов. Основной недостаток анализаторов протоколов, состоит в том, некоторые виды неполадок на канальном уровне для них остаются невидимыми. Кроме того, они не позволяют выявить проблемы физического уровня в электрических или оптических кабелях. Вместе с тем, со временем в анализаторах протоколов появилась возможность исследования неполадок прикладного уровня, включая транзакции баз данных.
В число лидирующих поставщиков анализаторов протоколов локальных сетей входят Network Associates/Sniffer Technologies, Shomiti, Acterna (прежнее название WWG), Agilent, GN Nettest, WildPackets и Network Instruments.
Третьим диагностическим инструментом является зонд или монитор. Монитор сети (Network monitor) - это программно-аппаратное устройство по отслеживанию сетевого трафика и проверки пакетов на уровне кадров, собирающее информацию о типах пакетов и ошибках.
Эти устройства обычно подключаются на постоянной основе к сети и функционируют в соответствии со спецификациями удаленного мониторинга RMON и RMON II. Протокол RMON описывает метод сбора статистической информации об интенсивности трафика, ошибках, об основных источниках, потребителях трафика. В протоколе RMON II предусмотрена возможность сбора пакетов или кадров с сохранением их в буфер, данная функция используется на первом этапе анализа протоколов. С другой стороны, практически любой современный анализатор протоколов способен обрабатывать больше статистической информации, чем зонд RMON.
Между функциями анализаторов протоколов и зондами RMON не удастся провести четких разграничений. Производители анализаторов рекомендуют устанавливать агенты мониторинга и сбора данных по всей большой сети, а пользователи стремятся, чтобы эти распределенные агенты были совместимы с международным стандартом RMON, а не с собственным форматом анализатора. До настоящего времени поставщики зондов RMON по-прежнему продолжают разрабатывать свои собственные протоколы для программного обеспечения декодирования и экспертного анализа, однако инструменты мониторинга и сбора данных, по всей вероятности, будут объединяться. С другой стороны поставщики анализаторов протоколов считают, что их программное обеспечение не предназначено для решения специфических задач RMON, таких, как анализ трафика и составление отчетов о производительности приложений.
Еще одним инструментом диагностики являются интегрированные диагностические средства. Производители диагностического оборудования объединили функции всех перечисленных традиционных инструментов в портативных устройствах для обнаружения распространенных неисправностей на нескольких уровнях OSI. Например, некоторые из этих устройств осуществляют проверку основных параметров кабеля, отслеживают количество ошибок на уровне Ethernet, обнаруживают дублированные IP-адреса, осуществляют поиск и подключение к серверам Novell NetWare, а также отображают распределение в сегменте протоколов третьего уровня.
Среди программных средств диагностики компьютерных сетей, можно выделить специальные системы управления сетью (Network Management Systems) - централизованные программные системы, которые собирают данные о состоянии узлов и коммуникационных устройств сети, а также данные о трафике, циркулирующем в сети. Эти системы не только осуществляют мониторинг и анализ сети, но и выполняют в автоматическом или полуавтоматическом режиме действия по управлению сетью - включение и отключение портов устройств, изменение параметров мостов адресных таблиц мостов, коммутаторов и маршрутизаторов и т.п. Примерами систем управления могут служить популярные системы HPOpenView, SunNetManager, IBMNetView.
Средства управления системой (System Management) выполняют функции, аналогичные функциям систем управления, но по отношению к коммуникационному оборудованию. Вместе с тем, некоторые функции этих двух видов систем управления могут дублироваться, например, средства управления системой могут выполнять простейший анализ сетевого трафика.
Экспертные системы. Этот вид систем аккумулирует человеческие знания о выявлении причин аномальной работы сетей и возможных способах приведения сети в работоспособное состояние. Экспертные системы часто реализуются в виде отдельных подсистем различных средств мониторинга и анализа сетей: систем управления сетями, анализаторов протоколов, сетевых анализаторов. Простейшим вариантом экспертной системы является контекстно-зависимая help-система. Более сложные экспертные системы представляют собой так называемые базы знаний, обладающие элементами искусственного интеллекта. Примером такой системы является экспертная система, встроенная в систему управления Spectrum компании Cabletron.
Глава 2. Организация диагностики компьютерной сети
2.1 Общая модель решения проблемы поиска неисправн о стей
В процессе поиска неисправностей в сетевой среде должен применяться систематический подход. Если поиск неисправностей ведется бессистемно, то могут непродуктивно затрачиваться ценные временные и материальные ресурсы, а иногда при этом положение даже ухудшается. В процессе устранения нарушений в работе сети необходимо определить конкретные признаки неисправности, выявить все потенциальные проблемы, которыми могут быть вызваны эти признаки, а затем систематически устранять все возможные причины проблем (от наиболее вероятных до наименее вероятных) до тех пор, пока все признаки неисправности не исчезнут.
На Приложении 1 показана блок - схема общей модели решения проблемы поиска неисправностей. Эта блок - схема не является жесткой схемой поиска неисправностей в объединенной сети, а может служить лишь основой, на которой формируется конкретный процесс устранения нарушений в работе, соответствующий конкретной сетевой среде (см. Приложения.)
Шаг 1. При анализе нарушения работы в сети четко сформулируйте проблему. Проблема должна быть определена как набор наблюдаемых признаков неисправностей и возможных причин. В процессе анализа проблемы необходимо определить общие признаки неисправности, а затем установить, какими причинами могли быть вызваны эти признаки. Например, предположим, что хост не отвечает на запросы к службам, поступающие от клиентов (признак неисправности). Возможными причинами этого может быть неправильная настройка конфигурации хоста, неисправные интерфейсные платы или отсутствие необходимых команд в конфигурации маршрутизатора.
Шаг 2. Соберите факты, которые позволят более точно установить возможные причины. Необходимо провести опрос всех заинтересованных пользователей, сетевых администраторов, руководителей и других специалистов, а также собрать информацию из таких источников, как системы управления сетью, трассировки анализаторов протокола, ознакомиться с результатами выполнения команд диагностики маршрутизатора или прочитать документацию к применяемой версии программного обеспечения.
Шаг 3. Изучите возможные проблемы с учетом собранных фактов. Накопленная вами информация позволит исключить некоторые потенциальные проблемы из списка подозреваемых. Например, полученные данные могут свидетельствовать о том, что аппаратное обеспечение работает нормально. Это позволит сосредоточиться на нарушениях в работе программного обеспечения. При любой возможности нужно стремиться сузить круг потенциальных проблем, чтобы можно было разработать эффективный план действий.
Шаг 4. Подготовьте план действий, охватывающий все оставшиеся потенциальные проблемы. Начните с наиболее вероятной неисправности и разработайте план, который предусматривает устранение только одной конкретной причины. Если план действий направлен на устранение только одной причины, он позволит найти искомое решение конкретной проблемы. Пытаясь одновременно устранить сразу несколько причин, также можно решить проблему, но при этом сложно определить, какое именно действие привело к устранению признаков неисправности, поэтому при повторном возникновении такой же проблемы в будущем поиск решения придется начать с самого начала.
Шаг 5. Осуществите план действий, тщательно выполняя каждый этап и проверяя, удалось ли устранить признаки неисправности.
Шаг 6. После внесения каждого изменения обязательно проконтролируйте результаты. Как правило, для этого должен применяться тот же метод сбора данных, как и на шаге 2 (в частности, при этом снова привлекайте к такой работе заинтересованных специалистов и используйте диагностические инструментальные средства).
Шаг 7. Проанализируйте полученные результаты, чтобы определить, решена ли проблема. В случае положительного ответа процесс поиска неисправности заканчивается.
Шаг 8. Если проблема не решена, разработайте план действий по устранению следующей менее вероятной проблемы из списка. Возвратитесь к шагу 4, снова вносите по одному изменению и повторяйте процесс до тех пор, пока проблема не будет решена.
2.2 Организация диагностики компьютерной сети
Существует несколько основных причин неудовлетворительной работы сети: дефекты активного оборудования, повреждения кабельной системы, перегруженность сетевых ресурсов, ошибки прикладного программного обеспечения. Часто можно столкнуться с тем, что одни дефекты сети скрывают, маскируют другие проблемы. И для того чтобы достоверно определить причину неудовлетворительной работы, локальную сеть подвергают комплексной диагностике. Комплексная диагностика предполагает следующие работы (этапы):
Выявление дефектов физического плана сети: системы электропитания активного оборудования, кабельной системы, наличия шума от внешних источников;
Измерение текущей загруженности канала связи, определение влияния величины загрузки канала на время реакции прикладного ПО;
Измерение числа коллизий в сети и выявление их причин;
Измерение числа ошибок передачи данных на уровне канала связи, выявление их причин;
Выявление дефектов архитектуры сети;
Измерение текущей загруженности сервера, определение влияния степени загруженности на время реакции прикладного ПО;
Выявление дефектов прикладного ПО, т.е. причыны неэффективного использования пропускной способности сервера и сети.
Мы остановимся подробнее на первых четырех этапах комплексной диагностики локальной сети, а именно на диагностике канального уровня сети, так как наиболее легко задача диагностики решается для кабельной системы. Как уже было рассмотрено во втором разделе, кабельная система сети полноценно может быть протестирована только специальными приборами - кабельным сканером или тестером. AUTOTEST на кабельном сканере позволит выполнить полный комплекс тестов на соответствие кабельной системы сети выбранному стандарту. При тестировании кабельной системы хотелось бы обратить внимание на два момента, тем более что о них часто забывают.
Режим AUTOTEST не позволяет проверить уровень шума создаваемого внешним источником в кабеле. Это может быть шум от сотового телефона, люминесцентной лампы, мощного копировального аппарата, силовой электропроводки и др. Для определения уровня шума кабельные сканеры снабжены, как правило, специальной функцией. В силу того, что кабельная система сети полностью проверяется только на этапе её инсталляции, а шум в кабеле может возникать непредсказуемо, то нет полной гарантии того, что шум проявится именно в период полномасштабной проверки сети на этапе ее инсталляции.
Для проверки сети кабельным сканером вместо активного оборудования к кабелю подключаются с одного конца - сканер, с другого - инжектор. После проверки кабеля сканер и инжектор отключаются, и подключается активное оборудование: сетевые платы, коммутаторы, концентраторы. Но нет полной гарантии, что контакт между активным оборудованием и кабелем будет столь же хорош, как между оборудованием сканера и кабелем. Довольно часто встречаются случаи, когда незначительный дефект вилки RJ-45 не проявляется при тестировании кабельной системы сканером, а обнаруживался впоследствии при диагностике сети анализатором протоколов. См. Приложение 3.
Диагностика сетевых устройств (или компонента сети) также имеет свои тонкости. При ее проведении применяют различные подходы. Выбор конкретного подхода зависит от того, что выбирается в качестве критерия хорошей работы устройства. Как правило, можно выделить три типа критериев и, следовательно, три основных подхода.
Первый основан на контроле текущих значений параметров, характеризующих работу диагностируемого устройства. Критериями хорошей работы устройства в этом случае являются рекомендации его производителя, или так называемые промышленные стандарты де-факто. Основными достоинствами указанного подхода являются простота и удобство при решении наиболее распространенных, но, как правило, относительно несложных проблем. Однако бывают случаи, когда даже явный дефект большую часть времени не проявляется, а дает о себе знать лишь при некоторых, относительно редких режимах работы и в непредсказуемые моменты времени. Обнаружить такие дефекты, контролируя только текущие значения параметров, весьма затруднительно.
Второй подход основан на исследовании базовых линий параметров (так называемых трендов), характеризующих работу диагностируемого устройства. Основной принцип второго подхода можно сформулировать следующим образом: “устройство работает хорошо, если оно работает так, как всегда”. На этом принципе основана упреждающая (proactive) диагностика сети, цель которой -- предотвратить наступление ее критических состояний. Противоположной упреждающей является реактивная (reactive) диагностика, цель которой не предотвратить, а локализовать и ликвидировать дефект. В отличие от первого, данный подход позволяет обнаруживать дефекты, проявляющиеся не постоянно, а время от времени. Недостатком второго подхода является предположение, что изначально сеть работала хорошо. Но “как всегда” и “хорошо” не всегда означают одно и то же.
Третий подход осуществляется посредством контроля интегральных показателей качества функционирования диагностируемого устройства (далее -- интегральный подход). Следует подчеркнуть, что с точки зрения методологии диагностики сети между первыми двумя подходами, которые будем называть традиционными, и третьим, интегральным, есть принципиальное различие. При традиционных подходах мы наблюдаем за отдельными характеристиками работы сети и, чтобы увидеть ее “целиком”, должны синтезировать результаты отдельных наблюдений. Однако мы не можем быть уверены, что при этом синтезе не потеряем важную информацию. Интегральный подход, наоборот, дает нам общую картину, которая в ряде случаев бывает недостаточно детальной. Задача интерпретации результатов при интегральном подходе, по существу, обратная: наблюдая целое, выявить, где, в каких частностях заключается проблема.
Из сказанного следует, что наиболее эффективен подход, совмещающий функциональность всех трех описанных выше подходов. Он должен, с одной стороны, основываться на интегральных показателях качества работы сети, но, с другой -- дополняться и конкретизироваться данными, которые получаются при традиционных подходах. Именно такая комбинация позволяет поставить точный диагноз проблемы в сети.
2.3 Методика упреждающей диагностики
Методика упреждающей диагностики заключается в следующем. Администратор сети должен непрерывно или в течение длительного времени наблюдать за работой сети. Такие наблюдения желательно проводить с момента ее установки. На основании этих наблюдений администратор должен определить, во-первых, как значения наблюдаемых параметров влияют на работу пользователей сети и, во-вторых, как они изменяются в течение длительного промежутка времени: рабочего дня, недели, месяца, квартала, года и т. д.
Наблюдаемыми параметрами обычно являются:
Параметры работы канала связи сети - утилизация канала связи, число принятых и переданных каждой станцией сети кадров, число ошибок в сети, число широковещательных и многоадресных кадров и т. п.;
Параметры работы сервера - утилизация процессора сервера, число отложенных (ждущих) запросов к диску, общее число кэш-буферов, число "грязных" кэш-буферов и т. п.
Зная зависимость между временем реакции прикладного ПО и значениями наблюдаемых параметров, администратор сети должен определить максимальные значения параметров, допустимые для данной сети. Эти значения вводятся в виде порогов (thresholds) в диагностическое средство. Если в процессе эксплуатации сети значения наблюдаемых параметров превысят пороговые, то диагностическое средство проинформирует об этом событии администратора сети. Такая ситуация свидетельствует о наличии в сети проблемы.
Наблюдая достаточно долго за работой канала связи и сервера, можно установить тенденцию изменения значений различных параметров работы сети (утилизации ресурсов, числа ошибок и т. п.). На основании таких наблюдений администратор может сделать выводы о необходимости замены активного оборудования или изменения архитектуры сети.
В случае появления в сети проблемы, администратор в момент ее проявления должен записать в специальный буфер или файл дамп канальной трассы и на основании анализа ее содержимого сделать выводы о возможных причинах проблемы.
2.4 Организация процесса диагностики
Не подвергая сомнению, важность упреждающей диагностики, приходиться констатировать, что на практике она используется редко. Чаще всего (хоть это и неправильно) сеть анализируется только в периоды ее неудовлетворительной работы. И обычно в таких случаях локализовать и исправить имеющиеся дефекты сети требуется быстро. Предлагаемую нами методику можно даже рассмотреть, как частный случай методики упреждающей диагностики сети.
Любая методика тестирования сети существенно зависит от имеющихся в распоряжении системного администратора средств. По мнению некоторых администраторов, в большинстве случаев необходимым и достаточным cредством для обнаружения дефектов сети (кроме кабельного сканера) является анализатор сетевых протоколов. Он должен подключаться к тому домену сети (collision domain), где наблюдаются сбои, в максимальной близости к наиболее подозрительным станциям или серверу
Если сеть имеет архитектуру с компактной магистралью (collapsed backbone) и в качестве магистрали используется коммутатор, то анализатор необходимо подключать к тем портам коммутатора, через которые проходит анализируемый трафик. Некоторые программы имеют специальные агенты или зонды (probes), устанавливаемые на компьютерах, подключенных к удаленным портам коммутатора. Обычно агенты (не путать с агентами SNMP) представляют собой сервис или задачу, работающую в фоновом режиме на компьютере пользователя. Как правило, агенты потребляют мало вычислительных ресурсов и не мешают работе пользователей, на компьютерах которых они установлены. Анализаторы и агенты могут быть подключены к коммутатору двумя способами.
При первом способе (см. Приложение 4.) анализатор подключается к специальному порту (порту мониторинга или зеркальному порту) коммутатора, если таковой имеется, и на него по очереди направляется трафик со всех интересующих портов коммутатора.
Если в коммутаторе специальный порт отсутствует, то анализатор (или агент) следует подключать к портам интересующих доменов сети в максимальной близости к наиболее подозрительным станциям или серверу (см. Приложение 5.). Иногда это может потребовать использования дополнительного концентратора. Данный способ предпочтительнее первого. Исключение составляет случай, когда один из портов коммутатора работает в полнодуплексном режиме. Если это так, то порт предварительно необходимо перевести в полудуплексный режим.
На рынке имеется множество разнообразных анализаторов протоколов - от чисто программных до программно-аппаратных. Несмотря на функциональную идентичность большинства анализаторов протоколов, каждый из них обладает теми или иными достоинствами и недостатками. В этой связи надо обратить внимание на две важные функции, без которых эффективную диагностику сети провести будет затруднительно.
Во-первых, анализатор протоколов должен иметь встроенную функцию генерации трафика Во-вторых, анализатор протоколов должен уметь "прореживать" принимаемые кадры, т. е. принимать не все кадры подряд, а, например, каждый пятый или каждый десятый с обязательной последующей аппроксимацией полученных результатов. Если эта функция отсутствует, то при сильной загруженности сети, какой бы производительностью ни обладал компьютер, на котором установлен анализатор, последний будет "зависать" и/или терять кадры. Это особенно важно при диагностике быстрых сетей типа Fast Ethernet и FDDI.
Предлагаемую методику мы будем иллюстрировать на примере использования чисто программного анализатора протоколов Observer компании Network Instruments - это мощный анализатор сетевых протоколов и средство для мониторинга и диагностики сетей Ethernet, беспроводных сетей стандарта 802.11 a/b/g, сетей Token Ring и FDDI. Observer позволяет в режиме реального времени измерять характеристики работы сети, осуществлять декодирование сетевых протоколов (поддерживается более 500 протоколов), создавать и анализировать тренды характеристик работы сети.
Рассмотрим поэтапно действия системного администратора для проведения диагностики сети в случае, когда прикладное программное обеспечение в сети Ethernet стало работать медленно, и необходимо оперативно локализовать и ликвидировать дефект.
Первый этап: Измерение утилизации сети и установление корреляции между замедлением работы сети и перегрузкой канала связи.
Утилизация канала связи сети - это процент времени, в течение которого канал связи передает сигналы, или иначе - доля пропускной способности канала связи, занимаемой кадрами, коллизиями и помехами.
Параметр "Утилизация канала связи" характеризует величину загруженности сети. Канал связи сети является общим сетевым ресурсом, поэтому его загруженность влияет на время реакции прикладного программного обеспечения. Первоочередная задача состоит в определении наличия взаимозависимости между плохой работой прикладного программного обеспечения и утилизацией канала связи сети. Предположим, что анализатор протоколов установлен в том домене сети (collision domain), где прикладное ПО работает медленно. Средняя утилизация канала связи составляет 19%, пиковая доходит до 82%. Но сделать на основании этих данных достоверный вывод о том, что причиной медленной работы программ в сети является перегруженность канала связи нельзя.
Часто можно слышать о стандарте де-факто, в соответствии с которым для удовлетворительной работы сети Ethernet утилизация канала связи "в тренде" (усредненное значение за 15 минут) не должна превышать 20%, а "в пике" (усредненное значение за 1 минуту) - 35-40%. Приведенные значения объясняются тем, что в сети Ethernet при утилизации канала связи, превышающей 40%, существенно возрастает число коллизий и, соответственно, время реакции прикладного ПО. Несмотря на то, что такие рассуждения в общем случае верны, безусловное следование подобным рекомендациям может привести к неправильному выводу о причинах медленной работы программ в сети. Они не учитывают особенности конкретной сети, а именно: тип прикладного ПО, протяженность домена сети, число одновременно работающих станций.
Чтобы определить, какова же максимально допустимая утилизация канала связи в каждом конкретном случае, рекомендуется следовать приведенным ниже правилам.
Правило 1.1. Если в сети Ethernet в любой момент времени обмен данными происходит не более чем между двумя компьютерами, то любая сколь угодно высокая утилизация сети является допустимой.
Сеть Ethernet устроена таким образом, что если два компьютера одновременно конкурируют друг с другом за захват канала связи, то через некоторое время они синхронизируются друг с другом и начинают выходить в канал связи строго по очереди. В таком случае коллизий между ними практически не возникает.
Если рабочая станция и сервер обладают высокой производительностью, и между ними идет обмен большими порциями данных, то утилизация в канале связи может достигать 80-90% (особенно в пакетном режиме - burst mode). Это абсолютно не замедляет работу сети, а, наоборот, свидетельствует об эффективном использовании ее ресурсов прикладным ПО.
Таким образом, если в сети утилизация канала связи высока, надо постараться определить, сколько компьютеров одновременно ведут обмен данными. Это можно сделать, например, собрав и декодировав пакеты в интересующем канале в период его высокой утилизации.
Правило 1.2 Высокая утилизация канала связи сети только в том случае замедляет работу конкретного прикладного ПО, когда именно канал связи является "узким местом" для работы данного конкретного ПО.
Кроме канала связи узкие места в системе могут возникнуть из-за недостаточной производительности или неправильных параметров настройки сервера, низкой производительности рабочих станций, неэффективных алгоритмов работы самого прикладного ПО.
В какой мере канал связи ответственен за недостаточную производительность системы, можно выяснить следующим образом. Выбрав наиболее массовую операцию данного прикладного ПО (например, для банковского ПО такой операцией может быть ввод платежного поручения), следует определить, как утилизация канала связи влияет на время выполнения такой операции. Проще всего это сделать, воспользовавшись функцией генерации трафика, имеющейся в ряде анализаторов протоколов (например, в Observer). С помощью этой функции интенсивность генерируемой нагрузки следует наращивать постепенно, и на ее фоне производить измерения времени выполнения операции. Фоновую нагрузку целесообразно увеличивать от 0 до 50-60% с шагом не более 10%.
Если время выполнения операции в широком интервале фоновых нагрузок не будет существенно изменяться, то узким местом системы является не канал связи. Если же время выполнения операции будет существенно меняться в зависимости от величины фоновой нагрузки (например, при 10% и 20% утилизации канала связи время выполнения операции будет значительно различаться), то именно канал связи, скорее всего, ответственен за низкую производительность системы, и величина его загруженности критична для времени реакции прикладного ПО. Зная желаемое время реакции ПО, легко можно определить, какой утилизации канала связи соответствует желаемое время реакции прикладного ПО.
В данном эксперименте фоновую нагрузку не следует задавать более 60-70%. Даже если канал связи не является узким местом, при таких нагрузках время выполнения операций может возрасти вследствие уменьшения эффективной пропускной способности сети.
Правило 1.3 Максимально допустимая утилизация канала связи зависит от протяженности сети.
При увеличении протяженности домена сети допустимая утилизация уменьшается. Чем больше протяженность домена сети, тем позже будут обнаруживаться коллизии. Если протяженность домена сети мала, то коллизии будут выявлены станциями еще в начале кадра, в момент передачи преамбулы. Если протяженность сети велика, то коллизии будут обнаружены позже - в момент передачи самого кадра. В результате накладные расходы на передачу пакета (IP или IPX) возрастают. Чем позже выявлена коллизия, тем больше величина накладных расходов и большее время тратится на передачу пакета. В результате время реакции прикладного ПО, хотя и незначительно, но увеличивается.
Выводы. Если в результате проведения диагностики сети вы определили, что причина медленной работы прикладного ПО - в перегруженности канала связи, то архитектуру сети необходимо изменить. Число станций в перегруженных доменах сети следует уменьшить, а станции, создающие наибольшую нагрузку на сеть, подключить к выделенным портам коммутатора.
Второй этап: Измерение числа коллизий в сети.
Если две станции домена сети одновременно ведут передачу данных, то в домене возникает коллизия. Коллизии бывают трех типов: местные, удаленные, поздние. Местная коллизия (local collision) - это коллизия, фиксируемая в домене, где подключено измерительное устройство, в пределах передачи преамбулы или первых 64 байт кадра, когда источник передачи находится в домене. Алгоритмы обнаружения местной коллизии для сети на основе витой пары (10BaseT) и коаксиального кабеля (10Base2) отличны друг от друга.
В сети 10Base2 передающая кадр станция определяет, что произошла локальная коллизия по изменению уровня напряжения в канале связи (по его удвоению). Обнаружив коллизию, передающая станция посылает в канал связи серию сигналов о заторе (jam), чтобы все остальные станции домена узнали, что произошла коллизия. Результатом этой серии сигналов оказывается появление в сети коротких, неправильно оформленных кадров длиной менее 64 байт с неверной контрольной последовательностью CRC. Такие кадры называются фрагментами (collision fragment или runt). В сети 10BaseT станция определяет, что произошла локальная коллизия, если во время передачи кадра она обнаруживает активность на приемной паре (Rx).
Удаленная коллизия (remote collision) - это коллизия, которая возникает в другом физическом сегменте сети (т. е. за повторителем). Станция узнает, что произошла удаленная коллизия, если она получает неправильно оформленный короткий кадр с неверной контрольной последовательностью CRC, и при этом уровень напряжения в канале связи остается в установленных пределах (для сетей 10Base2). Для сетей 10BaseT/100BaseT показателем является отсутствие одновременной активности на приемной и передающей парах (Tx и Rx).
Поздняя коллизия (late collision) - это местная коллизия, которая фиксируется уже после того, как станция передала в канал связи первые 64 байт кадра. В сетях 10BaseT поздние коллизии часто фиксируются измерительными устройствами как ошибки CRC. Если выявление локальных и удаленных коллизий, как правило, еще не свидетельствует о наличии в сети дефектов, то обнаружение поздних коллизий - это явное подтверждение наличия дефекта в домене. Чаще всего это связано с чрезмерной длиной линий связи или некачественным сетевым оборудованием.
Помимо высокого уровня утилизации канала связи коллизии в сети Ethernet могут быть вызваны дефектами кабельной системы и активного оборудования, а также наличием шумов. Даже если канал связи не является узким местом системы, коллизии несущественно, но замедляют работу прикладного ПО. Причем основное замедление вызывается не столько самим фактом необходимости повторной передачи кадра, сколько тем, что каждый компьютер сети после возникновения коллизии должен выполнять алгоритм отката (backoff algorithm): до следующей попытки выхода в канал связи ему придется ждать случайный промежуток времени, пропорциональный числу предыдущих неудачных попыток. В этой связи важно выяснить, какова причина коллизий - высокая утилизация сети или "скрытые" дефекты сети. Чтобы это определить, мы рекомендуем придерживаться следующих правил:.
Правило 2.1 Не все измерительные приборы правильно определяют общее число коллизий в сети. Практически все чисто программные анализаторы протоколов фиксируют наличие коллизии только в том случае, если они обнаруживают в сети фрагмент, т. е. результат коллизии. При этом наиболее распространенный тип коллизий - происходящие в момент передачи преамбулы кадра (т. е. до начального ограничителя кадра (SFD)) - программные измерительные средства не обнаруживают, так уж устроен набор микросхем сетевых плат Ethernet. Наиболее точно коллизии обнаруживают аппаратные измерительные приборы, например LANMeter компании Fluke.
Подобные документы
Основные характеристики мультимедийного проектора, его назначение, функции и виды. Технологии, применяемые в проекторах. Основы диагностики неисправностей и контроля технического состояния. Порядок поиска неисправностей на примере проектора Benq.
дипломная работа , добавлен 17.07.2016
Организация, построение локальных сетей и подключения к сети интернет для разных операционных систем (Windows XP и Windows 7). Проблемные аспекты, возникающие в процессе настройки локальной сети. Необходимые устройства. Безопасность домашней группы.
курсовая работа , добавлен 15.12.2010
Локальные вычислительные сети. Понятие локальной сети, ее назначение и виды. Одноранговые и двухранговые сети Устройство межсетевого интерфейса. Сетевая технология IEEE802.3/Ethernet. Локальные сети, управляемые ОС Windows Svr Std 2003 R2 Win32.
курсовая работа , добавлен 24.09.2008
Передача информации между компьютерами. Протокол передaчи. Виды сетей. Назначение локальной сети. Прямое соединение. Топология локальной сети. Локальные сети в организациях. Сетевая операциооная система.
реферат , добавлен 17.09.2007
Требования к серверу. Выбор сетевых программных средств. Оптимизация и поиск неисправностей в работающей сети. Структура Fast Ethernet. Ортогональное частотное разделение каналов с мультиплексированием. Классификация беспроводного сетевого оборудования.
дипломная работа , добавлен 30.08.2010
Основные понятия IP телефонии, строение сетей IP телефонии. Структура сети АГУ. Решения Cisco Systems для IP-телефонии. Маршрутизаторы Cisco Systems. Коммутатор серии Catalyst 2950. IP телефон. Настройка VPN сети. Способы и средства защиты информации.
дипломная работа , добавлен 10.09.2008
Теоретическое обоснование построения вычислительной локальной сети. Анализ различных топологий сетей. Проработка предпосылок и условий для создания вычислительной сети. Выбор кабеля и технологий. Анализ спецификаций физической среды Fast Ethernet.
курсовая работа , добавлен 22.12.2014
Понятие и определения теории надежности и технической диагностики автоматизированных систем. Организация автоматизированного контроля в производственных системах. Характеристика и суть основных методов и средств современной технической диагностики.
контрольная работа , добавлен 23.08.2013
Проектирование POST Card PCI, предназначенного для диагностики неисправностей при ремонте и модернизации компьютеров типа IBM PC. Описание блок–схемы устройства. Параметры печатной платы. Технология изготовления и трассировка печатной платы с помощью ЭВМ.
дипломная работа , добавлен 11.04.2012
Основные топологии связей в локальной сети: общая шина и кольцо. Классические функции канального уровня информационной сети. Физический уровень стандарта, скорость передачи данных. Коллизии и алгоритмы выхода из коллизий. Понятие промышленных сетей.
Возможно, вы сталкивались с этим неоднократно: один компьютер неизвестно почему не может связаться с другими. Система управления находится в одном сегменте сети с маршрутизаций, подключенного к другим сегментам сети с помощью маршрутизатора, например сервера Microsoft Internet
Security and Acceleration (ISA) Server или другого устройства. При управлении десятью, двадцатью и даже сотней системам никаких неполадок не возникает. Но при попытке управлять 500 системами ваш компьютер не может связаться по сети с другими компьютерами за исключением тех, к которым уже открыты подключения. Невозможно обмениваться данными с другими системами, невозможно выйти в Интернет, но ни у кого во всей сети, в том числе и в вашем сегменте, нет таких неполадок. Где прежде всего стоит искать причину?
Диагностика неполадки
В такой ситуации прежде всего следует предположить сбой программы, управляющей системами. Многие средства управления могут подключаться к другим компьютерам и управлять ими, но иногда такие средства сами могут вызвать неполадки, которые вы пытаетесь устранить. Причина заключается в том, что средства управления могут создавать тысячи подключений к устройствам в целях управления. В Windows® эти подключения по умолчанию остаются открытыми в течение двух минут даже в случае простоя, если только какая-либо программа, приложение или служба не продлит срок действия этих подключений. Это означает, что даже если система управления не обращалась к другим компьютерам в течение двух минут, может быть по-прежнему более 1000 открытых подключений. (Чтобы увидеть открытые подключения, можно выполнить в командной строке команду NETSTAT. С помощью этой команды можно увидеть все открытые, ожидающие и закрывающиеся подключения к системе и их состояние. Описания сообщений о состоянии приведены в документе RFC 793 по адресу tools.ietf.org/html/rfc793 .)
Чтобы определить, что именно система управления вызывает сбой, можно создать пакетный файл, устанавливающий подключение к удаленным системам. Если такая же неполадка возникнет при запуске пакетного файла, то система управления не имеет отношения к неполадке. Вот пример содержимого такого пакетного файла:
Net use \\system01\ipc$ Net use \\system02\ipc$ Net use ...
Если программа управления использует свой собственный сетевой стек и стек проверки подлинности, причина неполадки может заключаться в этой программе, однако в решениях без агентов, таких как большинство систем управления, для выполнения действий в сети используются системные стеки сети и проверки подлинности. Применение пакетного файла, запускающего столько же сетевых подключений без сбоев, будет означать, что проблема вызвана не тем, как программа использует стеки операционной системы (сетевой и проверки подлинности), поскольку пакетный файл использует их правильно.
Если журналы
и сообщения об ошибках не помогают
Возможно, вы обратили внимание, что когда начались неполадки в сети, на компьютере появились сообщения об ошибках: ошибка 53 - сетевой путь не найден, ошибка 64 - имя в сети удалено, ошибка 1203 - поставщик сети не принял указанный сетевой путь. Все эти сообщения могут правильно указывать на наличие соответствующих ошибок, но ведь на других компьютерах нет никаких проблем с разрешением имен и подключением к тем же самым системам. Чтобы проверить правильность параметров компьютера и убедиться, что неполадка вызвана не ими, просто выполните команду ipconfig.
Теперь, поскольку проблема существует только в вашей системе управления, стоит заглянуть в журналы событий. Поиск журналов приложений бесполезен, но в системном журнале окажется событие предупреждения с кодом 4226 из источника TCP/IP, означающее, что достигнуто предельное число подключений (см. рис. 1 ).
Рис. 1 TCP connection limit has been reached
Тщательный поиск данных об ограничениях подключений в базе знаний Майкрософт приведет к следующему результату: оказывается, есть ограничения, накладываемые на невыполненные подключения, но выполненные подключения ограничений не имеют. Для управления этими свойствами можно изменить значения реестра в разделе HKLM\System\CurrentControlSet\Services\TCPIP. Параметр TcpNumConnections используется для установки максимального числа одновременно открытых TCP-подключений (по умолчанию это число равно 10). Параметр TCPTimedWaitDelay устанавливает время, в течение которого подключение остается в состоянии TIME_WAIT при закрытии. Это время по умолчанию равно 120 секундам, то есть подключение обычно используется в течение 4 минут. Наибольше число подключений также зависит от параметра MaxFreeTcbs. Если все контрольные блоки TCP использованы, протокол TCP должен высвободить подключения, находящиеся в состоянии TIME_WAIT, чтобы создать больше подключений, даже если время, указанное параметром TCPTimedWaitDelay, еще не истекло. Диапазон допустимых значений параметра TCPTimedWaitDelay составляет от 30 до 300 секунд (0x1E – 0x12C).
В зависимости от среды изменение этих параметров реестра может привести к некоторому повышению производительности работы системы. Для устранения ограничений можно также изменить файл TCPIP.sys, но это повлияет только на работу P2P-приложений.
Запись
сетевых данных
Если больше ничего не помогает, можно попробовать записать сетевые данные с компьютеров. При запуске сетевого монитора (Netmon) записанные данные в точности соответствовали результатам, которые были очевидны при запуске средств управления и тестовых сценариев: сначала все работает, а потом перестает работать без каких-либо указаний на ошибки.
На рис. 2 показан результат запуска Netmon - успешная связь между первыми и системами. Обратите внимание, что я получаю подтверждения запросов удаленного вызова процедур. Это именно то, что нужно увидеть – успешный двусторонний обмен данными.
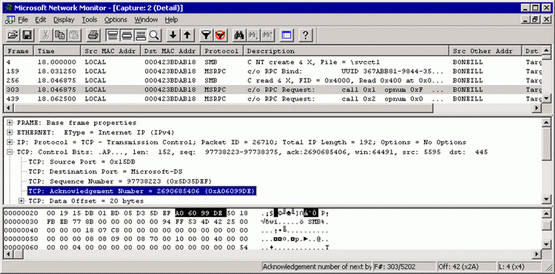
Рис. 2 Successful communication in Netmon
Теперь посмотрим на данные системы управления и удаленных компьютеров, на которых возникает ошибка 53/1203. Как и предполагалось, смотреть не на что: компьютеры не обмениваются данными. В записи сетевых данных на рис. 3 система управления преобразовала IP-адрес и пытается подключиться к системе по порту 445 (порт SMB Майкрософт), но не получает ответа.
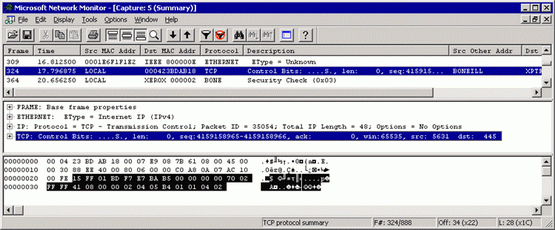
Рис. 3 Attempts to connect to the system over port 445 yield no response
Если количество потоков превышает число подключений, которые может установить ваш компьютер в настоящее время, могут возникать различные ошибки. В некоторых случаях в исходной системе возникает ошибка 53, которая означает, что получено преобразование имени, но IP-адрес не был найден. Это означает, что DNS-сервер предоставил адрес, к которому невозможно подключиться. В некоторых случаях возникает ошибка 1203, которая означает, что на запрошенное имя или IP-адрес не ответил ни один компьютер. В этом случае ошибка 1203 означает, что служба DNS недоступна. Чтобы убедиться в этом, можно запустить команду nslookup.
На этом этапе вы, наверное, уже потеряете надежду, но еще есть возможности все исправить. Обычно мало кто обращает внимание на инфраструктуру подключений из-за того, как именно возникает неполадка: ваш компьютер - единственный из всех, которому не удается подключиться к остальной сети, и даже журналы событий свидетельствуют, что на компьютере достигнуто предельное число подключений, поэтому вряд ли причиной неполадки является архитектура сети.
Несмотря на то, что тысячи подключений, создаваемых системой управления, создаются не одновременно, из-за времени ожидания передачи данных и подключений может возникнуть очень большое число одновременно открытых подключений. Поэтому нужно обратить внимание на системы, посредством которых ваш компьютер подключен к остальной сети.
А дело вот в чем. Как я уже говорил выше, весь трафик в вашей сети проходит через коммутаторы, маршрутизаторы и, вероятно, через межсетевые экраны. В любом из этих элементов, обычно в маршрутизаторах или межсетевых экранах, могут применяться системы обнаружения вторжения. В управляемых коммутаторах и маршрутизаторах также может быть включена фильтрация трафика. Тем, кто управляет этими устройствами, нужно проверить их журналы - возможно, в них будут ошибки или предупреждения. Неполадки связи вполне могут быть вызваны именно этими системами.
Вы подключаетесь из внутренней системы к другим внутренним системам, поэтому оповещения не создаются: создание оповещений может быть не настроено на устройствах, или потому что неполадка не рассматривается как вторжение или атака типа «отказ в обслуживании». Итак, снова начнем с журналов. В качестве примера будем использовать ISA Server. В этом случае журналы будут находиться в консоли управления ISA Server в разделе Массивы\<Имя_массива>\Наблюдение\Ведение журнала.
Если вам мешает политика, можно (при использовании ISA Server) поискать следующие коды результатов (исходный IP-адрес - ваш компьютер управления):
- 0xc0040037 FWX_E_TCP_RATE_QUOTA_EXCEEDED_DROPPED
- 0xc004000d FWX_E_POLICY_RULES_DENIED
- 0xc0040017 FWX_E_TXP_SYN_PACKET_DROPPED
Если вы их обнаружили, то причина неполадок в сети найдена.
Применение решения
Итак, теперь проблема установлена, решение может быть простым, но политика отдела может затруднить применение этого решения. Перед внесением каких-либо изменений убедитесь, что у вас есть на это разрешение, поскольку создание исключений в конфигурации безопасности межсетевых экранов, маршрутизаторов и систем обнаружения вторжений может быть запрещено.
На примере ISA Server посмотрим, как увеличить наибольшее число подключений для данного узла или для всех компьютеров сети (см. рис. 4 ). Откройте консоль управления ISA Server и перейдите в раздел Массивы\<Имя_массива>\Конфигурация\Общие\Настройте параметры предотвращения Flood-атаки.
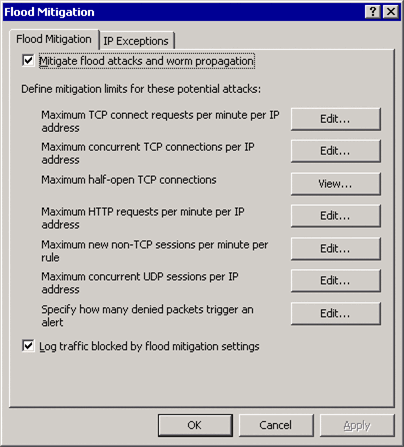
Рис. 4 Increase the maximum number of connections for one host or all machines using ISA Server
Два нужных нам параметра - наибольшее число одновременных TCP-подключений на IP-адрес и наибольшее число запросов TCP-подключений на IP-адрес в минуту. Предельное число одновременных TCP-подключений на IP-адрес обычно устанавливается таким, чтобы его было достаточно при отсутствии активного управления, то есть одному компьютеру не нужно быстро подключаться к тысячам других компьютеров. В ISA Server наибольшее число одновременных TCP-подключений равно 160. Число запросов TCP-подключений на IP-адрес в минуту устанавливается таким образом, чтобы ограничить нагрузку, вызванную сканированием сети, и его видимость. Это число равно 600 запросам в минуту на каждый IP-адрес.
Как мы уже обсудили выше, в Windows подключение по умолчанию остается активным в течение двух минут, если не предпринимаются никакие действия, чтобы продлить срок действия подключения, даже если оно не используется. Это означает, что подключение к какому-либо компьютеру останется активным даже после того, как все действия по управлению этим компьютером уже выполнены и обмениваться с ним данными больше не нужно. Это открытое подключение остается одним из множества открытых подключений. Если повторить этот процесс более 160 раз, не удаляя подключения, то окажется, что все дальнейшие попытки подключений будут отклонены маршрутизатором. Даже если программа управления активно завершает сеанс, операционная система Windows может оставить подключение в состоянии time_wait, дожидаясь от второго компьютера ответа с согласием на отключение.
Таким образом, прежде всего нужно изменить тот параметр, который вероятнее всего вызывает неполадку: наибольшее число одновременных TCP-подключений на IP-адрес. Значение этого параметра нужно установить таким, чтобы система управления смогла устанавливать все необходимые подключения, не сталкиваясь с запретом доступа. Нажмите кнопку «Изменить» рядом с этим параметром и измените значения.
В следующем окне (см. рис. 5 ) появится поле «Предел», в котором указано предельное значение по умолчанию, применяемое ко всем клиентским системам. «Настраиваемый предел» применяется ко всем компьютерам, сетям и другим объектам, определенным на вкладке «Исключения IP-адресов» окна предотвращения Flood-атак. Чтобы разрешить всем компьютерам создавать больше подключений, измените значение параметра «Предел». Чтобы настроить исключение только для данного компьютера, измените предельное значение и добавьте данный компьютер на вкладку «Исключения IP-адресов». Рекомендуется разрешить исключения только для вашего компьютера.
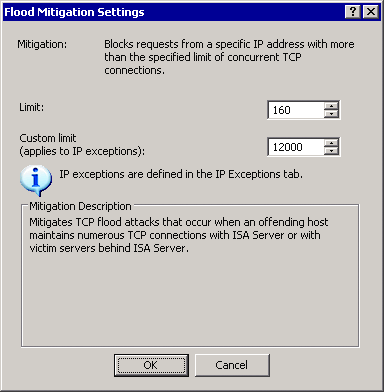
Рис. 5 Default connection limit and custom connection limit
Если нужно изменить это значение только для определенных компьютеров, измените значение в поле «Настраиваемый предел» и нажмите кнопку «ОК». Затем добавьте ваш компьютер на вкладку «Исключения IP-адресов» окна предотвращения Flood-атак. Чтобы добавить только ваш компьютер в список исключений, нажмите на вкладке «Исключения IP-адресов» кнопку «Добавить», чтобы открыть окно «Наборы компьютеров». Щелкните «Создать», чтобы создать новый набор, содержащий ваш компьютер (если такого еще не существует). Выберите этот набор и нажмите кнопку «Добавить», чтобы добавить набор «Внутренние сети», затем нажмите кнопку «Закрыть». Снова выберите набор «Внутренние сети» и нажмите кнопку «Изменить». При этом откроется окно свойств набора «Внутренние сети» (см. рис. 6 ). Нажмите в этом окне кнопку «Добавить», чтобы открыть вложенное меню, в котором можно добавить компьютер, диапазон адресов или подсеть. Выберите компьютер. Введите имя, чтобы определить эту запись, IP-адрес и понятное описание, чтобы кто-нибудь другой при просмотре этой записи не удалил вашу систему (см. рис. 7 ). Нажмите кнопку «ОК», чтобы добавить ваш компьютер, затем нажмите ее снова, чтобы добавить исключение. Теперь нужно применить внесенные изменения.

Рис. 6
Internal networks properties settings

Рис. 7
Enter computer name, IP address, and description to
ensure your system is not removed
Попробуйте снова запустить систему управления. Вы увидите, что производительность стала гораздо выше, а подключения работают без неполадок (во всяком случае, без неполадок, вызванных сетевым трафиком). Таким образом, в итоге выяснилось, что неполадка была вызвана не числом подключений, вызванных программой, а неправильным их планированием.
Извлеченные уроки
Одна из самых больших неприятностей в сфере ИТ - возникновение и устранение проблем, причину которых трудно обнаружить. Эти неполадки не вызваны действиями пользователей или серверной группы, служба поддержки окажется не в курсе, но вы можете отвечать за их устранение. Существуют средства, которые помогут выявить неполадки, обнаружить их и устранить, но иногда их недостаточно. Иногда они работают неправильно. Иногда вам нужно быть умнее таких средств.
Если вдруг возникнет ситуация, когда у вашего компьютера начнутся неполадки с сетевыми подключениями без каких-либо очевидных причин, попробуйте сделать то, о чем я рассказал выше. Вполне вероятно, что, выполнив описанные действия, внимательно изучив работу системы управления и правильно настроив разрешенные подключения, вы успешно решите проблему.
 Отказы собственно физической сети случаются редко, почти никогда. Но некоторые неисправности выглядят для пользователей как настоящий отказ сети.
Отказы собственно физической сети случаются редко, почти никогда. Но некоторые неисправности выглядят для пользователей как настоящий отказ сети.
Обычно звучит приведенная выше фраза, и ИТ-администратору приходится ломать голову, отыскивая неисправность в ситуациях, вызванных неполадками четырех видов. Как будет показано в статье, внешние проявления неисправностей сети часто обманчивы. Два случая можно ошибочно принять за неполадку сети, хотя в действительности причина неисправности иная. Рассмотрим некоторые досадные проблемы с сетью и способы их устранения.
Загадочные разъединения
ИТ-специалиста просят прийти в комнату пользователя, потерявшего соединение с сетью. Windows показывает, что соединение активно, но кабель отключен. Вздыхая, администратор проверяет Ethernet-кабель пользователя. Он подключен. После замены кабеля связь не восстанавливается. Начиная раздражаться, администратор переносит кабель между коммутационной панелью и коммутатором Ethernet в распределительном шкафу на другой порт коммутатора. Соединение восстановлено. Что произошло?
Многие корпоративные коммутаторы располагают встроенной функциональностью для автоматического отключения порта с подозрительным поведением. Типичная причина - дуплексное рассогласование. Предполагается, что отключенный порт будет немедленно замечен, и это поможет администратору устранить неполадку, которая привела к автоматическому отключению порта.
В документации Cisco эта функция именуется error-disable или errdisable. Другие поставщики могут применять иную терминологию.
Ниже перечислена последовательность шагов, как можно обнаружить и устранить эту проблему. В данной статье используются примеры на основе Cisco CatOS, хотя аналогичная функциональность существует для Cisco IOS.
Итак, необходимые действия:
Физически идентифицируйте порт коммутатора, отключенный в результате ошибки.
Из активного режима выполните команду show port
Если порт действительно отключен в результате ошибки, состояние будет показано как errdisable.
Устраните неполадку, которая привела к отключению порта. Не забудьте проверить настройки дуплекса и кабели.
Чтобы заново активизировать порт, выполните из активного режима команду set port enable
Существует также функция, позволяющая настроить отключенный в результате ошибки порт коммутатора на автоматическое повторное включение по истечении указанного времени. Можно принудительно задействовать все причины ошибочных отключений или указать определенные причины (например, автоматически выполнять повторное включение после всех ошибок, кроме дуплексного рассогласования). Способы настройки порта коммутатора на автоматическое повторное включение описаны в документации для команды set errdisabletimeout.
Маршрутизация между виртуальными локальными сетями
Многие ИТ-специалисты используют протокол VoIP или внесли соответствующий пункт в свой постоянно растущий список неотложных дел. Поставщики VoIP обычно рекомендуют явно создать отдельную виртуальную локальную сеть, чтобы отделить трафик данных от речевого трафика. Такое разделение в первую очередь сокращает объем широковещательного трафика, поступающий в VoIP-телефоны. Кроме того, упрощается применение более строгих параметров службы обеспечения качества обслуживания (QoS) и достигается качество голосовой связи такое же, как у обычного телефона без VoIP, или лучше.
Ко мне часто обращаются специалисты, находящиеся в процессе организации отдельной виртуальной локальной сети или только что завершившие ее настройку. Для некоторых из них это первый опыт настройки виртуальной локальной сети.
Они пытаются с помощью команды ping проверить связь с устройством, имеющим IP-адрес и размещенным в виртуальной локальной сети данных. В большинстве случаев связь между виртуальными локальными сетями необходима для доступа в Internet и управления инфраструктурой VoIP из виртуальной локальной сети данных. Проверка заканчивается неудачей. Отказывают все соединения. Логично предположить, что причина неисправности - в неверной настройке виртуальной локальной сети.
Это не так. Проблема заключается просто в утере навыков диагностики сетевых неполадок. Коммутация выполняется на уровне 2 модели OSI, а протокол IP принадлежит уровню 3. Невозможно маршрутизировать IP-пакеты без устройства, способного выполнить функцию маршрутизации. Но не волнуйтесь, во многих случаях необязательно покупать маршрутизатор. Существует ряд вариантов.
Модернизация. Компания может располагать одним или несколькими коммутаторами, которые обеспечивают IP-маршрутизацию уровня 3 или могут справиться с задачей после модернизации. Такие коммутаторы выпускает большинство ведущих поставщиков. Приобретая для VoIP новые коммутаторы, обеспечивающие подачу электропитания через Ethernet (PoE), полезно купить коммутатор с функциональностью уровня 3.
Маршрутизатор для малого или домашнего офиса. Маршрутизатор для малого или домашнего офиса - не лучший выбор для масштабирования и технического обслуживания, но, по крайней мере, он может служить отправной точкой.
Брандмауэр. Аппаратный или программный брандмауэр полезен при наличии свободного интерфейса Ethernet. Отметьте интерфейс как соединение с дополнительной внутренней или доверенной сетью, и установите соответствующие политики маршрутизации и безопасности.
Служба маршрутизации и удаленного доступа (RRAS). Можно использовать службу RRAS, доступную в Windows Server, при условии, что она установлена на компьютере с двумя интерфейсами Ethernet. Это удачный вариант, если требуется обеспечить для голосовой виртуальной локальной сети такие службы инфраструктуры, как DHCP и DNS.
Прерванная операция
Распространенная проблема: пользователь вводит URL-указатель в строку адреса Internet Explorer (IE) и нажимает клавишу Enter. Начинается загрузка сайта, но затем появляется диалоговое окно с сообщением Internet Explorer cannot open the Internet site . Operation aborted. Однако повторная попытка загрузить страницу оказывается успешной. Мне неоднократно приходилось сталкиваться с такой особенностью на сайте Microsoft TechNet, но я никогда не обращал на нее внимания. Только когда сотрудники моего офиса стали жаловаться, что это происходит на других сайтах, в том числе на домашней странице Google, я решил узнать, в чем дело.
Поначалу я думал, что причина - в функциональности Web-proxy брандмауэра ISA Server. Но неполадка не исчезла даже после того, как трафик был временно направлен в обход брандмауэра. Затем я предположил, что сеанс TCP был сброшен до завершения загрузки страницы. В результате трассировки сети выяснилось, что это не так.
Наконец, я пришел к мысли, что проблема может быть в самом браузере IE, поэтому провел поиск в Internet и обнаружил статью Microsoft «BUG: Error message when you visit a Web page or interact with a Web application in Internet Explorer: "Operation aborted"» по адресу support.microsoft.com/kb/927917.
В ней описана та самая проблема, но ее причина (код сценария, который изменяет определенные элементы контейнера) не объясняет, почему неполадка не проявлялась постоянно. Ведь маловероятно, что сайт TechNet был изменен в течение двух секунд, которые требуются, чтобы нажать клавишу F5. Однако дальнейшее исследование показало, что проблема заключается в компоненте синтаксического анализатора IE: точный порядок загрузки и синтаксического анализа страницы чуть меняется от одного обновления к другому. Таким образом, стало понятно, почему я мог обновить страницу, на которой происходили неполадки, десять раз, а проблема проявлялась дважды.
Но мне так и не удалось найти способа обойти эту ситуацию. В статье говорится, что бесперебойное функционирование должен обеспечить автор сайта, изменив программный код. Надеемся, компания Microsoft устранит неполадку в версии IE 8.0.
Просроченные пароли
Ко мне обратился взволнованный бывший коллега: его сеть рушилась. Среди описанных им симптомов была невозможность пользователей обратиться к Exchange Server через Microsoft Office Outlook. Некоторые присоединенные диски тоже были недоступны. Как ни странно, доступ в Internet был возможен.
Пока коллега искал причину неполадки, те же самые проблемы начались у пользователя в соседней комнате. Через пять минут сотрудник с дальнего конца офиса громко всех оповестил, что и он стал жертвой неисправности.
Я спросил коллегу, проверил ли он очевидную причину - возможные неполадки на сервере. Их не было. В последнее время изменения в программное обеспечение или оборудование не вносились. Основные сетевые соединения функционируют исправно.
Поразмыслив, я спросил, проверены ли учетные записи пользователя в Active Directory (AD)? Возможно, пользователи, пострадавшие от неполадок, каким-то образом блокировали себя. Он проверил это предположение, и выяснилось, что пользователи не блокированы. Наконец, меня осенило - а не получали ли в последнее время пользователи извещения о скором истечении срока действия пароля?
Коллега ответил, что все пользователи видели извещение в течение нескольких дней, и сегодня в сообщении говорилось, что срок истекает через один день. Никто не любит менять пароль, поэтому пользователи регулярно нажимали No. В день аварии история повторилась. Однако «один день» в сообщении означает не «в течение 24 часов от настоящего момента», а «когда-нибудь в течение следующих 24 часов». Мой коллега дал пользователям указание завершить сеанс, а потом заново выполнить регистрацию. Естественно, всем им пришлось изменить пароли, и после этого проблем не возникало. Поскольку сотрудники приходили на работу ежедневно примерно в одно и то же время, срок действия их паролей завершался почти одновременно. Теперь мы объясняем пользователям, что «один день» в действительности означает «сегодня».
Майкл Дрегон ([email protected]) - редактор Windows IT Pro и системный инженер в Нью-Йорке. Имеет сертификаты MCDST и MCSE: Messaging
Поиск неисправностей в сети
Один из ключевых элементов диагностики сети - наличие четкого плана действий. Чаще всего жалобы пользователей будут следствием их же ошибок, связанных, например, с некорректным использованием программы. Но, столкнувшись в серьезной проблемой, Вы должны следовать установленной процедуре поиска и устранения неполадок. Она может включать в себя следующие шаги.
1. Выяснение симптомов.
2. Локализация неполадки.
3. Выявление недавних изменений.
4. Выделение наиболее вероятной причины.
5. Устранение неполадки.
6. Тестирование.
7. Проверка иных последствий принятого решения.
8. Документирование проблемы и ее решения.
В Вашей организации действия могут быть немного другими или выполняться в другом порядке, но в целом процесс будет именно такой.
Выяснение симптомов
Приступая к устранению неполадок в сети, прежде всего нужно выяснить, что именно не работает и как это влияет на функциональность сети в целом. Последнее поможет присвоить неисправности должный приоритет. В больших сетях число обращений в сервисную службу существенно превышает ее возможности. Поэтому важно установить систему приоритетов, т. е. обозначить, какие проблемы будут решаться в первую очередь. Разумеется, наивысший приоритет получает не тот, кто первым пришел, а тот, у кого проблема сложнее. Правда, в реальной жизни не обойтись без политических соображений, согласно которым первостепенное внимание уделяется проблемам начальника.
Следующие правила помогут Вам разработать собственную систему приоритетов.
Общие ресурсы имеют преимущество перед индивидуальными. Неполадки в сервере или другом сетевом компоненте, мешающие работе многих пользователей, должны решаться прежде, чем неполадки, затрагивающие одного пользователя.
Сначала решается глобальная сетевая проблема, потом локальная. Ресурсы, обслуживающие всю сеть, например, почтовый сервер, должны обслуживаться раньше локальных ресурсов, например, файлового сервера или сервера печати.
Порядок обслуживания запросов устанавливается в соответствии с тем, из какого отдела они поступили. Прежде всего следует обращать внимание на жалобы из отделов, жизненно важных для работы компании, например, отдела продаж или отдела по обслуживанию клиентов. Во вторую очередь помощь получают отделы, которые от перерыва в работе пострадают в меньшей степени, скажем, научно-исследовательский.
Системные нарушения белее важны, чем проблемы, связанные с конкретными приложениями. При возникновении на одном из компьютеров неполадок, препятствующих работе на нем, заниматься в первую очередь нужно ими:, а не некорректной работой приложения на другом компьютере.
Иногда бывает трудно понять истинную природу неисправности по объяснениям неподготовленного пользователя, но для сужения области поиска необходимо получить от него максимально полную информацию о том, что все-таки произошло. Пользователи часто не могут внятно объяснить, чем они занимались в момент возникновения проблемы и каковы были ее проявления. Часто, например, человек обращается за помощью, увидев на экране сообщение об ошибке, но, как правило, и не думает записать или запомнить его. Ненавязчивое обучение пользователей правильным действиям при обнаружении неисправности тоже входит в обязанности сетевого техника. Это поможет Вам в будущем, когда пользователь начнет относиться к ошибкам более осмысленно.
Пока же можно задать пользователю следующие вопросы.
Что именно он делал, когда возникла проблема?
Есть ли в работе компьютера другие нарушения?
Работал ли компьютер нормально непосредственно перед ошибкой?
Производилась ли недавно установка, удаление или перенастройка программного или аппаратного обеспечения?
Пытался ли уже кто-то решить эту проблему?
Локализация неполадки
Следующий шаг в понимании сути проблемы - попытка ее воспроизвести. Воспроизводимые сетевые неполадки обычно легче исправить, так как в этом случае можно проверить, привело ли предпринятое действие к их устранению. Однако многие сбои в сетях повторяются лишь время от времени. В этом случае придется ждать, когда неисправность снова даст о себе знать. Иногда для решения проблемы достаточно попросить воспроизвести ее самого пользователя, Ошибки пользователей при работе с оборудованием и программами - одна из основных причин неисправностей в сети.
Найдя способ воспроизвести проблему, приступайте к поискам ее причин. Допустим, у пользователя возникает ошибка при открытии файла в текстовом редакторе. Причина может быть в приложении на этом компьютере, или на файловом сервере, где хранится файл, или в сетевом соединении между ними. Локализация причины состоит в логическом исключении элементов, которые не могут быть ответственны за неисправность.
Если воспроизвести проблему удалось, можно начинать поиск ее причин с изменения условий, при которых проблема возникает, например, в такой последовательности.
1. Попросите пользователя повторить действия, приводящие к проблеме, чтобы определить, какое из них непосредственно предшествует ошибке.
2. Попробуйте сами выполнить те же действия на том же компьютере. Если ошибки не возникает, она, вероятно, является следствием неверных действий пользователя. Проверьте, правильно ли он работает. Не исключено, что к одному и тому же результату он и Вы попытались пройти разными путями, оба из которых приемлемы, но метод пользователя выявляет ошибку, а Ваш - нет.
3. Если Вы также столкнулись с ошибкой, попробуйте выйти из сеанса пользователя и зарегистрируйтесь в качестве администратора. Исчезновение ошибки может означать, что у пользователя недостаточно полномочий для того, что он затеял.
4. При повторении ошибки попробуйте выполнить те же действия на другом компьютере. Если попытка оказалась удачной, причина неисправности - в компьютере пользователя или в его подключении к сети. Если проблема обнаруживается и на другом компьютере, ее причина - в самой сети: в файловом сервере или в соединении между ним и компьютером.
13 способов, как своими руками устранить неполадки подключений, по протоколу TCP/IP в Windows XP . (Only for "direct" hands - Только если обе руки не левые;))
Способ 1. Проверка конфигурации с помощью средства IPConfig
Чтобы проверить конфигурацию TCP/IP на компьютере, где обнаружена проблема , с помощью средства IPConfig , нажмите кнопку Пуск , выберите пункт Выполнить и введите команду cmd . Для получения сведений о конфигурации компьютера, включая его IP-адрес , маску подсети и шлюз по умолчанию , можно использовать программу ipconfig.
Если указать для IPConfig параметр /all , будет создан подробный отчет о конфигурации всех интерфейсов , включая адаптеры удаленного доступа . Отчет IPConfig можно записать в файл , что позволит вставлять его в другие документы . Для этого введите команду ipconfig > имя_папкиимя_файла В результате отчет будет сохранен в файле с указанным именем и помещен в указанную папку.
Отчет команды IPConfig позволяет выявить ошибки в конфигурации сети компьютера. Например, если компьютер имеет IP-адрес, который уже присвоен другому компьютеру, то маска подсети будет иметь значение 0.0.0.0.
Если компьютер имеет IP-адрес 169.254.y.z и маску подсети 255.255.0.0, то IP-адрес был назначен средством автоматического назначения IP-адресов APIPA операционной системы Windows XP Professional. Это означает, что TCP/IP настроен для автоматической конфигурации , сервер DHCP не был найден и не была указана альтернативная конфигурация . В этой конфигурации для интерфейса не задан шлюз по умолчанию.
Если компьютер имеет IP-адрес 0.0.0.0, значит, он был переопределен средством опроса носителя DHCP. Это может быть вызвано тем, что сетевой адаптер не обнаружил подключения к сети , или тем, что протокол TCP/IP обнаружил IP-адрес, который дублирует присвоенный вручную адрес компьютера.
Если не удалось определить проблемы в конфигурации TCP/IP, перейдите к способу 2
Способ 2. Проверка подключения с помощью средства Ping
Если в конфигурации TCP/IP не было обнаружено ошибок, проверьте возможность подключения компьютера к другим компьютерам в сети TCP/IP. Для этого используется средство Ping.
С помощью средства Ping можно проверить подключение на уровне IP . Команда ping отправляет на другой компьютер сообщение с эхо-запросом по протоколу ICMP . С помощью средства Ping можно узнать, может ли главный компьютер отправлять IP-пакеты на компьютер-получатель. Команду Ping можно также использовать для выявления того, чем вызвана проблема – неполадкой сетевых устройств или несовместимостью конфигураций .
Примечание Если была выполнена команда ipconfig /all и отобразилась конфигурация IP, то адрес замыкания на себя и IP-адрес компьютера не нужно проверять с помощью команды Ping. Эти задачи уже были выполнены командой IPConfig при выводе конфигурации. При устранении неполадок следует убедиться, что существует маршрутизация между локальным компьютером и узлом сети. Для этого используется команда ping IP-адрес
Примечание IP-адрес является IP-адресом узла сети, к которому требуется подключиться.
Чтобы использовать команду ping, выполните следующие действия:
1. Задайте адрес замыкания на себя, чтобы проверить правильность настройки и установки TCP/IP на локальном компьютере. Для этого служит следующая команда: ping 127.0.0.1 Если контроль по обратной связи завершится ошибкой, это означает, что стек IP не отвечает.
Подобное поведение наблюдается в следующих случаях:
Повреждены драйвера TCP.
Не работает сетевой адаптер.
Другая служба мешает работе протокола IP.
2. Обратитесь по IP-адресу локального компьютера, чтобы убедиться в том, что он был правильно добавлен в сеть. Если таблица маршрутизации
не содержит ошибок, эта процедура просто приведет к направлению пакета по адресу замыкания на себя 127.0.0.1.
Для этого служит следующая команда: ping IP-адрес локального узла Если контроль по обратной связи выполнен успешно, но локальный IP-адрес не отвечает, возможно, проблема заключается в таблице маршрутизации драйвера сетевого адаптера.
3. Обратитесь по IP-адресу шлюза по умолчанию, чтобы проверить его работоспособность и возможность связи с локальным узлом локальной сети. Для этого служит следующая команда: ping IP-адрес шлюза по умолчанию Если обращение завершилось неудачно, это может означать, что проблема заключается в сетевом адаптере , маршрутизаторе/шлюзе , кабеле или другом сетевом устройстве .
4. Обратитесь по IP-адресу удаленного узла , чтобы проверить возможность связи через маршрутизатор. Для этого служит следующая команда: ping IP-адрес удаленного узла. Если обращение завершилось неудачно, это может означать, что удаленный узел не отвечает или проблема заключается в сетевых устройствах между компьютерами. Чтобы исключить возможность отсутствия ответа удаленного узла, проверьте связь с другим удаленным узлом с помощью команды Ping.
5. Обратитесь по IP-адресу удаленного узла, чтобы проверить, может ли быть разрешено имя удаленного узла. Для этого служит следующая команда: ping имя удаленного узла Команда Ping использует разрешение имен для разрешения имени компьютера в IP-адрес. Поэтому, если обращение по IP-адресу производится успешно, а обращение по имени – неудачно, проблема заключается в разрешении имени узла, а не в сетевом подключении. Проверьте, настроены ли для компьютера адреса сервера DNS (вручную в свойствах TCP/IP или автоматически). Если адреса сервера DNS выводятся командой ipconfig /all, обратитесь по адресам сервера, чтобы проверить, доступны ли они.
Если на одном из этапов использования средства Ping возникают ошибки, выполните следующие действия:
Убедитесь, что IP-адрес локального компьютера действителен и правильно задан на вкладке Общие диалогового окна Свойства протокола Интернета (TCP/IP) или с помощью средства Ipconfig.
Убедитесь, что настроен шлюз по умолчанию и имеется связь между узлом и шлюзом по умолчанию. Для разрешения проблем должен быть настроен только один шлюз по умолчанию. Хотя шлюзов по умолчанию может быть несколько, все шлюзы кроме первого используются только тогда, когда стек IP определяет, что первый шлюз не работает. При устранении неполадок определяется состояние первого из настроенных шлюзов. Для облегчения задачи все остальные шлюзы можно удалить.
Убедитесь, что отключен протокол безопасности
IPSec
. При некоторых политиках IPSec
пакеты Ping могут блокироваться или требовать защищенного подключения. Дополнительные сведения о протоколе IPSec см. в способе
7. Проверка протокола IPSec Внимание! Если соединение с удаленной системой, к которой происходит обращение, имеет большое время задержки (это относится, например, к спутниковой линии связи), возможно, ответа придется ждать дольше. С помощью параметра -w можно задать более продолжительный период ожидания, чем период по умолчанию, равный 4 секундам.
Способ 3 . Проверка маршрутизации с помощью средства PathPing
PathPing – это средство, выявляющее потери пакета на маршрутах, включающих несколько прыжков. Обратившись с помощью PathPing к удаленному узлу, можно убедиться, что маршрутизаторы, через которые проходит пакет, работают нормально. Для этого служит следующая команда: pathping IP-адрес удаленного узла
Способ 4 . Очистка кэша ARP с помощью средства Arp
Если обращение по адресу замыкания на себя (127.0.0.1) и собственному IP-адресу выполняется успешно, но ко всем остальным IP-адресам обратиться не удается, попытайтесь очистить кэш протокола
ARP (Address Resolution Protocol
, протокол разрешения адресов).
С помощью командной строки выполните одну из следующих команд.
arp -a (тоже самое arp -g)
Чтобы удалить записи, введите команду
arp -d IP-адрес
Для очистки кэша ARP используется следующая команда:
netsh interface ip delete arpcache
Способ 5 . Проверка шлюза по умолчанию
Способ 6 . Проверка связи с помощью средств Tracert или Route
Если шлюз по умолчанию отвечает правильно, обратитесь к удаленному узлу, чтобы убедится в правильной работе межсетевых соединений. Если эти соединения работают некорректно, проследите путь сообщения к получателю с помощью служебной программы Tracert. Для IP-маршрутизаторов , которые являются компьютерами с операционной системой Microsoft Windows 2000 или Microsoft Windows NT 4.0 , просмотрите таблицу IP-маршрутизации с помощью средства маршрутизации или оснастки «Маршрутизация и удаленный доступ» этих компьютеров. На других IP-маршрутизаторах для просмотра таблицы IP-маршрутизации используйте средство, указанное поставщиком используемой операционной системы.
В большинстве случаев при использовании команды Ping отображаются четыре следующих сообщения об ошибках: TTL
Expired in Transit
Это сообщение об ошибке
означает, что количество требуемых проходов через маршрутизатор превышает время жизни (TTL). Время жизни можно увеличить с помощью команды ping-i. Возможно, причина этой ошибки в том, что в маршрут является циклическим.
Чтобы узнать, действительно ли возник циклический маршрут (из-за неправильной конфигурации маршрутизаторов), используйте команду Tracert Destination Host Unreachable
Это сообщение об ошибке означает, что к узлу-получателю нет локального или удаленного маршрута (на узле-отправителе или маршрутизаторе). Проверьте таблицу маршрутизации на локальном узле или маршрутизаторе.
Request Timed Out
Это сообщение об ошибке означает, что сообщения с эхо-запросами не были получены в течение заданного периода ожидания. По умолчанию он равен 4 секундам. Период ожидания можно увеличить с помощью команды ping -w.
Ping request could not find host
Это сообщение об ошибке означает, что не удается разрешить имя узла-получателя. Проверьте имя и доступность серверов DNS
или WINS
.
Способ 7 . Проверка протокола IPSec
IPSec может усилить безопасность в сети , но усложнить изменение конфигурации сети и устранение неполадок. В некоторых случаях политика IPSec требует защищенного подключения для компьютера под управлением Windows XP Professional. Это требование затрудняет установку подключения к удаленному узлу. Если службы IPSec развернуты на локальном узле , можно отключить их в оснастке «Службы».
Если после отключения IPSec проблемы больше не возникают, это означает, что политика IPSec блокировала трафик или требовала его защиты. В этом случае нужно попросить у администратора безопасности изменить политику IPSec.
Способ 8 . Проверка фильтрации пакетов
Ошибки при фильтрации пакетов могут нарушить работу системы разрешения адресов или подключения. Чтобы узнать, является ли фильтрация пакетов источником проблемы, отключите фильтрацию пакетов TCP/IP.
Для этого выполните следующие действия.
1. Нажмите кнопку Пуск и последовательно выберите пункты Панель управления, Сеть и подключения к Интернету и Сетевые подключения.
2. Щелкните правой кнопкой мыши значок подключения по локальной сети, которое требуется изменить, и выберите пункт Свойства.
3. На вкладке Общие в списке Отмеченные компоненты используются этим подключением выберите вариант Протокол Интернета (TCP/IP) и нажмите кнопку Свойства.
4. Нажмите кнопку Дополнительно и перейдите на вкладку Параметры.
5. В диалоговом окне Необязательные параметры выберите элемент Фильтрация TCP/IP и нажмите кнопку Свойства.
6. Снимите флажок Задействовать фильтрацию TCP/IP (все адаптеры) и нажмите кнопку OK. Попробуйте обратиться к адресу по его имени DNS
, имени NetBIOS
компьютера или IP-адресу. Если обращение выполнено успешно, возможно, параметры фильтрации были неправильно установлены или накладывают слишком жесткие ограничения. Например, фильтрация может разрешить компьютеру выступать в роли веб-сервера, но отключить ряд средств, таких как удаленное администрирование. Чтобы расширить диапазон допустимых параметров фильтрации, измените допустимые значения для порта TCP
, порта UDP
и протокола IP
.
Способ 9 . Проверка подключения к определенному серверу
Чтобы определить причину проблемы при подключении к серверу через NetBIOS
, выполните команду nbtstat -n
на этом сервере. Это позволит узнать, под каким именем сервер зарегистрирован в сети.
Команда nbtstat -n выводит несколько имен, под которыми зарегистрирован компьютер
. Среди этих имен должно быть имя, похожее на то, которое указано на вкладке Имя компьютера
окна Система, доступного с панели управления. Если такого имени нет, попытайтесь использовать любое другое уникальное имя, выведенное командой nbtstat.
Средство Nbtstat также может отображать кэшированные записи удаленных компьютеров, которые отмечены #PRE
в файле Lmhosts
или относятся к недавно разрешенным именам.
Если удаленные компьютеры используют для сервера одно и то же имя, а другие компьютеры находятся в удаленной подсети, убедитесь, что для них задано соответствие «имя-адрес» в файлах Lmhosts
или в серверах WINS
.
Способ 10 . Проверка удаленных подключений
Чтобы определить, почему не устанавливается подключение по протоколу TCP/IP с удаленным компьютером, выполните команду netstat -a
, показывающую состояние всех портов TCP и UDP локального компьютера.
Если подключение TCP работает нормально, в очередях Sent
(Отправлено
) и Received
(Получено
) отображается 0 байт.
Если в одной из этих очередей данные блокируются или они имеют состояние «irregular
», подключение может быть неисправно.
Если данные не блокируются, а очереди находятся в состоянии «typical
», то проблема, вероятно, вызвана задержкой в работе сети или программе.
Способ 11 . Проверка таблицы маршрутизации с помощью средства Route
Способ 12 . Проверка путей с помощью средства Tracert
Средство Tracert отправляет сообщения с эхо-запросами, увеличивая на каждом шаге значения в IP-заголовке поля TTL, чтобы определить сетевой путь между двумя узлами. Затем средство Tracert анализирует возвращенные сообщения ICMP.
Tracert позволяет прослеживать путь, не превышающий 30 прыжков.
Tracert определяет причину проблемы, когда при проходе через какой-либо маршрутизатор происходит ошибка или маршрут образует замкнутый цикл.
После того, как маршрутизатор, являющийся причиной проблемы, обнаружен, обратитесь к администратору маршрутизатора, если маршрутизатор находится в другой сети, или сами восстановите работоспособность маршрутизатора, если он находится под вашим управлением.
Способ 13 . Устранение неполадок в шлюзах
Если при настройке было получено приведенное ниже сообщение, выясните, находится ли шлюз по умолчанию в той же логической сети, что и сетевой адаптер компьютера:
Your default gateway does not belong to one of the configured interfaces
Сравните часть IP-адреса шлюза по умолчанию, соответствующую идентификатору сети, с идентификаторами сети сетевых адаптеров компьютера. В частности, проверьте, равен ли результат логического поразрядного И IP-адреса и маски подсети результату логического поразрядного И основного шлюза и маски подсети.



