F tabular. Criterio exacto de Fisher. Estimación de la relación entre ganancias y costos utilizando la función de Fisher.
Devuelve la inversa de la distribución de probabilidad F (de cola derecha). Si p = FRIST(x;...), entonces FRIST(p;...) = x.
La distribución F se puede utilizar en una prueba F, que compara el grado de dispersión de dos conjuntos de datos. Por ejemplo, puede analizar la distribución del ingreso de Estados Unidos y Canadá para determinar si los dos países son similares en términos de densidad de ingreso.
Importante: Esta característica ha sido reemplazada por una o más características nuevas que brindan más alta precisión y tener nombres que reflejen mejor su propósito. Aunque esta característica todavía se utiliza para proporcionar compatibilidad con versiones anteriores, es posible que deje de estar disponible en el futuro Versiones de Excel, por lo que recomendamos utilizar las nuevas funciones.
Para obtener más información sobre las nuevas funciones, consulte los artículos Función F.REV y Función F.REV.PH.
Sintaxis
FRIST(probabilidad,grados_libertad1,grados_libertad2)
Los argumentos de la función FALTER se describen a continuación.
Probabilidad- argumento requerido. Probabilidad asociada a la distribución F acumulada.
Grados_de_libertad1- argumento requerido. Numerador de grados de libertad.
Grados_de_libertad2- argumento requerido. Denominador de grados de libertad.
Notas
Si alguno de los argumentos no es un número, FRATE devuelve el valor de error #¡VALOR!
Si "probabilidad"< 0 или "вероятность" >1, la función FRIST devuelve el valor de error #¡NUM!.
Si el valor de grados_libertad1 o grados_libertad2 no es un número entero, se trunca.
Si "grados_libertad1"< 1 или "степени_свободы1" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!.
Si "grados_libertad2"< 1 или "степени_свободы2" ≥ 10^10, функция FРАСПОБР возвращает значение ошибки #ЧИСЛО!.
La función FDIST se puede utilizar para determinar los valores críticos de la distribución F. Por ejemplo, los resultados de ANOVA normalmente incluyen datos para el estadístico F, la probabilidad F y valor crítico Distribución F con un nivel de significancia de 0,05. Para determinar el valor crítico de F, es necesario utilizar el nivel de significancia como argumento de probabilidad de la función FDIST.
Por valor ajustado probabilidad, la función FDIST busca un valor de x para el cual FDIST(x, grados_libertad1, grados_libertad2) = probabilidad. Por tanto, la precisión de la función FDIST depende de la precisión de FDIST. Para buscar, la función FRIST utiliza un método de iteración. Si la búsqueda no finaliza después de 100 iteraciones, se devuelve el valor de error #N/A.
Ejemplo
Copie los datos de muestra de la siguiente tabla y péguelos en la celda A1 del nuevo hoja de Excel. Para mostrar los resultados de las fórmulas, selecciónelas y presione F2, luego presione Enter. Si es necesario, cambia el ancho de las columnas para ver todos los datos.
La función FISCHER devuelve la transformada de Fisher de los argumentos a X . Esta transformación produce una función que tiene una distribución normal en lugar de sesgada. La función FISCHER se utiliza para probar la hipótesis utilizando el coeficiente de correlación.
Descripción de la función FISCHER en Excel
Al trabajar con esta función, debe establecer el valor de la variable. Inmediatamente vale la pena señalar que hay algunas situaciones en las que esta función no producirá resultados. Esto es posible si la variable:
- no es un número. En tal situación, la función FISCHER devolverá el valor de error #¡VALOR!;
- tiene un valor menor que -1 o mayor que 1. En en este caso La función FISCHER devolverá el valor de error #¡NUM!
La ecuación que se utiliza para descripción matemática La función FISCHER tiene la forma:
Z"=1/2*ln(1+x)/(1-x)
Veamos el uso de esta función usando 3 ejemplos específicos.
Estimación de la relación entre ganancias y costos utilizando la función de FISHER
Ejemplo 1. Utilizando datos sobre la actividad de organizaciones comerciales, es necesario evaluar la relación entre las ganancias Y (millones de rublos) y los costos X (millones de rublos) utilizados para el desarrollo de productos (que se muestran en la Tabla 1).
Tabla 1 – Datos iniciales:
| № | X | Y |
| 1 | 210.000.000,00 rublos | 95.000.000,00 rublos |
| 2 | 1.068.000.000,00 rublos | 76.000.000,00 rublos |
| 3 | 1.005.000.000,00 rublos | 78.000.000,00 rublos |
| 4 | 610.000.000,00 rublos | 89.000.000,00 rublos |
| 5 | 768.000.000,00 rublos | 77.000.000,00 rublos |
| 6 | 799.000.000,00 rublos | 85.000.000,00 rublos |
El esquema para resolver tales problemas es el siguiente:
- Calculado coeficiente lineal correlaciones r xy ;
- La importancia del coeficiente de correlación lineal se comprueba mediante la prueba t de Student. En este caso, se plantea y prueba la hipótesis de que el coeficiente de correlación es igual a cero. El estadístico t se utiliza para probar esta hipótesis. Si se confirma la hipótesis, el estadístico t tiene una distribución de Student. Si valor calculado t p > t cr, entonces se rechaza la hipótesis, que indica la significancia del coeficiente de correlación lineal, y por tanto la significancia estadística de la relación entre X e Y;
- Se determina una estimación de intervalo para un coeficiente de correlación lineal estadísticamente significativo.
- Se determina una estimación de intervalo para el coeficiente de correlación lineal basándose en transformada z inversa Pescador;
- Se calcula el error estándar del coeficiente de correlación lineal.
Los resultados de resolver este problema con las funciones utilizadas en paquete excel se muestran en la Figura 1.

Figura 1 – Ejemplo de cálculos.
| No. | Nombre del indicador | Fórmula de cálculo |
| 1 | Coeficiente de correlación | =CORRECCIÓN(B2:B7,C2:C7) |
| 2 | Valor de prueba t calculado tp | =ABS(C8)/SQRT(1-POWER(C8,2))*SQRT(6-2) |
| 3 | Valor de la tabla de la prueba t trh | = ESTUDIAR DESCUBRIR (0.05,4) |
| 4 | Valor de la tabla de distribución normal estándar zy | =SINVNORMA((0,95+1)/2) |
| 5 | Valor de transformación z de Fisher | =PESCADOR(C8) |
| 6 | Estimación del intervalo izquierdo para z | =C12-C11*RAÍZ(1/(6-3)) |
| 7 | Estimación del intervalo derecho para z | =C12+C11*RAÍZ(1/(6-3)) |
| 8 | Estimación del intervalo izquierdo para rxy | =PESCADORBR(C13) |
| 9 | Estimación del intervalo derecho para rxy | =PESCADORBR(C14) |
| 10 | Desviación estándar para rxy | =RAÍZ((1-C8^2)/4) |
Así, con una probabilidad de 0,95, el coeficiente de correlación lineal se encuentra en el rango de (–0,386) a (–0,990) con un error estándar de 0,205.
Comprobación de la significancia estadística de la regresión utilizando la función MÁS RÁPIDO
Ejemplo 2. Verificar significancia estadística ecuaciones regresión múltiple Utilizando la prueba F de Fisher, saque conclusiones.
Para comprobar la importancia de la ecuación en su conjunto, planteamos la hipótesis H 0 sobre la insignificancia estadística del coeficiente de determinación y la hipótesis opuesta H 1 sobre la importancia estadística del coeficiente de determinación:
H 1: R 2 ≠ 0.
Probemos las hipótesis utilizando la prueba F de Fisher. Los indicadores se muestran en la Tabla 2.
Tabla 2 - Datos iniciales
Para ello utilizamos la función en Excel:
MÁS RÁPIDO (α;p;n-p-1)
- α es la probabilidad asociada con una distribución dada;
- p y n son el numerador y denominador de los grados de libertad, respectivamente.
Sabiendo que α = 0,05, p = 2 y n = 53, obtenemos el siguiente valor para F crit (ver Figura 2).
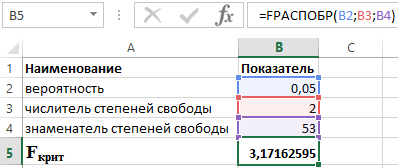
Figura 2 – Ejemplo de cálculos.
Así podemos decir que F calculado > F crítico. Como resultado, se acepta la hipótesis H 1 sobre la significancia estadística del coeficiente de determinación.
Calcular el valor del indicador de correlación en Excel.
Ejemplo 3. Utilizando datos de 23 empresas sobre: X es el precio del producto A, en miles de rublos; Y es el beneficio de una empresa comercial, se estudia su dependencia en millones de rublos; El modelo de regresión se estimó de la siguiente manera: ∑(yi-yx) 2 = 50000; ∑(yi-yср) 2 = 130000. ¿Qué indicador de correlación se puede determinar a partir de estos datos? Calcule el valor del indicador de correlación y, utilizando el criterio de Fisher, saque una conclusión sobre la calidad del modelo de regresión.
Determinemos F crítico a partir de la expresión:
F calculado = R 2 /23*(1-R 2)
donde R es el coeficiente de determinación igual a 0,67.
Por tanto, el valor calculado F calc = 46.
Para determinar F crítico utilizamos la distribución de Fisher (ver Figura 3).

Figura 3 – Ejemplo de cálculos.
Por tanto, la estimación resultante de la ecuación de regresión es confiable.
En en este ejemplo Consideremos cómo se evalúa la confiabilidad de la ecuación de regresión resultante. La misma prueba se utiliza para probar la hipótesis de que los coeficientes de regresión son simultáneamente iguales a cero, a=0, b=0. En otras palabras, la esencia de los cálculos es responder a la pregunta: ¿se pueden utilizar para análisis y pronósticos adicionales?
Para determinar si las varianzas en dos muestras son similares o diferentes, utilice esta prueba t.
Entonces, el propósito del análisis es obtener alguna estimación con la cual se pueda afirmar que a un cierto nivel de α la ecuación de regresión resultante es estadísticamente confiable. Para esto Se utiliza el coeficiente de determinación R 2..
La prueba de significancia de un modelo de regresión se lleva a cabo mediante la prueba F de Fisher, cuyo valor calculado se encuentra como la relación entre la varianza de la serie original de observaciones del indicador en estudio y la estimación insesgada de la varianza de la secuencia residual. para este modelo.
Si el valor calculado con k 1 =(m) y k 2 =(n-m-1) grados de libertad es mayor que el valor tabulado en un nivel de significancia dado, entonces el modelo se considera significativo.
donde m es el número de factores en el modelo.
Estimación de la significancia estadística de un par. regresión lineal se lleva a cabo según el siguiente algoritmo:
1. Se plantea la hipótesis nula de que la ecuación en su conjunto es estadísticamente insignificante: H 0: R 2 =0 en el nivel de significancia α.
2. A continuación, determine el valor real del criterio F: ![]()
![]()
donde m=1 para regresión por pares.
3. El valor de la tabla se determina a partir de las tablas de distribución de Fisher para nivel dado significancia, teniendo en cuenta que el número de grados de libertad para la suma total de cuadrados (mayor varianza) es 1 y el número de grados de libertad para la suma residual de cuadrados (menor varianza) en regresión lineal es n-2 (o a través de la función de Excel F DIST(probabilidad;1;n -2)).
La tabla F es el máximo. posible significado criterio bajo la influencia de factores aleatorios en determinados grados de libertad y nivel de significancia α. El nivel de significancia α es la probabilidad de rechazar la hipótesis correcta, siempre que sea cierta. Normalmente se considera que α es 0,05 o 0,01.
4. Si el valor real de la prueba F es menor que el valor de la tabla, entonces dicen que no hay razón para rechazar la hipótesis nula.
En caso contrario, se rechaza la hipótesis nula y se acepta con probabilidad (1-α) la hipótesis alternativa sobre la significancia estadística de la ecuación en su conjunto.
Tabla de valores del criterio con grados de libertad k 1 =1 y k 2 =48, F tabla = 4
conclusiones: Dado que el valor real F > F tabla, el coeficiente de determinación es estadísticamente significativo ( la estimación de la ecuación de regresión encontrada es estadísticamente confiable) .
Análisis de variación
.Indicadores de calidad de la ecuación de regresión.
Ejemplo. Sobre la base de un total de 25 empresas comerciales, se estudia la relación entre las siguientes características: X - precio del producto A, en miles de rublos; Y es el beneficio de una empresa comercial, millones de rublos. Al evaluar el modelo de regresión se obtuvieron los siguientes resultados intermedios: ∑(y i -y x) 2 = 46000; ∑(y i -y avg) 2 = 138000. ¿Qué indicador de correlación se puede determinar a partir de estos datos? Calcule el valor de este indicador basándose en este resultado y utilizando Prueba F de Fisher Sacar conclusiones sobre la calidad del modelo de regresión.
Solución. A partir de estos datos podemos determinar la relación de correlación empírica: 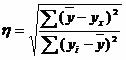 , donde ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000.
, donde ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000.
η 2 = 92.000/138.000 = 0,67, η = 0,816 (0,7< η < 0.9 - связь между X и Y высокая).
Prueba F de Fisher: norte = 25, metro = 1.
R 2 = 1 - 46000/138000 = 0,67, F = 0,67/(1-0,67)x(25 - 1 - 1) = 46. Tabla F (1; 23) = 4,27
Dado que el valor real F > Ftabla, la estimación encontrada de la ecuación de regresión es estadísticamente confiable.
Pregunta: ¿Qué estadísticas se utilizan para probar la importancia de un modelo de regresión?
Respuesta: Para determinar la importancia de todo el modelo en su conjunto, se utiliza el estadístico F (prueba de Fisher).
Criterio exacto La prueba de Fisher es un criterio que se utiliza para comparar dos indicadores relativos que caracterizan la frecuencia de una característica particular que tiene dos valores. Los datos iniciales para calcular la prueba exacta de Fisher suelen agruparse en forma de tabla de cuatro campos.
1. Historia del desarrollo del criterio.
El criterio fue propuesto por primera vez. Ronald Fisher en su libro Diseño de experimentos. Esto sucedió en 1935. El propio Fischer afirmó que Muriel Bristol le impulsó esta idea. A principios de la década de 1920, Ronald, Muriel y William Roach estaban destinados en Inglaterra, en una estación experimental agrícola. Muriel afirmó que podía determinar el orden en que se vertían el té y la leche en su taza. En ese momento no fue posible verificar la veracidad de su declaración.
Esto dio origen a la idea de Fisher de la "hipótesis nula". El objetivo no era demostrar que Muriel pudiera distinguir entre tazas de té preparadas de diferentes maneras. Se decidió refutar la hipótesis de que una mujer elige al azar. Se determinó que la hipótesis nula no podía ser probada ni justificada. Pero esto se puede refutar mediante experimentos.
Se prepararon 8 tazas. Los primeros cuatro se llenan primero con leche y los otros cuatro con té. Las tazas estaban mezcladas. Bristol se ofreció a probar el té y dividir las tazas según el método de preparación del té. El resultado debería haber sido dos grupos. La historia dice que el experimento fue un éxito.
Gracias al test de Fisher, la probabilidad de que Bristol estuviera actuando intuitivamente se redujo a 0,01428. Es decir, fue posible identificar correctamente la copa en un caso de 70. Pero aún así, no hay forma de reducir a cero las posibilidades de que Madame determine por casualidad. Incluso si aumentas el número de tazas.
Esta historia impulsó el desarrollo de la “hipótesis nula”. Al mismo tiempo, se propuso el criterio exacto de Fisher, cuya esencia es enumerar todos posibles combinaciones variables dependientes e independientes.
2. ¿Para qué se utiliza la prueba exacta de Fisher?
La prueba exacta de Fisher se utiliza principalmente para comparar. pequeñas muestras. Hay dos para esto buenas razones. En primer lugar, el cálculo del criterio es bastante engorroso y puede llevar mucho tiempo o requerir potentes recursos informáticos. En segundo lugar, el criterio es bastante preciso (lo que se refleja incluso en su nombre), lo que permite su uso en estudios con un pequeño número observaciones.
En medicina se concede un lugar especial a la prueba exacta de Fisher. Este es un método importante para procesar datos médicos y ha encontrado su aplicación en muchos investigación científica. Gracias a él, es posible estudiar la relación entre determinados factores y resultados, comparar la frecuencia de condiciones patológicas entre dos grupos de sujetos, etc.
3. ¿En qué casos se puede utilizar la prueba exacta de Fisher?
- Las variables que se comparan deben medirse en escala nominal y solo tengo dos significados, Por ejemplo, presion arterial normal o aumentada, resultado favorable o desfavorable, complicaciones postoperatorias presentes o no.
- La prueba exacta de Fisher está destinada a la comparación. dos grupos independientes, dividido por la base del factor. Por consiguiente, el factor también debería tener sólo dos valores posibles.
- La prueba es adecuada para comparar muestras muy pequeñas: la prueba exacta de Fisher se puede utilizar para analizar tablas de cuatro partes en el caso de valores del fenómeno esperado inferiores a 5, lo que supone una limitación para el uso del chi-cuadrado de Pearson. prueba, incluso teniendo en cuenta la corrección de Yates.
- La prueba exacta de Fisher puede ser unilateral y bilateral. Con una opción unilateral, se sabe exactamente dónde se desviará uno de los indicadores. Por ejemplo, un estudio compara cuántos pacientes se recuperaron en comparación con un grupo de control. Se supone que la terapia no puede empeorar la condición de los pacientes, sino sólo curarla o no.
Una prueba de dos colas evalúa las diferencias de frecuencia en dos direcciones. Es decir, se evalúa la probabilidad de una frecuencia mayor y menor del fenómeno en el grupo experimental en comparación con el grupo de control.
Un análogo de la prueba exacta de Fisher es la prueba de chi-cuadrado de Pearson, mientras que la prueba exacta de Fisher tiene más Alto Voltaje, especialmente cuando se comparan muestras pequeñas y, por tanto, tiene una ventaja en este caso.
4. ¿Cómo calcular la prueba exacta de Fisher?
Digamos que estamos estudiando la dependencia de la frecuencia de nacimientos de niños con malformaciones congénitas (CDD) del tabaquismo materno durante el embarazo. Para ello se seleccionaron dos grupos de mujeres embarazadas, uno de los cuales fue un grupo experimental, formado por 80 mujeres que fumaron en el primer trimestre del embarazo, y el segundo fue un grupo de comparación, que incluyó a 90 mujeres que fumaron en el primer trimestre. del embarazo. imagen saludable vida durante todo el embarazo. El número de casos de malformaciones congénitas fetales determinadas por datos de ultrasonido en el grupo experimental fue 10, en el grupo de comparación - 2.
Primero componemos tabla de contingencia de cuatro campos:
La prueba exacta de Fisher se calcula mediante la siguiente fórmula:
donde N es el número total de sujetos en dos grupos; ! - factorial, que es el producto de un número y una secuencia de números, cada uno de los cuales es menor que el anterior en 1 (por ejemplo, 4! = 4 3 2 1)
Como resultado de los cálculos, encontramos que P = 0,0137.
5. ¿Cómo interpretar el valor de la prueba exacta de Fisher?
La ventaja del método es que el criterio resultante corresponde al valor exacto del nivel de significancia. pag. Es decir, el valor de 0,0137 obtenido en nuestro ejemplo es el nivel de significancia de las diferencias entre los grupos comparados en la frecuencia de desarrollo de malformaciones congénitas del feto. Sólo es necesario comparar este número con el nivel crítico de significancia, generalmente aceptado en investigación médica por 0,05.
- Si el valor de la prueba exacta de Fisher es mayor que el valor crítico, se acepta hipótesis nula y se concluye que no existen diferencias estadísticamente significativas en la incidencia del desenlace dependiendo de la presencia de un factor de riesgo.
- Si el valor de la prueba exacta de Fisher es inferior al crítico, se acepta hipótesis alternativa y se concluye que existen diferencias estadísticamente significativas en la incidencia del desenlace dependiendo de la exposición al factor de riesgo.
En nuestro ejemplo P< 0,05, в связи с чем делаем вывод о наличии прямой взаимосвязи курения и вероятности развития ВПР плода. Частота возникновения врожденной патологии у детей курящих женщин estadísticamente significativamente mayor que los no fumadores.
1. Tabla de valores de la prueba F de Fisher para el nivel de significancia α = 0,05
| 1 | 2 | 3 | 4 | 5 | 6 | 8 | 12 | 24 | ∞ | |
| 1 | 161,45 | 199,50 | 215,72 | 224,57 | 230,17 | 233,97 | 238,89 | 243,91 | 249,04 | 254,32 |
| 2 | 18,51 | 19,00 | 19,16 | 19,25 | 19,30 | 19,33 | 19,37 | 19,41 | 19,45 | 19,50 |
| 3 | 10,13 | 9,55 | 9,28 | 9,12 | 9,01 | 8,94 | 8,84 | 8,74 | 8,64 | 8,53 |
| 4 | 7,71 | 6,94 | 6,59 | 6,39 | 6,26 | 6,16 | 6,04 | 5,91 | 5,77 | 5,63 |
| 5 | 6,61 | 5,79 | 5,41 | 5, 19 | 5,05 | 4,95 | 4,82 | 4,68 | 4,53 | 4,36 |
| 6 | 5,99 | 5,14 | 4,76 | 4,53 | 4,39 | 4,28 | 4,15 | 4,00 | 3,84 | 3,67 |
| 7 | 5,59 | 4,74 | 4,35 | 4,12 | 3,97 | 3,87 | 3,73 | 3,57 | 3,41 | 3,23 |
| 8 | 5,32 | 4,46 | 4,07 | 3,84 | 3,69 | 3,58 | 3,44 | 3,28 | 3,12 | 2,93 |
| 9 | 5,12 | 4,26 | 3,86 | 3,63 | 3,48 | 3,37 | 3,23 | 3,07 | 2,90 | 2,71 |
| 10 | 4,96 | 4,10 | 3,71 | 3,48 | 3,33 | 3,22 | 3,07 | 2,91 | 2,74 | 2,54 |
| 11 | 4,84 | 3,98 | 3,59 | 3,36 | 3, 20 | 2,95 | 2,79 | 2,61 | 2,40 |
Cuando m=1, seleccione 1 columna.
k 2 =n-m=7-1=6 - es decir, la sexta línea - toma valor de la tabla Pescador
Tabla F = 5,99, promedio anual. = total: 7
La influencia de x sobre y es moderada y negativa.
ŷ - valor del modelo.
| F cálculo. = | 28,648: 1 | = 0,92 |
| 200,50: 5 |
A = 1/7 * 398,15 * 100% = 8,1%< 10% -
valor aceptable
El modelo es bastante preciso.
F cálculo. = 1/0,92 =1,6
F cálculo. = 1,6< F табл. = 5,99
Debería ser F calc. >Tabla F
violado Este modelo, por lo que esta ecuación no es estadísticamente significativa.
Dado que el valor calculado es menor que el valor de la tabla, el modelo es insignificante.
| 1 | Σ | (y - ŷ) | *100% | |
| norte | y |
Error de aproximación.
A= 1/7*0,563494* 100% = 8,04991% 8,0%
Consideramos que el modelo es preciso si el error de aproximación promedio es inferior al 10%.
Identificación de pares paramétricos regresión no lineal
Modelo y = a * x b - función de potencia
Para aplicar la fórmula conocida, es necesario logaritmar el modelo no lineal.
iniciar sesión y = iniciar sesión a + b iniciar sesión x
Y=C+b*X -Modelo lineal.
C = 1,7605 - (- 0,298) * 1,7370 = 2,278
Volver al modelo original
Ŷ=10 s *x b =10 2,278 *x -0,298
| No. | Ud. | X | Y | X | Y*X | Ud. | Yo (y-ŷ)/yI | |
| 1 | 68,80 | 45,10 | 1,8376 | 1,6542 | 3,039758 | 2,736378 | 60,9614643 | 0,113932 |
| 2 | 61, 20 | 59,00 | 1,7868 | 1,7709 | 3,164244 | 3,136087 | 56,2711901 | 0,080536 |
| 3 | 59,90 | 57, 20 | 1,7774 | 1,7574 | 3,123603 | 3,088455 | 56,7931534 | 0,051867 |
| 4 | 56,70 | 61,80 | 1,7536 | 1,7910 | 3,140698 | 3, 207681 | 55,4990353 | 0,021181 |
| 5 | 55,00 | 58,80 | 1,7404 | 1,7694 | 3,079464 | 3,130776 | 56,3281590 | 0,024148 |
| 6 | 54,30 | 47, 20 | 1,7348 | 1,6739 | 2,903882 | 2,801941 | 60,1402577 | 0,107555 |
| 7 | 49,30 | 55, 20 | 1,6928 | 1,7419 | 2,948688 | 3,034216 | 57,3987130 | 0,164274 |
| Total | 405, 20 | 384,30 | 12,3234 | 12,1587 | 21,40034 | 21,13553 | 403,391973 | 0,563493 |
| Promedio | 57,88571 | 54,90 | 1,760486 | 1,736957 | 3,057191 | 3,019362 | 57,62742 | 0,080499 |
Ingresamos a EXCEL a través del programa "Inicio". Ingresamos los datos en la tabla. En "Herramientas" - "Análisis de datos" - "Regresión" - Aceptar
Si el menú "Herramientas" no tiene la línea "Análisis de datos", entonces debe instalarse a través de "Herramientas" - "Configuración" - "Paquete de análisis de datos"
Previsión de la demanda de productos empresariales. Uso en EM funciones de excel"Tendencia"
A es la demanda del producto. B - tiempo, días
| No. | A | |
| 1 | 11 | 1 |
| 2 | 14 | 2 |
| 3 | 13 | 3 |
| 4 | 15 | 4 |
| 5 | 17 | 5 |
| 6 | 17,9 | |
| 7 | 18,4 | 7 |
Paso 1. Preparar los datos iniciales
Paso 2. Extienda el eje de tiempo, configúrelo en 6,7 hacia adelante; Tenemos derecho a predecir 1/3 de los datos.
Paso 3. Seleccione el rango A6: A7 en pronóstico futuro.
Paso 4. Insertar función
Insertar diagrama de gráficos suaves no estándar
rango y listo.

Si cada valor posterior de nuestro eje de tiempo difiere no en un pequeño porcentaje, sino varias veces, entonces no es necesario utilizar la función "Tendencia", sino la función "Crecimiento".
Bibliografía
1. Eliseeva “Econometría”
2. Eliseeva "Taller de econometría"
3. Carlsberg "Excel para fines de análisis"
Solicitud
| CONCLUSIÓN DE RESULTADOS | ||||||||
| Estadísticas de registro | ||||||||
| Plural R | 0,947541801 | |||||||
| R Plaza | 0,897835464 | |||||||
| R cuadrado normalizado | 0,829725774 | |||||||
| Error estándar | 0,226013867 | |||||||
| Observaciones | 6 | |||||||
| Análisis de variación | ||||||||
| Significado F | ||||||||
| Regresión | 2 | 1,346753196 | 0,673376598 | 13,18219855 | 0,032655042 | |||
| Resto | 3 | 0,153246804 | 0,051082268 | |||||
| Total | 5 | 1,5 | ||||||
| Impares | Error estándar | estadística t | valor p | 95% inferior | 95% superior | 95% inferior | 95% superior |
|
| Intersección en Y | 4,736816539 | 0,651468195 | 7,27098664 | 0,005368842 | 2,66355399 | 6,810079088 | 2,66355399 | 6,810079088 |
| Variable X1 | 0,333424008 | 0,220082134 | 1,51499807 | 0,227014505 | -0,366975566 | 1,033823582 | -0,366975566 | |








