Código que prohíbe el seguimiento de encabezados http. ¿Qué es un encabezado http? Descripción de los encabezados http
Comando de consola para imprimir encabezados:curl -yo http://sitio
Lista de códigos de respuesta del servidor
código de estado HTTP(Inglés) código de estado HTTP): el código de estado es parte de la primera línea de la respuesta del servidor. Es un número entero formado por 3 números arábigos. El primer dígito indica la clase de la condición. El código de respuesta suele ir seguido de una frase explicativa separada por un espacio. Inglés, que explica a la persona el motivo de esta respuesta en particular. Ejemplo:
403 Acceso permitido sólo para usuarios registrados
El cliente aprende del código de respuesta sobre los resultados de su solicitud y determina qué acciones tomar a continuación. El conjunto de códigos de estado es un estándar y todos ellos se describen en los documentos RFC correspondientes. Sólo deberían introducirse nuevos códigos tras un acuerdo con el IETF. Es posible que el cliente no conozca todos los códigos de estado, pero debe responder de acuerdo con la clase del código.
Actualmente existen cinco clases de códigos de estado:
- 1xx: informativo(Ruso) Informativo) - la solicitud se recibe y comprende y el procesamiento continúa.
- 2xx: Éxito(Ruso) Exitosamente) - la solicitud fue recibida, comprendida y procesada exitosamente.
- 3xx: Redirección(Ruso) Redirección) - se deben tomar medidas adicionales para completar la solicitud.
- 4xx: Error del cliente(Ruso) error del cliente): la solicitud tiene una sintaxis incorrecta o no se puede ejecutar.
- 5xx: Error del servidor(Ruso) error del servidor): el servidor no puede cumplir con una solicitud válida.
A continuación se muestran los códigos de respuesta del registro de códigos de estado de la IANA.
1xx: informativo
Esta clase contiene códigos que informan sobre el proceso de transferencia. En HTTP/1.0, los mensajes con dichos códigos deben ignorarse. En HTTP/1.1, el cliente debe estar preparado para aceptar esta clase de mensajes como una respuesta normal, pero no necesita enviar nada al servidor. Los propios mensajes del servidor contienen sólo la línea de inicio de la respuesta y, si es necesario, algunos campos de encabezado específicos de la respuesta. Servidores proxy mensajes similares debe enviarse más desde el servidor al cliente.
100 Continuar
(Ruso) Continuar)
El servidor está satisfecho con la información inicial sobre la solicitud. El cliente puede continuar reenviando encabezados.
101 protocolos de conmutación
(Ruso) Protocolos de conmutación)
El servidor ofrece cambiar a un protocolo más adecuado para el recurso especificado. El servidor debe indicar la lista de protocolos propuestos en el campo del encabezado Actualizar. Si el cliente está interesado en esto, envía nueva solicitud indicando un protocolo diferente.
102 Procesamiento
(Ruso) Procesamiento en curso)
La solicitud ha sido aceptada, pero llevará algún tiempo procesarla. mucho tiempo. Utilizado por el servidor para evitar que el cliente interrumpa la conexión debido a un tiempo de espera. Al recibir dicha respuesta, el cliente debe restablecer el temporizador y esperar siguiente comando en modo normal.
2xx: Éxito
Los mensajes de esta clase informan sobre casos de aceptación y procesamiento exitosos de una solicitud de cliente. Dependiendo del estado, el servidor también puede transmitir los encabezados y el cuerpo del mensaje.
200 bien
(Ruso) Bien)
Solicitud exitosa. Si el cliente solicitó algún dato, se encuentra en el encabezado y/o cuerpo del mensaje.
201 creado
(Ruso) Creado)
Como resultado de la ejecución exitosa de la solicitud, se creó un nuevo recurso. El servidor debe indicar su ubicación en el encabezado Ubicación. Se recomienda que el servidor también indique las características del recurso creado en el encabezado (por ejemplo, en el campo Tipo de contenido). Si el servidor no está seguro de que el recurso realmente exista cuando el cliente reciba este mensaje, entonces es mejor utilizar una respuesta 202.
202 Aceptado
(Ruso) Aceptado)
La solicitud ha sido aceptada para su procesamiento, pero el procesamiento no se ha completado. El cliente no tiene que esperar a la transmisión final del mensaje, ya que un proceso largo.
203 Información no autorizada
(Ruso) Información no autorizada)
Similar a la respuesta 200, pero en este caso la información transmitida no fue tomada de la fuente primaria ( copia de reserva, otro servidor, etc.) y por lo tanto puede no ser relevante.
204 Sin contenido
(Ruso) Sin contenido)
El servidor procesó con éxito la solicitud, pero la respuesta sólo contenía los encabezados sin el cuerpo del mensaje. El cliente no tiene que actualizar el contenido del documento, pero puede aplicarle los metadatos recibidos.
205 Restablecer contenido
(Ruso) Restablecer contenido)
El servidor obliga al cliente a solicitar información al usuario. El servidor no transmite el cuerpo del mensaje y no es necesario actualizar el documento.
206 Contenido parcial
(Ruso) Contenido parcial)
El servidor completó con éxito la solicitud del cliente, pero solo transfirió parte del documento. El servidor puede enviar dicha respuesta si el encabezado de la solicitud del cliente contiene el campo Rango de contenido. Atención especial Cuando trabaje con este tipo de respuestas, debe prestar atención al almacenamiento en caché.
207 Multiestado
(Ruso) Estado múltiple)
El servidor transmite los resultados de varias operaciones independientes a la vez. Se colocan en el cuerpo del mensaje como un documento XML con un único objeto multiestado. No se recomienda colocar estados de la serie 1xx en este objeto debido a la falta de sentido y la redundancia.
226 IM usado
(Ruso) IM usado)
El encabezado A-IM del cliente se recibió con éxito y el servidor devuelve el contenido teniendo en cuenta los parámetros especificados.
3xx: Redirección
Los códigos de estado de clase 3xx le dicen al cliente que para que la operación se realice correctamente, la siguiente solicitud debe realizarse a un URI diferente. En la mayoría de los casos nueva dirección indicado en el campo Ubicación del encabezado. En este caso, el cliente deberá, por regla general, hacer transición automática(jerga: redirigir).
Tenga en cuenta que cuando acceda al siguiente recurso, puede obtener una respuesta de la misma clase de código. Incluso puede haber una larga cadena de redirecciones, que de realizarse de forma automática crearían una carga excesiva en el equipo. Por lo tanto, los desarrolladores protocolo HTTP Se recomienda encarecidamente que después de la segunda respuesta consecutiva, asegúrese de solicitar la confirmación de la redirección al usuario (anteriormente se recomendaba después de la quinta). El cliente es responsable de monitorear esto, ya que el servidor actual puede redirigir al cliente a un recurso en otro servidor. El cliente también debe evitar realizar redireccionamientos circulares.
300 opciones múltiples
(Ruso) Múltiples opciones)
Dado el URI, existen varias opciones para proporcionar el recurso por tipo MIME, idioma u otras características. El servidor envía una lista de alternativas con el mensaje, lo que permite al cliente o usuario elegir.
301 movido permanentemente
(Ruso) Se mudó permanentemente)
El documento solicitado finalmente se movió al nuevo URI especificado en el campo Ubicación del encabezado. Para solicitudes distintas al método HEAD, el servidor debe enviar una explicación de hipertexto en el cuerpo del mensaje. Cuando utilice todos los métodos excepto GET y POST, primero debe notificar al usuario que el enlace ha cambiado. No olvide que algunos agentes cambian por error el método POST a GET después de mudarse a otra dirección.
302 encontrado
(Ruso) Encontró)
El documento solicitado se ha movido temporalmente a un URI diferente especificado en el campo Ubicación del encabezado. Para todos los métodos excepto HEAD, el servidor debe enviar una explicación de hipertexto en el cuerpo. Cuando utilice todos los métodos distintos de GET y POST, primero debe notificar al usuario que el URI ha cambiado. Al acceder al siguiente recurso, el método POST debe cambiarse a GET, como lo hacen algunos agentes.
303 Ver Otros
(Ruso) Ver otros)
El documento en la URI solicitada debe solicitarse a la dirección que figura en el campo Ubicación del encabezado mediante el método GET, aunque se haya solicitado el primero. método POST. Si no se utiliza el método HEAD, entonces el servidor DEBE incluir una breve descripción de hipertexto en el cuerpo del mensaje.
304 No modificado
(Ruso) No cambiado)
El servidor devuelve este código si el cliente solicitó un documento utilizando el método GET, utilizó el campo Fecha en el encabezado y el documento no ha cambiado desde el momento especificado. En este caso, el mensaje del servidor no debe contener cuerpo.
305 Usar proxy
(Ruso) Usar proxy)
La solicitud al recurso solicitado debe realizarse a través de un servidor proxy cuyo URI se especifica en el campo Ubicación del encabezado. Este código de respuesta solo puede ser utilizado por servidores HTTP nativos (no por servidores proxy).
306 (Reservado)
(Ruso) Reservado)
Usado antes. Actualmente reservado.
307 Redirección Temporal
(Ruso) Redirección temporal)
recurso solicitado poco tiempo accesible solo mediante un URI diferente (indicado en el campo Ubicación del encabezado). Si no se envió el método HEAD, entonces el servidor DEBE incluir una breve descripción de hipertexto en el cuerpo del mensaje. Cuando utilice todos los métodos excepto GET y POST, primero debe notificar al usuario sobre el cambio temporal del enlace.
4xx: Error del cliente
La clase de código 4xx está destinada a indicar errores en el lado del cliente. Cuando se utilizan todos los métodos excepto HEAD, el servidor debe devolver una explicación de hipertexto al usuario en el cuerpo del mensaje.
400 Solicitud incorrecta
(Ruso) Solicitud incorrecta)
El servidor no entendió la solicitud debido a un error de sintaxis. El cliente debe volver a acceder al recurso con la solicitud modificada.
401 No autorizado
(Ruso) No autorizado)
La solicitud requiere la identificación del usuario. El cliente debe solicitar un nombre de usuario y una contraseña al usuario y pasarlos a las entradas del encabezado WWW-Authenticate en la siguiente solicitud. Si se ingresan datos incorrectos, el servidor devolverá el mismo estado nuevamente.
402 Pago requerido
(Ruso) Pago requerido (reservado))
Diseñado para ser utilizado en el futuro. Actualmente no en uso.
403 Prohibido
(Ruso) Prohibido)
El servidor entendió la solicitud, pero se niega a cumplirla debido a algunas restricciones de acceso. La autenticación HTTP no ayudará aquí. Lo más probable es que el servidor necesite autenticarse de otra manera, realizar una solicitud con ciertos parámetros o cumplir algunas condiciones.
404 no encontrado
(Ruso) Extraviado)
El servidor entendió la solicitud, pero no encontró el recurso correspondiente en el URI especificado. Si el servidor sabe que había un documento en esta dirección, sería recomendable utilizar el código 410. Este código se puede utilizar en lugar de 403 si desea ocultarse cuidadosamente de ojos curiosos ciertos recursos.
Método 405 no permitido
(Ruso) Método no compatible)
El método especificado por el cliente no se puede aplicar al recurso. El servidor también debe enviar un campo Permitir en el encabezado de respuesta con una lista de métodos disponibles.
406 No Aceptable
(Ruso) No aceptable)
El URI solicitado no puede satisfacer las características pasadas en el encabezado. Si el método no era HEAD, entonces el servidor debe devolver una lista de características aceptables para este recurso.
Se requiere autenticación de proxy 407
(Ruso) Se requiere autorización de apoderado)
La respuesta es similar a un código 401, excepto que la autenticación es en un servidor proxy. El mecanismo es similar a la identificación en un servidor normal.
408 Tiempo de espera de solicitud
(Ruso) Tiempo agotado)
El servidor agotó el tiempo de espera de una transmisión del cliente. El cliente podrá repetir una solicitud anterior similar en cualquier momento.
409 Conflicto
(Ruso) Conflicto)
La solicitud no se pudo completar debido a un acceso conflictivo al recurso. Esto es posible, por ejemplo, cuando dos clientes intentan cambiar un recurso utilizando el método PUT.
410 desaparecido
(Ruso) Eliminado)
El servidor envía esta respuesta cuando el recurso solía estar en el URI especificado, pero se eliminó y ahora no está disponible. En este caso, el servidor no conoce la ubicación. documento alternativo(por ejemplo, copias). Si el servidor sospecha que el documento se puede restaurar en un futuro próximo, entonces mejor para el cliente envía el código 404.
411 Longitud requerida
(Ruso) Longitud requerida)
Para el recurso especificado, el cliente debe especificar Content-Length en el encabezado de la solicitud. Sin especificar este campo, no debe volver a intentar la solicitud al servidor utilizando este URI.
412 Condición previa fallida
(Ruso) Condición "falsa")
Se devuelve si no se cumple ninguno de los campos del encabezado de solicitud condicional.
413 Entidad de solicitud demasiado grande
(Ruso) Los datos solicitados son demasiado grandes.)
Devuelto si el servidor por algún motivo no puede transmitir la cantidad de información solicitada. Si el problema es temporal, entonces el servidor puede indicar en la respuesta el tiempo en el campo Reintentar después, después del cual se puede repetir una solicitud similar.
414 Solicitud-URI demasiado larga
(Ruso) El URI solicitado es demasiado largo)
El servidor no puede procesar la solicitud porque el URI especificado es demasiado largo. Este error se puede desencadenar, por ejemplo, cuando el cliente intenta pasar parámetros largos a través de OBTENER método, no PUBLICAR.
415 Tipo de medio no admitido
(Ruso) Tipo no admitido datos)
Por alguna razón, el servidor se niega a trabajar con el tipo de datos especificado cuando este método.
416 Rango solicitado no satisfactorio
(Ruso) El rango solicitado no es alcanzable)
El campo Rango en el encabezado de la solicitud especificaba un rango fuera del recurso y faltaba el campo If-Range. Si el cliente pasó un rango de bytes, entonces el servidor puede devolver tamaño real en el campo Rango de contenido del encabezado. Esta respuesta no debe utilizarse al transferir tipos de rangos de bytes/multipartes.
417 Expectativa fallida
(Ruso) Lo que se espera está mal)
Por alguna razón, el servidor no puede satisfacer el valor del campo Expect en el encabezado de la solicitud.
422 Entidad no procesable
(Ruso) Instancia sin procesar)
El servidor aceptó exitosamente la solicitud, puede trabajar con el tipo de datos especificado, el documento XML en el cuerpo de la solicitud tiene la sintaxis correcta, pero hay algún tipo de error lógico por el cual es imposible realizar una operación en el recurso.
423 bloqueado
(Ruso) Obstruido)
El recurso de destino de la solicitud no puede aplicarle el método especificado.
424 Dependencia fallida
(Ruso) Dependencia incumplida)
La ejecución de la solicitud actual puede depender del éxito de otra operación. Si no se completa y debido a esto la solicitud actual no se puede completar, entonces el servidor devolverá el código 424.
Actualización 426 requerida
(Ruso) Actualización requerida)
El servidor indica al cliente que es necesario actualizar el protocolo. El encabezado de respuesta debe contener campos Actualización y Conexión correctamente formados.
5xx: Error del servidor
Los códigos 5xx se asignan para casos de funcionamiento fallido debido a un fallo del servidor. Para todas las situaciones distintas al uso del método HEAD, el servidor debe incluir en el cuerpo del mensaje una explicación que el cliente mostrará al usuario.
500 Servidor interno Error
(Ruso) Error Interno del Servidor)
Cualquier error interno server, que no está incluido en el alcance de otros errores de clase 5xx.
501 no implementado
(Ruso) No factible)
El servidor no admite las capacidades necesarias para procesar la solicitud. Una respuesta típica para los casos en los que el servidor no comprende el método especificado en la solicitud.
502 Puerta de enlace no válida
(Ruso) Mala puerta de enlace)
El servidor que actúa como puerta de enlace o proxy recibió un mensaje que indicaba que falló una operación intermedia.
Servicio 503 no disponible
(Ruso) Servicio No Disponible)
El servidor no puede temporalmente procesar solicitudes a través de razones técnicas(mantenimiento, sobrecarga, etc.). En el campo del encabezado Retry-After, el servidor puede especificar el tiempo después del cual se recomienda al cliente repetir la solicitud. Si bien la opción obvia es interrumpir inmediatamente la conexión durante una sobrecarga, puede ser más efectivo establecer el campo Reintentar después en un valor grande para reducir la frecuencia de solicitudes redundantes.
504 Tiempo de espera de puerta de enlace
(Ruso) La puerta de enlace no responde)
El servidor que actúa como puerta de enlace o proxy no esperó una respuesta del servidor ascendente para completar la solicitud actual.
Versión HTTP 505 no compatible
(Ruso) Versión HTTP no compatible)
El servidor no admite o se niega a admitir la versión del protocolo HTTP especificada en la solicitud.
La variante 506 también negocia (experimental)
(Ruso) Opción también acordada (experimental))
Como consecuencia de una configuración errónea, la opción seleccionada apunta a sí misma, provocando que se interrumpa el proceso de emparejamiento.
507 Almacenamiento insuficiente
(Ruso) Se quedó sin espacio)
No hay suficiente espacio para completar la solicitud actual. El problema puede ser temporal.
510 No extendido
(Ruso) No ampliado)
El servidor no tiene la extensión que el cliente planea usar. El servidor también puede transmitir información sobre las extensiones disponibles.
Entonces, habiendo dominado el material presentado en este sitio y hecho intentos independientes de aprender HTML y CSS debería poder crear páginas web de complejidad básica y casi básica. Pero creo que es importante no sólo poder completar las tareas asignadas, sino también comprender cómo funcionan sus decisiones en todos los niveles de la organización. Una herramienta que puede ayudarte a acercarte a esto es ver los encabezados HTTP enviados por tu navegador al servidor web y viceversa.
En el artículo mencionado anteriormente, además de informacion teorica También se proporcionaron listados de encabezados HTTP utilizados por el navegador al realizar una solicitud. pagina de inicio sitio ya.ru y contenido en la respuesta del servidor web a la solicitud correspondiente. Pero es mucho más interesante (y más útil) ver cómo responde tu servidor a las solicitudes del navegador de tus páginas. Más adelante, al crear páginas HTML inteligentes, esto se convertirá en la clave para comprender los principios de la interacción activa entre el usuario y el sitio.
Como herramienta para ver encabezados HTTP, sugiero usar un complemento para navegador firefox Encabezados HTTP en vivo. Puede instalarlo así: Herramientas - Complementos - Buscar complementos, buscar la palabra "encabezados", instalar LiveHTTPHeaders. Después de reiniciar el navegador, aparecerá una nueva función: Herramientas - Ver encabezados HTTP.
Sugiero probar el complemento en la página creada en la lección anterior. Abra la ventana "Ver encabezados HTTP", haga clic en "borrar" para eliminar los encabezados que aparecen (cuando se le solicite pagina de inicio navegador, etcétera). A continuación realizamos una solicitud de página, por ejemplo, http://test-domain2/. Los encabezados de las solicitudes del navegador y de las respuestas del servidor web aparecieron en la ventana del encabezado:
El registro consta de tres bloques: primero viene la URL de la página solicitada, luego, a través de una línea vacía, los encabezados HTTP que se encuentran en la solicitud HTTP de esta página y, finalmente, los encabezados HTTP que se encuentran en la respuesta HTTP del servidor web. . Las entradas están separadas por líneas.
Para generar una página web, el navegador realiza varias solicitudes al servidor web: el código de la página en sí, archivos de estilo CSS, imágenes, etc. Todas estas solicitudes quedan reflejadas en el formulario. La primera es la solicitud de página HTML:
GET / HTTP/1.1 Host: dominio de prueba2 Agente de usuario: Mozilla/5.0 (Windows; U; Windows NT 5.1; ru; rv:1.9.2) Gecko/20100115 Firefox/3.6 Aceptar: text/html,application/xhtml+ xml ,application/xml;q=0.9,*/*;q=0.8 Idioma de aceptación: ru,en-us;q=0.7,en;q=0.3 Codificación de aceptación: gzip,deflate Conjunto de caracteres de aceptación: windows-1251, utf-8;q=0.7,*;q=0.7 Keep-Alive: 115 Conexión: keep-alive Pragma: sin caché Control de caché: sin caché
a lo que el servidor respondió:
HTTP/1.1 200 OK Fecha: viernes, 4 de junio de 2010 08:52:09 GMT Servidor: Apache Última modificación: miércoles, 26 de mayo de 2010 11:34:58 GMT Etiqueta electrónica: "3000000002878-20ca-4877da9e71c80" Rangos de aceptación: bytes Longitud del contenido: 8394 Keep-Alive: tiempo de espera = 5, máx = 100 Conexión: Keep-Alive Tipo de contenido: texto/html; juego de caracteres = UTF-8
En el encabezado de respuesta HTTP puedes ver el nombre del servidor web, el tamaño de la página en bytes y su codificación. Permítame recordarle que el complemento muestra encabezados HTTP, que forman parte del paquete HTTP. Su segunda parte, el cuerpo del paquete, no se muestra. Pero aquí todo es simple: las solicitudes normales de páginas/archivos no tienen un cuerpo en el paquete (aprenderemos sobre las inusuales más adelante), y el cuerpo en la respuesta representa el contenido de la página/archivo solicitado, que recibe el navegador. .
Lista de códigos de estado HTTP
El código de estado HTTP es parte de la primera línea de la respuesta del servidor. Es un número entero formado por tres números arábigos. El primer dígito indica la clase de la condición. El código de respuesta suele ir seguido de una frase explicativa en inglés separada por un espacio, que explica a la persona el motivo de esa respuesta en particular.
El cliente aprende del código de respuesta sobre los resultados de su solicitud y determina qué acciones tomar a continuación. El conjunto de códigos de estado es un estándar y se describen en los RFC correspondientes. Sólo deberían introducirse nuevos códigos tras un acuerdo con el IETF. Sin embargo, se sabe que se utilizan dos códigos que no se mencionan en el RFC: (introducido por Microsoft) e (introducido en cPanel).
Es posible que el cliente no conozca todos los códigos de estado, pero debe responder de acuerdo con la clase del código. Actualmente existen cinco clases de códigos de estado.
servidor web internet Los Servicios de Información en sus archivos de registro, además de los códigos de estado estándar, utilizan subcódigos, escribiéndolos con un punto después del principal. Al mismo tiempo, este subcódigo no se coloca en las respuestas del servidor; el administrador del servidor lo necesita para poder determinar con mayor precisión las fuentes de los problemas. Para obtener una lista de subcódigos de IIS, consulte el documento "Códigos de estado de IIS" en Microsoft Knowledge Base.
1xx: informativo
Esta clase contiene códigos que informan sobre el proceso de transferencia. En HTTP/1.0, los mensajes con dichos códigos deben ignorarse. En HTTP/1.1, el cliente debe estar preparado para aceptar esta clase de mensajes como una respuesta normal, pero no necesita enviar nada al servidor. Los propios mensajes del servidor contienen sólo la línea de inicio de la respuesta y, si es necesario, algunos campos de encabezado específicos de la respuesta. Los servidores proxy deben enviar dichos mensajes desde el servidor al cliente.
100 Continuar- El servidor está satisfecho con la información inicial sobre la solicitud, el cliente puede continuar enviando encabezados. Introducido en HTTP/1.1.
101 protocolos de conmutación- El servidor le solicita que seleccione otro protocolo que sea más apropiado este recurso. Los protocolos ofrecidos por el servidor se indican en la línea de encabezado Actualizar; si el protocolo propuesto por el servidor le conviene al cliente, envía una nueva solicitud indicando el nuevo protocolo. Apareció en la versión del protocolo HTTP/1.1.
102 Procesamiento- La solicitud ha sido aceptada, pero tardará bastante en procesarse. Utilizado por el servidor para evitar que el cliente interrumpa la conexión debido a un tiempo de espera. Al recibir dicha respuesta, el cliente debe restablecer el temporizador y esperar el siguiente comando como de costumbre. Introducido en WebDAV.
105 Nombre no resuelto- Se produjo un error al resolver el nombre de dominio debido a una dirección IP del servidor DNS incorrecta o faltante.
2xx: Éxito
Los mensajes de esta clase informan sobre casos de aceptación y procesamiento exitosos de una solicitud de cliente. Dependiendo del estado, el servidor también puede transmitir los encabezados y el cuerpo del mensaje.
200 bien- Solicitud exitosa. Si el cliente solicitó algún dato, se encuentra en el encabezado y/o cuerpo del mensaje. Introducido en HTTP/1.0.
201 creado- Como resultado de la ejecución exitosa de la solicitud, se creó un nuevo recurso. El servidor debe indicar su ubicación en el encabezado Ubicación. Se recomienda que el servidor también indique las características del recurso creado en el encabezado (por ejemplo, en el campo Tipo de contenido). Si el servidor no está seguro de que el recurso realmente exista cuando el cliente reciba este mensaje, entonces es mejor usar una respuesta con el código. Introducido en HTTP/1.0.
202 Aceptado- La solicitud fue aceptada a trámite, pero no se completó. El cliente no tiene que esperar a la transmisión final del mensaje, ya que puede comenzar un proceso muy largo. Introducido en HTTP/1.0.
203 Información no autorizada- Similar a la respuesta, pero en este caso la información transmitida no fue tomada de la fuente principal (copia de seguridad, otro servidor, etc.) y por lo tanto puede no estar actualizada. Introducido en HTTP/1.1.
204 Sin contenido- El servidor procesó correctamente la solicitud, pero la respuesta solo contenía encabezados sin el cuerpo del mensaje. El cliente no tiene que actualizar el contenido del documento, pero puede aplicarle los metadatos recibidos. Introducido en HTTP/1.0.
205 Restablecer contenido- El servidor obliga al cliente a restablecer los datos introducidos por el usuario. El servidor no transmite el cuerpo del mensaje y no es necesario actualizar el documento. Introducido en HTTP/1.1.
206 Contenido parcial- El servidor completó con éxito una solicitud GET parcial y devolvió solo una parte del mensaje. En el encabezado Content-Range, el servidor especifica los rangos de bytes del contenido. Cuando se trabaja con este tipo de respuestas, se debe prestar especial atención al almacenamiento en caché. Introducido en HTTP/1.1.
207 Multiestado- El servidor transmite los resultados de varias operaciones independientes a la vez. Se colocan en el cuerpo del mensaje como un documento XML con un objeto multiestado. No se recomienda colocar estados de la serie 1xx en este objeto debido a la falta de sentido y la redundancia. Introducido en WebDAV.
226 IM usado- El encabezado A-IM del cliente se recibió con éxito y el servidor devuelve el contenido teniendo en cuenta los parámetros especificados. Introducido en RFC 3229 para ampliar el protocolo HTTP con soporte de codificación delta.
3xx: Redirección
Los códigos de clase 3xx le dicen al cliente que se debe realizar una solicitud diferente (generalmente a un URI diferente) para que la operación tenga éxito. Hay cinco códigos de esta clase y se relacionan directamente con las redirecciones (jarg: redirigir). La dirección a la que el cliente debe realizar la solicitud la indica el servidor en el encabezado Ubicación. Sin embargo, es posible utilizar fragmentos en el URI de destino.
Según los últimos estándares, el cliente puede redirigir automáticamente (sin una solicitud del usuario) solo si el segundo recurso se solicita mediante el método GET o HEAD. Las especificaciones anteriores establecían que para evitar viajes de ida y vuelta, se debía preguntar al usuario después de la quinta redirección consecutiva. Para todas las redirecciones, si el método no era HEAD, entonces se debe incluir un breve mensaje de hipertexto con la dirección de destino en el cuerpo de la respuesta para que, si sucede algo, el usuario pueda realizar la transición él mismo.
Los desarrolladores de HTTP notan que muchos clientes, al redirigir con códigos, aplican por error el método GET al segundo recurso, a pesar de que la solicitud al primero se realizó con un método diferente. Para evitar malentendidos, en la versión HTTP/1.1 se introdujeron los códigos y en lugar de . Solo necesita cambiar el método si el servidor respondió. En otros casos, realice la siguiente solicitud utilizando el método original.
300 opciones múltiples- Para el URI especificado, existen varias opciones para proporcionar el recurso por tipo MIME, por idioma u otras características. El servidor envía una lista de alternativas con el mensaje, lo que permite al cliente o usuario elegir automáticamente. Introducido en HTTP/1.0.
301 movido permanentemente- El documento solicitado finalmente se ha movido al nuevo URI especificado en el campo Ubicación del encabezado. Algunos clientes se comportan incorrectamente al procesar este código. Introducido en HTTP/1.0.
302 movido temporalmente / encontrado- El documento solicitado está disponible temporalmente en un URI diferente especificado en el encabezado del campo Ubicación. Este código se puede utilizar, por ejemplo, en la negociación de contenidos impulsada por el servidor. Algunos clientes se comportan incorrectamente al procesar este código. Introducido en HTTP/1.0.
303 Ver Otros- El documento en la URI solicitada debe solicitarse a la dirección que figura en el campo Ubicación del encabezado mediante el método GET, aunque el primero se haya solicitado mediante un método diferente. Este código se introdujo junto con el 307 para evitar ambigüedades, de modo que el servidor pudiera estar seguro de que el siguiente recurso se solicitará mediante el método GET. Por ejemplo, una página web tiene un campo de entrada de texto para una navegación y búsqueda rápidas. Después de ingresar los datos, el navegador realiza una solicitud mediante el método POST, incluyendo el texto ingresado en el cuerpo del mensaje. Si se detecta un documento con el nombre ingresado, el servidor responde con el código, indicándolo en el encabezado Ubicación Dirección permanente. Entonces se garantiza que el navegador lo solicitará mediante el método GET para obtener el contenido. De lo contrario, el servidor simplemente devolverá la página de resultados de búsqueda al cliente. Introducido en HTTP/1.1.
304 No modificado- El servidor devuelve este código si el cliente solicitó un documento usando el método GET, usó el encabezado If-Modified-Since o If-None-Match y el documento no ha cambiado desde el momento especificado. En este caso, el mensaje del servidor no debe contener cuerpo. Introducido en HTTP/1.0.
305 Usar proxy- La petición al recurso solicitado debe realizarse a través de un servidor proxy cuyo URI se especifica en el campo Ubicación del encabezado. Este código de respuesta solo puede ser utilizado por servidores HTTP de origen (no por servidores proxy). Introducido en HTTP/1.1.
306 (Reservado, código utilizado solo en las primeras especificaciones)- El código de respuesta utilizado anteriormente está actualmente reservado. Mencionado en RFC 2616 (actualización HTTP/1.1).
307 Redirección Temporal- El recurso solicitado está disponible brevemente en un URI diferente especificado en el campo Ubicación del encabezado. Este código se introdujo junto con 302 en lugar de 302 para evitar ambigüedades. Introducido en RFC 2616 (actualización HTTP/1.1).
4xx: Error del cliente
La clase de código 4xx está destinada a indicar errores en el lado del cliente. Cuando se utilizan todos los métodos excepto HEAD, el servidor debe devolver una explicación de hipertexto al usuario en el cuerpo del mensaje.
400 Solicitud incorrecta- El servidor detectó un error de sintaxis en la solicitud del cliente. Introducido en HTTP/1.0.
401 No autorizado- Se requiere autenticación para acceder al recurso solicitado. El encabezado de respuesta debe contener el campo WWW-Authenticate con una lista de condiciones de autenticación. El cliente puede repetir la solicitud incluyendo el campo Autorización en el encabezado del mensaje con los datos requeridos para la autenticación.
402 Pago requerido- Diseñado para ser utilizado en el futuro. Actualmente no en uso. Este código está destinado a servicios de usuario pagos, no a empresas de alojamiento. Esto significa que este error no será emitido por el proveedor de hosting en caso de pago vencido por sus servicios. Reservado desde HTTP/1.1.
403 Prohibido- El servidor entendió la solicitud, pero se niega a cumplirla debido a restricciones en el acceso del cliente al recurso especificado. Si se requiere autenticación mediante HTTP para acceder a un recurso, el servidor devolverá una respuesta o si se utiliza un proxy. De lo contrario, las restricciones fueron establecidas por el administrador del servidor o el desarrollador de la aplicación web y pueden ser cualquier cosa dependiendo de las capacidades del software utilizado. En cualquier caso, se deberá informar al cliente de los motivos por los que se niega a tramitar la solicitud. Mayoría razones probables Pueden surgir restricciones al intentar acceder a los recursos del sistema del servidor web (por ejemplo, archivos .htaccess o .htpasswd) o archivos a los que se les negó el acceso usando archivos de configuración, un requisito de autenticación no HTTP, por ejemplo, para acceder a un sistema de gestión de contenidos o una sección para usuarios registrados, o el servidor no está satisfecho con la dirección IP del cliente, por ejemplo, al bloquear. Introducido en HTTP/1.0.
404 no encontrado- El error más común al utilizar Internet, el motivo principal es un error al escribir la dirección de la página Web. El servidor entendió la solicitud, pero no encontró el recurso correspondiente en el URI especificado. Si el servidor sabe que había un documento en esta dirección, es recomendable que utilice el código. La respuesta se puede utilizar en su lugar si necesita ocultar cuidadosamente ciertos recursos de miradas indiscretas. Introducido en HTTP/1.0.
Método 405 no permitido- El método especificado por el cliente no se puede aplicar al recurso actual. En la respuesta, el servidor debe indicar los métodos disponibles en el encabezado Permitir, separados por una coma. El servidor debe devolver este error si conoce el método, pero no es aplicable específicamente al recurso especificado en la solicitud; si el método especificado no es aplicable en todo el servidor, entonces el cliente debe devolver el código (No implementado); ). Introducido en HTTP/1.1.
406 No Aceptable- El URI solicitado no puede satisfacer las características pasadas en el encabezado. Si el método no era HEAD, entonces el servidor debe devolver una lista de características aceptables para este recurso. Introducido en HTTP/1.1.
Se requiere autenticación de proxy 407- La respuesta es similar al código excepto que la autenticación se realiza para el servidor proxy. El mecanismo es similar a la identificación en el servidor original. Introducido en HTTP/1.1.
408 Tiempo de espera de solicitud- El servidor ha agotado el tiempo de espera de la transmisión del cliente. El cliente podrá repetir una solicitud anterior similar en cualquier momento. Por ejemplo, esta situación puede surgir al cargar un archivo grande al servidor mediante el método POST o PUT. En algún momento durante la transferencia, la fuente de datos dejó de responder, por ejemplo, debido a daños en el CD o pérdida de comunicación con otra computadora en la red local. Mientras el cliente no transmite nada, a la espera de una respuesta del mismo, se mantiene la conexión con el servidor. Después de un tiempo, el servidor puede cerrar la conexión para permitir que otros clientes realicen una solicitud. Esta respuesta no se devuelve cuando el cliente detiene la transmisión por la fuerza por orden del usuario o la conexión se interrumpe por algún otro motivo, ya que la respuesta ya no se puede enviar. Introducido en HTTP/1.1.
409 Conflicto- La solicitud no se pudo completar debido a un acceso conflictivo al recurso. Esto es posible, por ejemplo, cuando dos clientes intentan cambiar un recurso utilizando el método PUT Introducido en HTTP/1.1.
410 desaparecido (eliminado)- El servidor envía esta respuesta si el recurso solía estar en la URL especificada, pero se eliminó y ahora no está disponible. En este caso, el servidor no conoce la ubicación del documento alternativo (por ejemplo, una copia). Si el servidor sospecha que el documento puede restaurarse en un futuro próximo, es mejor pasar el código al cliente. Introducido en HTTP/1.1.
411 Longitud requerida- Para el recurso especificado, el cliente debe especificar Content-Length en el encabezado de la solicitud. Sin especificar este campo, no debe volver a intentar la solicitud al servidor utilizando este URI. Esta respuesta es natural para consultas. tipo de publicación y PON. Por ejemplo, si los archivos se descargan utilizando el URI especificado y el servidor tiene un límite en su tamaño. Entonces sería más razonable comprobar el encabezado Content-Length desde el principio y rechazar inmediatamente la descarga, en lugar de provocar una carga sin sentido al interrumpir la conexión cuando el cliente envía un mensaje que es demasiado grande. Introducido en HTTP/1.1.
412 Condición previa fallida- Se devuelve si no se cumple ninguno de los campos del encabezado de solicitud condicional. Introducido en HTTP/1.1.
413 Entidad de solicitud demasiado grande- Se devuelve si el servidor se niega a procesar la solicitud debido a que el cuerpo de la solicitud es demasiado grande. El servidor puede cerrar la conexión para detener la transmisión adicional de la solicitud. Si el problema es temporal, se recomienda incluir un encabezado Retry-After en la respuesta del servidor que indique el tiempo después del cual se puede repetir una solicitud similar. Introducido en HTTP/1.1.
414 Solicitud-URI demasiado grande- El servidor no puede procesar la solicitud porque la URL especificada es demasiado larga. Este error puede desencadenarse, por ejemplo, cuando el cliente intenta pasar parámetros largos mediante el método GET en lugar del método POST. Introducido en HTTP/1.1.
415 Tipo de medio no admitido- Por alguna razón, el servidor se niega a trabajar con el tipo de datos especificado utilizando este método. Introducido en HTTP/1.1.
416 Rango solicitado no satisfactorio- en el campo Rango del encabezado de la solicitud, se especificó un rango fuera del recurso y faltaba el campo If-Range. Si el cliente pasó un rango de bytes, entonces el servidor puede devolver el tamaño real en el campo Rango de contenido del encabezado. Esta respuesta no debe utilizarse al transferir tipos de rangos de bytes/multipartes. Introducido en RFC 2616 (actualización HTTP/1.1).
417 Expectativa fallida- Por alguna razón, el servidor no puede satisfacer el valor del campo Expect en el encabezado de la solicitud. Introducido en RFC 2616 (actualización HTTP/1.1).
418 Soy una tetera (soy una tetera)- Este código se introdujo en 1998 como uno de los chistes tradicionales del Día de los Inocentes del IETF en RFC 2324, Protocolo de control de cafeteras de hipertexto. No se espera que este codigo Será compatible con servidores reales.
422 Entidad no procesable- El servidor recibió exitosamente la solicitud, puede trabajar con el tipo de datos especificado, el documento XML en el cuerpo de la solicitud tiene la sintaxis correcta, pero hay algún tipo de error lógico por el cual es imposible realizar una operación en el recurso. Ingresado en WebDAV.
423 bloqueado- El recurso de destino de la solicitud no puede aplicarle el método especificado. Ingresado en WebDAV.
424 Dependencia fallida- La implementación de la solicitud actual puede depender del éxito de otra operación. Si no se completa y debido a esto la solicitud actual no se puede completar, entonces el servidor devolverá este código. Ingresado en WebDAV.
425 Colección desordenada- utilizado en la extensión del Protocolo de colecciones avanzadas WebDAV. Enviado si el cliente especificó el número de un elemento en una lista desordenada, o solicitó varios elementos en un orden diferente al del servidor.
Actualización 426 requerida- El servidor indica al cliente la necesidad de actualizar el protocolo. El encabezado de respuesta debe contener campos Actualización y Conexión correctamente formados. Introducido en RFC 2817 para permitir la transición a TLS a través de HTTP.
428 Condición previa requerida- El servidor indica al cliente la necesidad de utilizar encabezados de condición en la solicitud, como If-Match. Introducido en el borrador RFC 6585.
429 Demasiadas solicitudes- El cliente intentó enviar demasiadas solicitudes en poco tiempo, lo que podría indicar, por ejemplo, un intento de ataque DoS. Puede ir acompañado de un encabezado Retry-After que indica después de qué hora se puede repetir la solicitud. Introducido en el borrador RFC 6585.
431 Campos de encabezado de solicitud demasiado grandes- Se ha superado la longitud permitida de los encabezados. No es necesario que el servidor responda con este código; simplemente puede restablecer la conexión. Introducido en el borrador RFC 6585.
434 El host solicitado no está disponible. (La dirección solicitada no está disponible)- La dirección solicitada no está disponible.
449 Reintentar con- Devuelto por el servidor si no se recibió información suficiente del cliente para procesar la solicitud. En este caso, el campo Ms-Echo-Request se coloca en el encabezado de la respuesta. Introducido por Microsoft para WebDAV. Actualmente al menos en uso programa de microsoft Dinero.
451 No disponible por razones legales- El acceso al recurso está cerrado por motivos legales, por ejemplo, a petición de las autoridades gubernamentales o a petición del titular de los derechos de autor en caso de infracción de derechos de autor. Introducido en el borrador del IETF por Google, siendo el código de error una referencia a la novela Fahrenheit 451 de Ray Bradbury.
Error 456 irrecuperable- Devuelto por el servidor si el procesamiento de la solicitud provoca fallas incorregibles en las tablas de la base de datos. Introducido por Microsoft para WebDAV.
499 () - Utilizado por Nginx cuando el cliente cierra la conexión antes de recibir una respuesta.
5xx: Error del servidor
Los códigos 5xx se asignan para casos de funcionamiento fallido debido a un fallo del servidor. Para todas las situaciones distintas al uso del método HEAD, el servidor debe incluir en el cuerpo del mensaje una explicación que el cliente mostrará al usuario.
500 Error interno del servidor- Cualquier error interno del servidor que no esté incluido en el alcance de otros errores de clase. Introducido en HTTP/1.0.
501 no implementado- El servidor no admite las capacidades necesarias para procesar la solicitud. Una respuesta típica para los casos en los que el servidor no comprende el método especificado en la solicitud. Si el servidor conoce el método, pero no es aplicable a este recurso, entonces deberá devolver una respuesta. Introducido en HTTP/1.0.
502 Puerta de enlace no válida- El servidor, que actúa como puerta de enlace o proxy, recibió un mensaje de respuesta no válido del servidor ascendente. Introducido en HTTP/1.0.
Servicio 503 no disponible- El servidor no puede procesar solicitudes temporalmente por motivos técnicos (mantenimiento, sobrecarga, etc.). En el campo del encabezado Retry-After, el servidor puede especificar el tiempo después del cual se recomienda al cliente repetir la solicitud. Aunque puede parecer obvio interrumpir inmediatamente la conexión durante una sobrecarga, puede ser más eficaz establecer el campo Reintentar después en un valor grande para reducir la frecuencia de solicitudes redundantes. Introducido en HTTP/1.0.
504 Tiempo de espera de la puerta de enlace (la puerta de enlace no responde)- El servidor que actúa como puerta de enlace o servidor proxy no esperó una respuesta del servidor ascendente para completar la solicitud actual. Introducido en HTTP/1.1.
Versión HTTP 505 no compatible- El servidor no admite o se niega a admitir la versión del protocolo HTTP especificada en la solicitud. Introducido en HTTP/1.1.
La variante 506 también negocia- Como consecuencia de una configuración errónea, la opción seleccionada apunta a sí misma, provocando que se interrumpa el proceso de emparejamiento. Experimental. Introducido en RFC 2295 para complementar el protocolo HTTP con tecnología de negociación de contenido transparente.
507 Almacenamiento insuficiente- No hay suficiente espacio para completar la solicitud actual. El problema puede ser temporal. Ingresado en WebDAV.
508 Bucle detectado -
509 ancho de banda Límite excedido(Ancho de banda del canal agotado)- Se utiliza cuando un sitio web excede su límite de consumo de tráfico asignado. EN en este caso El propietario del sitio debe ponerse en contacto con su proveedor de alojamiento. De momento este código no está descrito en ningún RFC y es utilizado únicamente por el módulo "bw/limited" incluido en la central alojamiento cpanel, donde fue introducido.
510 No extendido- El servidor no tiene la extensión que el cliente quiere utilizar. El servidor también puede transmitir información sobre las extensiones disponibles. Introducido en RFC 2774 para agregar soporte para extensiones al protocolo HTTP.
Se requiere autenticación de red 511- Esta respuesta no la envía el servidor al que estaba destinada la solicitud, sino un servidor intermediario, por ejemplo, el servidor del proveedor, en caso de que el cliente primero deba iniciar sesión en la red, por ejemplo, ingresar una contraseña para un pago. Punto de acceso a Internet. Se supone que el cuerpo de la respuesta devolverá un formulario de autorización web o redirigirá a él. Introducido en el borrador RFC 6585.
Utilizando encabezados http, la información del servicio se intercambia entre el cliente y el servidor. Esta información permanece invisible para los usuarios, pero sin ella es imposible. trabajo correcto navegador. Para usuarios comunes La información sobre esto y el propósito de los encabezados http parecerá bastante compleja, pero en realidad no contiene formulaciones difíciles. Esto es algo que un usuario de la web encuentra todos los días.
titulares?
"Protocolo de transferencia de hipertexto" es exactamente como se traduce. Gracias a su existencia, la comunicación cliente-servidor es posible. En términos simples, el usuario del navegador envía una solicitud e inicia una conexión con el servidor. Este último, por defecto, espera una solicitud del cliente, la procesa y devuelve la información o respuesta final. En la barra de búsqueda, el usuario "ingresa" la dirección del sitio que comienza con http:// y recibe el resultado en forma de una página que se abre.
Cuando se escribe la dirección del sitio en la línea correspondiente, el navegador encuentra el servidor requerido mediante DNS. El servidor reconoce el encabezado http (uno o más) que le envía el cliente y luego emite el encabezado requerido. El conjunto de encabezados requeridos consta de encabezados ya existentes y aquellos que no se encuentran.
En general, los encabezados http son bastante efectivos. No son visibles en la codificación HTML; se envían antes de la información solicitada. El servidor envía muchos encabezados automáticamente. Para enviarlo a lenguaje PHP, debes usar la función de encabezado.

Interacción entre el navegador y el sitio web
La interacción entre el navegador y el sitio es bastante sencilla. Entonces, el encabezado http comienza la línea de solicitud, que luego se envía al servidor. la respuesta viene necesitado por el cliente información. Por cierto, el protocolo http es el más utilizado en Internet desde hace diecisiete años. Es simple, confiable, rápido y flexible. La tarea principal de http es solicitar información de un servidor web. El cliente es el navegador y el servidor es ligthttp, apache, nginx. Si la conexión entre ellos fue exitosa, el servidor recibe la información necesaria en respuesta a la solicitud. La información http contiene texto, archivos de sonido, video.
El protocolo puede ser un transporte para otros. La solicitud del cliente consta de tres partes:
- línea de inicio (tipo de mensaje);
- encabezados (parámetros del mensaje);
- cuerpo de la información (un mensaje separado por una línea en blanco).
La línea de inicio es un elemento obligatorio de la solicitud del campo del encabezado http. La estructura de una solicitud de usuario consta de tres partes principales:
- Método. Se utiliza para indicar el tipo de solicitud.
- Camino. Este cadena de URL, que sigue al dominio.
- Protocolo utilizado. Consta de un protocolo y una versión http.
Los navegadores modernos utilizan la versión 1.1. Los siguientes son encabezados en el formato "Nombre: valor".

almacenamiento en caché HTTP
La conclusión es que el almacenamiento en caché garantiza que las páginas HTML y otros archivos se almacenen en un caché (espacio en la memoria operativa, en el disco duro de la computadora). Esto es necesario para acelerar el acceso repetido a ellos y ahorrar tráfico.
El caché tiene un navegador cliente, una puerta de enlace intermedia y un servidor proxy. Antes de enviar un mensaje a una URL, el navegador comprobará si el objeto está en la caché. Si no hay ningún objeto, la solicitud se pasa al siguiente servidor, donde se verifica almacenamiento en caché http titulares en servidor nginx. Se utilizan puertas de enlace y servidores proxy. por diferentes usuarios, por lo que el caché se comparte.
El almacenamiento en caché HTTP no sólo puede acelerar significativamente el sitio, sino también proporcionar una versión antigua de la página. Esto se utiliza para enviar encabezados a la respuesta. Sin embargo, la información solicitada mediante el protocolo HTTPS no se puede almacenar en caché.

Descripción de los encabezados http
Uno de los mecanismos de caché más importantes es http. expira encabezados. Estos encabezados indican la fecha de vencimiento de la información proporcionada en la respuesta. Indican la hora y la fecha en que el caché se considerará obsoleto. Por ejemplo, un encabezado de este tipo se ve así: Vence: Wen, 30 de noviembre de 2016 a las 13:45:00 GMT. esta estructura Se utiliza en casi todas partes, incluso para almacenar en caché páginas e imágenes. Si el usuario selecciona una fecha anterior, la información no se almacenará en caché.
Los encabezados de proxy HTTP pertenecen a la categoría de enlace de encabezado. No se almacenan en caché de forma predeterminada. Para que la caché funcione correctamente, cada URL debe coincidir con una variante del contenido. Si una página es bilingüe, cada versión debe tener su propia URL. El encabezado de variación le dice al caché los nombres de los encabezados de solicitud. Por ejemplo, si la visualización de una solicitud depende del navegador, el servidor también debe enviar un encabezado. Por tanto, en la memoria caché se almacenan diferentes opciones de consulta y tipos de documentos. El encabezado de aceptación TTP es necesario para compilar listas de formatos aceptables del recurso utilizado, es bastante fácil trabajar con él, ya que filtra los innecesarios;
Hay un total de cuatro grupos de encabezados que transmiten información de servicio. Estos son los encabezados básicos: están contenidos en cualquier mensaje, solicitud, respuesta y entidad del servidor y del cliente. Estos últimos describen el contenido de cualquier mensaje del cliente y el servidor.
El encabezado de autorización HTTP se considera opcional. Cuando una página web solicita autorización al cliente, el navegador muestra una ventana especial con campos para ingresar un nombre de usuario y contraseña. Después de que el usuario ingresa su información, el navegador envía una solicitud http. Contiene el encabezado "autorización".

¿Cómo puedo ver los títulos?
Para ver el encabezado http, debe instalar complementos del navegador, por ejemplo, Firefox:
- Insecto de fuego. Puede ver los encabezados en la pestaña de red, donde selecciona todos. Este complemento tiene características que serán útiles para un desarrollador web.
- Encabezados http en vivo. Un complemento simple diseñado para ver encabezados http. Con su ayuda, puede generar una solicitud manualmente.
- Los usuarios de Ghrome verán fácilmente los encabezados si hacen clic en el botón de configuración y seleccionan herramientas de desarrollo (networks).
Una vez que los complementos estén instalados, ejecútelos en su navegador.
Métodos de consulta
Los métodos utilizados en HTTP son similares a las instrucciones que se envían como mensaje al servidor. Esta es una palabra especial en inglés.
- OBTENER método. Se utiliza para solicitar información de un recurso. Aquí es donde comienzan todas las acciones.
- CORREO. Se utiliza para enviar datos. Por ejemplo, un mensaje en red social o un comentario, el navegador lo coloca en el cuerpo de la solicitud POST y lo envía al servidor.
- CABEZA. El método es similar al primero, pero realiza función fácil. Solo solicita metadatos, excluyendo el mensaje de la respuesta. Este método se utiliza si desea obtener información sobre archivos sin descargarlos. Se utiliza si quieren comprobar la funcionalidad de los enlaces en el servidor.
- PONER. Carga datos en una URL. Transfiere grandes cantidades de datos.
- OPCIONES. Funciona con configuraciones de servidor.
- URI. Identifica el recurso y contiene la URL.

Estructura de respuesta HTTP
El servidor responde a las solicitudes de los clientes. mensajes largos. La respuesta consta de varias líneas que indican la versión del protocolo y el código de estado del servidor (200). Le indica qué ha cambiado en el servidor mientras procesaba la solicitud entrante:
- El estado "doscientos" indica un procesamiento exitoso de la información. Luego, el servidor envía el documento al cliente. Las líneas restantes de la solicitud indican otra información sobre la información que se transmite.
- Si el archivo no se encuentra o no existe, el servidor envía un código 404 al cliente, también llamado error.
- El código 206 indica una descarga parcial del archivo, que puede reanudarse después de un tiempo.
- El código 401 indica denegación de autorización. Esto significa que la página solicitada está protegida por una contraseña, que debe ingresarse para confirmar la entrada.
- El código 403 indica acceso prohibido. Las prohibiciones de ver, descargar archivos o vídeos son una respuesta común en Internet.
- También existen otras versiones de los códigos: movimiento temporal del archivo solicitado, error interno del servidor, movimiento permanente. En este caso, el usuario será redirigido. Si aparece el código 500, significa que hay problemas con el servidor.
URL: ¿qué es?
La URL es el corazón de la comunicación web entre cliente y servidor. La solicitud normalmente se envía a través de una URL: el Localizador uniforme de recursos. La estructura de solicitud de URL es muy simple. Consta de varios elementos: protocolo http (encabezado), pitido (dirección del sitio), puerto, ruta de recursos y consulta.
El protocolo también está disponible para conexión segura https e intercambio de información. Una URL contiene información sobre la ubicación de un sitio particular en Internet. La dirección incluye el nombre de dominio, la ruta a la página y su título.
La principal desventaja de trabajar con URL es la incómoda interacción con el alfabeto latino, así como con números y símbolos. La optimización juega un papel importante en el SEO.

Se anima a los usuarios y desarrolladores activos de ordenadores a familiarizarse con algunas recomendaciones profesionales dadas por expertos en este campo:
- Indicar fechas de vencimiento de expedientes y documentos, teniendo en cuenta las actualizaciones. Información estadística indicado en valores grandes edad máxima
- Solo se debe poder acceder a un único documento a través de una URL.
- Si está actualizando un archivo que será descargado por un usuario, cambie su nombre y vincúlelo. Esto garantiza que se descargue un documento nuevo y no uno desactualizado.
- Los encabezados de Última modificación deben corresponder a la fecha real en que se modificó el contenido por última vez. No debe volver a guardar páginas y documentos a menos que los cambie.
- Utilice solicitudes POST solo cuando sea necesario. Mantenga el trabajo de SSL al mínimo.
- Los encabezados deben verificarse con el complemento REDbot antes de ser enviados por el servidor.
Cuando abrimos cualquier página web del sitio que necesitamos, junto con el código HTML de la página, el servidor transmite el código de estado de la solicitud y los encabezados http. Mediante el código de estado, los programas pueden determinar rápidamente si todo fue exitoso o, por ejemplo, si dicha página no existe en el servidor. Los encabezados contienen información para el navegador que le indica cómo procesar la página y qué hacer con ella.
Los usuarios habituales no necesitarán esta información, pero si es administrador del sitio o especialista técnico, puede resultarle muy útil. En este artículo veremos cómo verificar el código de respuesta del servidor y los encabezados http usando la utilidad curl.
Para funcionamiento normal varios programas Al trabajar a través del protocolo HTTP, el servidor devuelve no solo el texto de la página, sino también un código de tres dígitos que le permite determinar el resultado de la solicitud. Con este código, no solo puede describir qué error ocurrió durante el procesamiento, sino también redirigir al usuario a otra página o decir que la página no ha sido modificada. Estos son los códigos de respuesta del servidor más comunes:
1xx - informativo:
- 100 - el servidor ha aceptado la primera parte de la solicitud, puede retrasar la transmisión;
- 101 - es necesario cambiar el protocolo de trabajo por uno más adecuado;
- 102 - procesar la solicitud llevará mucho tiempo, se utiliza para que el navegador no interrumpa la conexión antes de tiempo;
2xx - operación exitosa:
- 200 - la solicitud se completó con éxito y se envió a la mayoría de las páginas solicitadas;
- 201 - una vez completada la solicitud, se creó el recurso;
- 202 - la solicitud ha sido aceptada, pero aún no ha sido procesada;
- 203 - la solicitud se completó con éxito, pero la información para la respuesta se tomó del proxy;
- 204 - la solicitud ha sido procesada, pero no hay contenido para mostrar;
- 205 - pedir al usuario que introduzca los datos requeridos;
- 206 - la solicitud ha sido tramitada, pero sólo se ha transmitido una parte del contenido;
3xx - redirecciones:
- 300 - hay varias páginas para esta solicitud, por ejemplo en varios idiomas;
- 301 - la página se ha movido permanentemente a una nueva dirección;
- 302 - el documento ha sido movido temporalmente;
- 303 - el documento debe cargarse en la dirección especificada utilizando el protocolo GET;
- 304 - el documento no ha cambiado desde la última solicitud;
- 305 - necesitas utilizar un proxy;
- 307 - el recurso se ha movido temporalmente a una nueva dirección.
4хх - error en la solicitud:
- 400 - solicitud no válida;
- 401 - necesita autenticarse;
- 403 - la solicitud ha sido aceptada, pero usted no tiene acceso;
- 404 - página no encontrada en el servidor;
- 405 - el método utilizado no se puede utilizar en el servidor;
- 408 - el tiempo de espera de transmisión de la solicitud ha expirado;
- 410 - el recurso se elimina por completo;
- 411 - debe especificar la duración de la solicitud;
- 413 - la solicitud es demasiado larga;
- 414 - El URI de solicitud es demasiado largo.
5xx - error del servidor:
- 500 - Error Interno del Servidor;
- 501 - función requerida no soportado;
- 502 - el proxy no puede conectarse a la puerta de enlace;
- 503 - el servidor no puede procesar solicitudes por motivos técnicos;
- 504 - el proxy no esperó una respuesta del servidor;
- 505 - La versión del protocolo HTTP no es compatible.
¿Qué son los encabezados http?
CON usando http encabezados, el cliente y el servidor intercambian información y comandos entre sí. Se utilizan para acordar método, protocolo, codificación, idioma y muchos otros parámetros operativos. Veamos los encabezados principales que enviará el servidor:
- Servidor- nombre y versión del servidor web;
- Fecha- fecha de solicitud;
- Tipo de contenido - tipo MIME la codificación de los datos transmitidos, por ejemplo texto/html, se establece inmediatamente;
- Conexión- tipo de conexión, puede ser cerrada (ya cerrada) o mantener activa (abierta para transferencia de datos);
- Variar- indica bajo qué encabezados el servidor web devolverá diferentes valores para el mismo URI;
- Conjunto de cookies- guardar información de cookies para la página;
- Vence- puedes almacenar una página o recurso en un caché hasta una fecha determinada;
- Control de caché- configurar el tiempo de almacenamiento en caché de la página por parte del navegador, así como los permisos de almacenamiento en caché;
- etiqueta ET- contiene una suma de verificación para la página, aplicable para verificar el caché;
- Última modificación- fecha en que la página último tiempo ha sido cambiado;
Todo esto fue una introducción para que puedas entender lo que vamos a hacer a continuación, ya que consideraremos no solo cómo ver los encabezados y la respuesta del servidor, sino también cuáles deberían ser para tu sitio.
Comprobando el código de respuesta del servidor usando cURL
Para ver solo el código de respuesta de la página, simplemente ejecute el siguiente comando:
curl -s -o /dev/null -w "%(http_code)" https://sitio
O, si quieres que la respuesta parezca más natural:
rizo -yo https://sitio2>
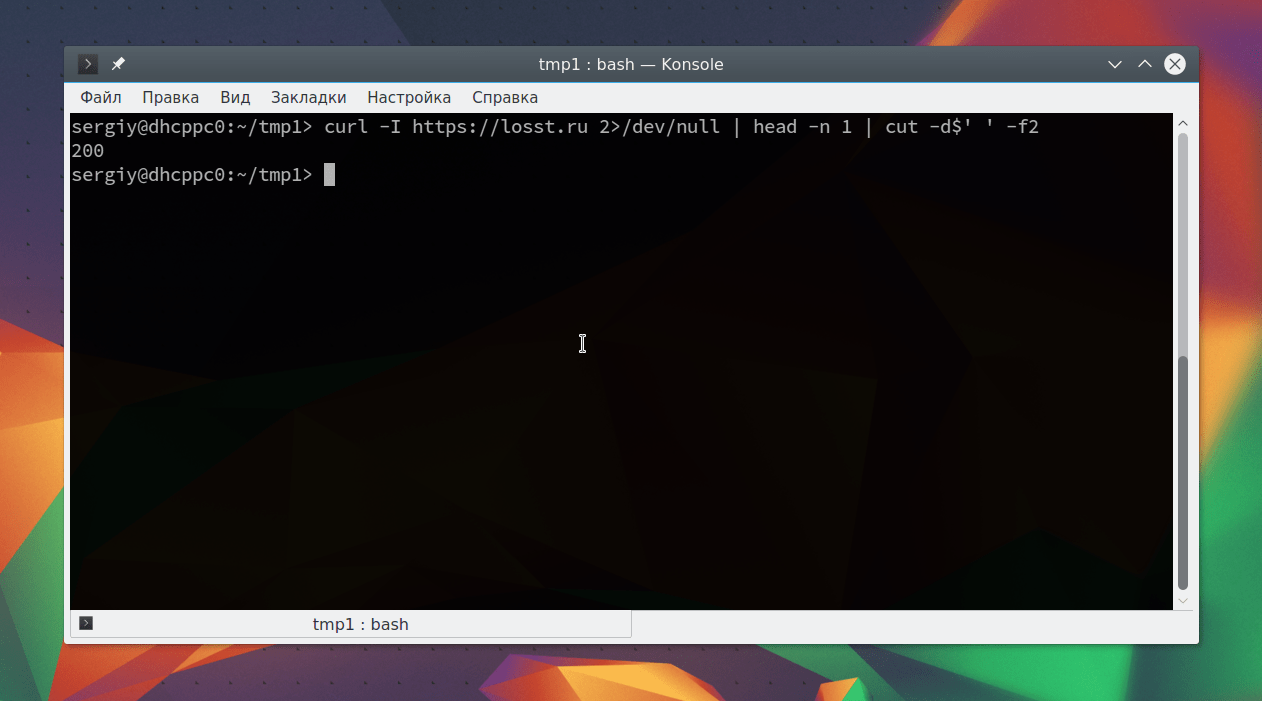
Páginas devueltas 200, todo está bien. ¿Pero el servidor envía una redirección a las páginas que necesitamos? Si su sitio se ejecuta en https, entonces todas las solicitudes http deben transferirse a https, también para cualquier sitio, todas las solicitudes a dominio www debe ser redirigido al principal, o viceversa. Idealmente, las solicitudes de IP de un sitio también deberían enviarse al dominio principal. Comprobando la respuesta http:
curl -I http://sitio2>/dev/null | cabeza -n 1 | cortar -d$" " -f2
curl -I https://www.site2>/dev/null | cabeza -n 1 | cortar -d$" " -f2

Todo funciona como debería. Pero es poco probable que sea necesario mirar el código de respuesta del servidor; verificar los estados http es mucho más interesante.
Comprobando encabezados http usando Curl
También podemos utilizar la utilidad curl para comprobar los encabezados. Para mostrar encabezados de página, ejecútelo con la opción -I:
rizo -yo https://sitio

Aquí se muestra el código de respuesta del servidor, así como los encabezados http aceptados. De ellos podemos sacar las siguientes conclusiones:
- La página se generó en nginx 1.10.2;
- esto es normal pagina html(texto/html);
- Tamaño de página 102452 bytes o 100 kb;
- La página fue modificada por última vez a las 18:13:12 (última modificación). Esto es muy parámetro importante para motores de búsqueda;
- El servidor ofrecerá diferentes versiones de páginas cuando cambie el campo Aceptar-Codificación (Variar);
- La página se puede almacenar en cualquier caché (pública) durante una hora (caduca);
De esta manera, se pueden verificar los encabezados http de cualquier página o recurso para determinar inmediatamente si todo se está enviando correctamente. Por ejemplo, veamos los encabezados de la imagen:
rizo -I https://site/wp-content/uploads/2016/08/map-2.png

Podemos ver que la imagen se almacenará en el caché por mucho más tiempo (edad máxima) que la página html.
Queda por comprobar si funcionan encabezados como If-Modified-Since y If-None-Match. El primero le permite verificar la relevancia del caché por fecha de modificación, el segundo, por la suma de verificación del campo ETag. El caché es muy importante para reducir la carga en su servidor. Si la página no ha cambiado, el servidor solo informa que no ha cambiado enviando un código de respuesta 304, en lugar de enviar el archivo completo.
Por supuesto que puedes usar para esto. servicios en línea, pero funcionan mal y no siempre muestran el valor correcto. Por lo tanto, volvemos a utilizar curl.
Si-Modificado-Desde cheque
Primero solicitamos a nuestra página que vea los encabezados http y luego copiamos el campo Última modificación:
rizo -yo https://sitio

Ahora lo volvemos a pedir, pero esta vez con encabezado Si-Modificado-Desde: y tu fecha:

En respuesta, no debería recibir la página en sí, sino solo el encabezado HTTP/1.1 304 No modificado. Si es así, entonces se pasó la verificación del código de respuesta del servidor y todo está funcionando correctamente.
Verificación si no hay coincidencia
El encabezado If-None-Match funciona de manera similar, solo que usa el valor suma de control caché del campo ETag. Solicitemos nuevamente nuestra página y copiemos el monto:
rizo -yo https://sitio

Luego enviaremos el importe recibido con el encabezado:
curl -I --header "If-None-Match: "58615db8-19034"" https://sitio

Y nuevamente deberíamos recibir una respuesta 304, la página no ha cambiado.
Comprobación de compresión
La compresión le permite reducir el tamaño de los datos transferidos, pero al mismo tiempo crea una carga adicional en el servidor. Para comprobar si el servidor es compatible compresión gzip debe enviar el encabezado Accept-Encoding con el parámetro gzip en la solicitud:
curl -I https://sitio --header "Aceptar codificación: gzip"

En la respuesta veremos el campo Content-Encoding: gzip. Esto indicará que se está utilizando compresión.
Conclusiones
En este artículo vimos cómo se verifica la respuesta del servidor y los encabezados http, esto puede ser muy útil para realizar auditorías. lado técnico su sitio, así como para resolver ciertos problemas. Espero que la información contenida en este artículo te haya resultado útil.
Sobre el autor
Fundador y administrador del sitio, apasionado por el software y los sistemas operativos de código abierto. sistema linux. Actualmente uso Ubuntu como mi sistema operativo principal. Además de Linux, me interesa todo lo relacionado con las tecnologías de la información y la ciencia moderna.



