Problemas de segmentación de imágenes utilizando la red neuronal Unet. Segmentación de imágenes semánticas "suaves"
Una de las principales tareas del procesamiento y análisis de imágenes es la segmentación, es decir. dividir una imagen en áreas para las cuales se cumple un cierto criterio de homogeneidad, por ejemplo, resaltar áreas de aproximadamente el mismo brillo en la imagen. El concepto de área de imagen se utiliza para definir un grupo coherente de elementos de imagen que tienen una determinada característica (propiedad) común.Una de las formas principales y más sencillas es crear una segmentación utilizando un umbral. Un umbral es un signo (propiedad) que ayuda a dividir la señal deseada en clases. La operación de división de umbral es comparar el valor de brillo de cada píxel de la imagen con un valor de umbral específico.
Binarización
La operación de umbralización que da como resultado una imagen binaria se llama binarización. El objetivo de la operación de binarización es reducir radicalmente la cantidad de información contenida en la imagen. En el proceso de binarización, la imagen de semitonos original, que tiene un cierto número de niveles de brillo, se convierte en una imagen en blanco y negro, cuyos píxeles tienen solo dos valores: 0 y 1.
El umbral de una imagen se puede realizar de diferentes maneras.
Binarización con umbral más bajo
Binarización con umbral más bajoLa binarización con un umbral más bajo es la operación más simple, que utiliza solo un valor de umbral:

Todos los valores en lugar del criterio pasan a ser 1, en este caso 255 (blanco) y todos los valores (amplitudes) de píxeles que son mayores que el umbral t - 0 (negro).
Binarización con umbral superior
En ocasiones se puede utilizar una variante del primer método, que produce un negativo de la imagen obtenida mediante el proceso de binarización. Operación de binarización con umbral superior: 
Binarización con doble restricción.
Para resaltar áreas en las que los valores de brillo de los píxeles pueden variar dentro de un rango conocido, se introduce la binarización con doble limitación (t 1 
También son posibles otras variaciones con umbrales, en las que sólo se pasa una parte de los datos (filtro de banda media).
Umbral incompleto
Esta transformación produce una imagen que puede ser más fácil de analizar en mayor profundidad porque pierde el fondo con todos los detalles presentes en la imagen original. 
Transformación de umbral multinivel
Esta operación forma una imagen que no es binaria, sino que consta de segmentos con diferentes brillos. 
En cuanto a la binarización, eso es esencialmente todo. Aunque podemos agregar que hay uno global, que se usa para toda la imagen, y también hay uno local, que captura parte de la imagen (imagen).
Umbral local
método otsaEl método utiliza un histograma de la distribución de los valores de brillo de los píxeles de una imagen rasterizada. Un histograma se construye usando los valores p i =n i /N, donde N es el número total de píxeles de la imagen, n i es el número de píxeles con el nivel de brillo i. El rango de brillo se divide en dos clases utilizando el umbral de nivel de brillo k,k, un valor entero de 0 a L. Cada clase corresponde a frecuencias relativas ω 0 ω 1:

Niveles promedio para cada una de las dos clases de imágenes:
A continuación, se calcula el valor máximo para evaluar la calidad de dividir la imagen en dos partes:
donde (σ cl)2=ω 0 ω 1 (μ 1 -μ 0) 2 es la varianza entre clases y (σ total) 2 es la varianza total de toda la imagen.

Umbral basado en el gradiente de brillo de la imagen
Supongamos que la imagen analizada se puede dividir en dos clases: objetos y fondo. El algoritmo para calcular el valor umbral consta de los siguientes 2 pasos:
1. El módulo del gradiente de brillo se determina para cada píxel.
imágenes
2. Cálculo del umbral:

Total
Con mucho gusto compartí con ustedes lo que encontré. En el futuro, si tengo éxito y tengo tiempo, intentaré implementar algunos de los algoritmos. Esto es sólo una pequeña parte de todo lo que existe hoy en día, pero estoy feliz de poder compartirlo también.Gracias por su atención. 1
Se consideran métodos matemáticos para segmentar imágenes del estándar Dicom. Se están desarrollando métodos matemáticos para la segmentación de imágenes del estándar Dicom para problemas de reconocimiento de imágenes médicas. El diagnóstico de enfermedades depende de las calificaciones del investigador y requiere que realice una segmentación visual, y los métodos matemáticos para procesar imágenes rasterizadas son una herramienta para este diagnóstico. El procesamiento de imágenes médicas obtenidas mediante hardware sin preprocesar los datos gráficos en la mayoría de los casos produce resultados incorrectos. Se realizaron procedimientos para extraer contornos de objetos utilizando el método Canny y algoritmos adicionales de procesamiento de imágenes rasterizadas. Los resultados de la investigación permiten calcular las propiedades morfométricas, geométricas y de histograma de las formaciones del cuerpo humano necesarias para el tratamiento posterior del paciente y para proporcionar un tratamiento médico eficaz. Los principios desarrollados del análisis automatizado por computadora de imágenes médicas se utilizan eficazmente para tareas operativas de diagnóstico médico en una institución oncológica especializada y con fines educativos.
reconocimiento de patrones
segmentación de objetos de interés
Imágenes medicas
1. Vlasov A.V., Tsapko I.V. Modificación del algoritmo Canny aplicado al procesamiento de imágenes radiográficas // Boletín de Ciencias de Siberia. – 2013. – N° 4(10). – págs. 120–127.
2. Gonzales R., Woods R. Procesamiento de imágenes digitales. – M.: Tekhnosfera, 2006. – P. 1072.
3. Kulyabichev Yu.P., Pivtoratskaya S.V. Enfoque estructural para la selección de características en sistemas de reconocimiento de patrones // Ciencias naturales y técnicas. – 2011. – Núm. 4. – P. 420–423.
4. Nikitin O.R., Pasechnik A.S. Contorneado y segmentación en tareas de diagnóstico automatizado de patologías // Métodos y dispositivos de transmisión y procesamiento de información. – 2009. – Núm. 11. – P. 300–309.
5. Canny J. Un enfoque computacional para la detección de bordes // Transacciones IEEE sobre análisis de patrones e inteligencia artificial. – 1986. – Núm. 6. – P.679–698.
6. DICOM – Modo de acceso: http://iachel.ru/ zob23tai-staihroe/ DICOM
7. Doronicheva A.V., Sokolov A.A., Savin S.Z. Uso del operador Sobel para la detección automática de bordes en imágenes médicas // Journal of Mathematics and System Science. – 2014. – Vol. 4, núm. 4 – págs. 257–260.
8. Jähne B., Scharr H., Körkel S. Principios de diseño de filtros // Manual de aplicaciones y visión por computadora. Prensa académica. – 1999. – 584 p.
Una de las áreas prioritarias para el desarrollo de la medicina en Rusia es la transición a tecnologías propias e innovadoras para el registro, almacenamiento, procesamiento y análisis electrónico de imágenes médicas de órganos y tejidos de pacientes. Esto se debe a un aumento en la cantidad de información presentada en forma de imágenes en el diagnóstico de enfermedades socialmente significativas, principalmente enfermedades oncológicas, cuyo tratamiento en la mayoría de los casos da resultados solo en las primeras etapas.
Al realizar el diagnóstico por imagen del estándar DICOM se determina un área patológica, y cuando se confirma su naturaleza patológica se resuelve el problema de clasificación: asignación a una de las especies conocidas o identificación de una nueva clase. Una dificultad obvia son los defectos en la imagen resultante, que son causados tanto por las limitaciones físicas del equipo como por los límites permitidos de carga en el cuerpo humano. Como resultado, son las herramientas de software las que se encargan del procesamiento adicional de imágenes para aumentar su valor diagnóstico para el médico, presentarlas de una forma más conveniente y resaltar lo principal entre los grandes volúmenes de datos recibidos.
Propósito del estudio. Se están desarrollando métodos matemáticos para la segmentación de imágenes del estándar Dicom para problemas de reconocimiento de imágenes médicas. El diagnóstico de enfermedades depende de las calificaciones del investigador y requiere que realice una segmentación visual, y los métodos matemáticos para procesar imágenes rasterizadas son una herramienta para este diagnóstico. El procesamiento de imágenes médicas obtenidas mediante hardware sin preprocesar los datos gráficos en la mayoría de los casos produce resultados incorrectos. Esto se debe a que las imágenes recibidas inicialmente no tenían una calidad satisfactoria.
Material y métodos de investigación.
Como material de investigación se utilizan tomografías computarizadas de pacientes en una institución clínica especializada. Antes de analizar datos gráficos reales, es necesario preparar o preprocesar la imagen. Esta etapa resuelve el problema de mejorar la calidad visual de las imágenes médicas. Es útil dividir todo el proceso de procesamiento de imágenes en dos categorías amplias: métodos en los que tanto la entrada como la salida son imágenes; métodos donde los datos de entrada son imágenes y, como resultado del trabajo, los datos de salida son signos y atributos identificados en base a los datos de entrada. Este algoritmo no supone que cada uno de los procesos anteriores se aplique a la imagen. El registro de datos es el primero de los procesos, como se muestra en la Fig. 1.
Arroz. 1. Principales etapas del procesamiento digital de datos gráficos.
El registro puede ser bastante sencillo, como en el ejemplo donde la imagen original es digital. Normalmente, la etapa de registro de imágenes implica el preprocesamiento de los datos, por ejemplo, el aumento de escala de la imagen. La mejora de imágenes es una de las áreas del preprocesamiento más simples e impresionantes. Como regla general, los métodos para mejorar el contenido informativo de las imágenes están determinados por la tarea de encontrar píxeles poco distinguibles o aumentar el contraste en la imagen original. Uno de los métodos comúnmente utilizados para mejorar el contenido de información de las imágenes es mejorar el contraste de la imagen, a medida que se realzan los límites del objeto de interés. Hay que tener en cuenta que mejorar la calidad de la imagen es, en cierta medida, una tarea subjetiva en el procesamiento de imágenes. La restauración de imágenes es una tarea también relacionada con la mejora de la calidad visual de los datos. Los métodos de restauración de imágenes se basan en modelos matemáticos y probabilísticos de deformación de datos gráficos. El procesamiento de imágenes como etapa debe separarse del concepto de procesamiento de imágenes como el proceso completo de cambiar la imagen y obtener algunos datos. La segmentación, o el proceso de extraer objetos de interés, divide una imagen en objetos o partes componentes. La extracción automatizada de objetos de interés es una tarea algo desafiante en el procesamiento de imágenes digitales. Una segmentación demasiado detallada dificulta el procesamiento de imágenes cuando se trata de resaltar objetos de interés. Pero una segmentación incorrecta o insuficientemente detallada en la mayoría de las tareas conduce a errores en la etapa final del procesamiento de imágenes. La presentación y descripción de datos gráficos generalmente sigue a la etapa de resaltar objetos de interés en la imagen, cuya salida en la mayoría de los casos contiene píxeles sin procesar que forman los límites de la región o forman todos los píxeles de las regiones. Con tales opciones, es necesario convertir los datos a un formato accesible para el análisis por computadora. El reconocimiento de patrones es un proceso que asigna un identificador a un objeto (como "radio") en función de sus descripciones. Determinemos la relación entre la base de conocimientos y los módulos de procesamiento de imágenes. La base de conocimientos (es decir, la información sobre el área del problema) está de alguna manera cifrada dentro del propio sistema de procesamiento de imágenes. Este conocimiento puede ser bastante simple, como una indicación detallada de los objetos en la imagen donde debería estar el área de interés. Este conocimiento permite limitar el área de búsqueda. La base de conocimiento controla el funcionamiento de cada módulo de procesamiento y su interacción, como se muestra en la Fig. 1 con flechas dirigidas en dos direcciones entre los módulos y la base de conocimientos. Guardar e imprimir resultados a menudo también requiere el uso de técnicas especiales de procesamiento de imágenes. La desventaja de estos pasos de procesamiento de imágenes en un sistema de procesamiento de imágenes médicas es que los errores creados en las primeras etapas del procesamiento, por ejemplo al ingresar o resaltar objetos de interés en la imagen, pueden conducir al fracaso de una clasificación correcta. El procesamiento de datos se realiza de manera estrictamente secuencial y, en la mayoría de los casos, no existe la posibilidad de volver a etapas anteriores del procesamiento, incluso si previamente se obtuvieron resultados incorrectos. Los métodos en la etapa de preprocesamiento son bastante variados: identificar objetos de interés, escalarlos, corregir el color, ajustar la resolución espacial, cambiar el contraste, etc. Una de las acciones prioritarias en la etapa de preprocesamiento de la imagen es ajustar el contraste y el brillo. Utilizando máscaras adecuadas, es posible combinar dos etapas (filtrado y preprocesamiento) para aumentar la velocidad del análisis de datos. El resultado final del análisis de imágenes en la mayoría de los casos está determinado por el nivel de calidad de la segmentación, y el grado de detalle de los objetos de interés depende de la tarea específica en cuestión. Por este motivo, no se ha desarrollado un método o algoritmo independiente que sea adecuado para resolver todos los problemas de identificación de objetos de interés. Delinear áreas tiene como objetivo resaltar objetos con propiedades específicas en las imágenes. Estos objetos, por regla general, corresponden a objetos o sus partes que los diagnosticadores etiquetan. El resultado del contorno es una imagen binaria o jerárquica (multifase), donde cada nivel de la imagen corresponde a una determinada clase de objetos seleccionados. La segmentación es un paso complejo en el procesamiento y análisis de datos médicos de tejidos biológicos, ya que es necesario delimitar áreas que corresponden a diferentes objetos o estructuras a niveles histológicos: células, orgánulos, artefactos, etc. Esto se explica por la alta variabilidad de sus parámetros, el bajo nivel de contraste de las imágenes analizadas y la compleja relación geométrica de los objetos. En la mayoría de los casos, para obtener el resultado más eficaz, es necesario utilizar constantemente diferentes métodos para segmentar los objetos de interés en la imagen. Por ejemplo, para determinar los límites de un objeto de interés, se utiliza el método del gradiente morfológico, después del cual se lleva a cabo la segmentación del umbral en áreas que son adecuadas para diferencias menores en las características de brillo. Para procesar imágenes en las que áreas homogéneas no relacionadas difieren en brillo promedio, se eligió el método de segmentación Canny; se llevó a cabo una investigación sobre un ejemplo clínico. Al reconocer imágenes clínicas reales, el modelado es poco aplicable. La experiencia práctica y las opiniones de expertos sobre los resultados del análisis de imágenes son de gran importancia. Para la imagen de prueba se seleccionó una imagen de tomografía computarizada, donde el objeto de interés mostrado en la Fig. 1 está claramente presente. 2.

Arroz. 2. Imagen de tomografía computarizada con el objeto de interés.
Para implementar la segmentación, utilizamos el método Canny. Este enfoque es resistente al ruido y en la mayoría de los casos muestra mejores resultados en comparación con otros métodos. El Método Canny consta de cuatro pasos:
1) preprocesamiento: difuminar la imagen (reducimos la dispersión del ruido aditivo);
2) diferenciación de la imagen borrosa y posterior cálculo de los valores de gradiente en las direcciones xey;
3) implementación de supresión no máxima en la imagen;
4) procesamiento de imágenes de umbral.
En la primera etapa del algoritmo Canny, la imagen se suaviza utilizando una máscara con un filtro gaussiano. La ecuación de distribución gaussiana en N dimensiones tiene la forma
o en el caso especial de dos dimensiones
![]() (2)
(2)
donde r es el radio de desenfoque, r 2 = u 2 + v 2 ; σ es la desviación estándar de la distribución gaussiana.
Si utilizamos 2 dimensiones, entonces esta fórmula especifica la superficie de círculos concéntricos que tienen una distribución gaussiana desde el punto central. Los píxeles con una distribución distinta de cero se utilizan para especificar la matriz de convolución aplicada a la imagen original. El valor de cada píxel se convierte en un promedio ponderado de la vecindad. El valor del píxel inicial toma el peso máximo (tiene el valor gaussiano máximo) y los píxeles vecinos toman el peso mínimo, dependiendo de su distancia. En teoría, la distribución en cada punto de la imagen debe ser distinta de cero, lo que sigue el cálculo de los pesos de cada píxel de la imagen. Pero en la práctica, al calcular una aproximación discreta de la función gaussiana, los píxeles a una distancia > 3σ no se tienen en cuenta, ya que es bastante pequeña. Por tanto, el programa de procesamiento de imágenes necesita calcular la matriz × para garantizar que la aproximación de la distribución gaussiana sea suficientemente precisa.
Resultados de la investigación y discusión.
El resultado del filtro gaussiano con datos iguales a 5 para el tamaño de la máscara gaussiana y 1,9 para el valor del parámetro σ, la desviación estándar de la distribución gaussiana, se presenta en la Fig. 3. El siguiente paso es buscar el gradiente de la región de interés convolucionando la imagen suavizada con la derivada de la función gaussiana en las direcciones vertical y horizontal del vector.
Usemos el operador de Sobel para resolver este problema. El proceso se basa en simplemente mover la máscara del filtro de un píxel a otro de la imagen. En cada píxel (x, y), la respuesta del filtro se calcula a partir de conexiones predefinidas. Esto da como resultado la selección inicial de bordes. El siguiente paso es comparar cada píxel con sus vecinos a lo largo de la dirección del gradiente y calcular el máximo local. La información sobre la dirección del gradiente es necesaria para eliminar píxeles cerca del límite sin romper el límite cerca de los máximos locales del gradiente, lo que significa que los píxeles del límite determinan los puntos en los que se alcanza el máximo local del gradiente en la dirección del vector gradiente. Este enfoque puede reducir significativamente la detección de bordes falsos y proporciona un grosor de un píxel del borde del objeto, lo que se confirma empíricamente mediante la implementación de software del algoritmo para segmentar un corte de la cavidad abdominal en una imagen de tomografía computarizada, que se presenta a continuación en Higo. 4.
El siguiente paso es utilizar un umbral para determinar dónde está el límite en cada píxel determinado de la imagen. Cuanto más bajo sea el umbral, más bordes habrá en el objeto de interés, pero más susceptible será el resultado al ruido y a delinear datos de imagen extraños. Un umbral alto puede ignorar los bordes débiles de un área o quedar bordeado por varias áreas. El contorno de límites aplica dos umbrales de filtrado: si el valor del píxel está por encima del límite superior, toma el valor máximo (el límite se considera confiable), si está por debajo de él, el píxel se suprime, los puntos con un valor que se encuentran dentro del rango entre los umbrales tomar un valor promedio fijo. Un píxel se une a un grupo si lo toca en una de ocho direcciones. Entre las ventajas del método Canny está que durante el procesamiento de imágenes se adapta a las características de la segmentación. Esto se logra introduciendo un umbral de dos niveles para eliminar datos redundantes. Se definen dos niveles de umbral, el superior - p alto y el inferior - p bajo, donde p alto > p bajo. Los valores de píxeles por encima del valor alto de p se designan como correspondientes al límite (Fig. 5).

Arroz. 3. Aplicar un filtro gaussiano en una tomografía computarizada con un objeto de interés

Arroz. 4. Supresión de no máximos en la imagen segmentada.

Arroz. 5. Aplicación del algoritmo de segmentación Canny con diferentes niveles de umbral
La práctica muestra que hay un cierto intervalo en la escala de niveles de umbral de sensibilidad, en el cual el valor del área del objeto de interés prácticamente no cambia, pero al mismo tiempo hay un cierto nivel de umbral, después del cual " Se nota el fracaso” del método de delineación y el resultado de la identificación de áreas de interés se vuelve incierto. Esta es una deficiencia del algoritmo que puede compensarse combinando el algoritmo Canny con la transformada de Hough para encontrar círculos. La combinación de algoritmos le permite identificar claramente los objetos de estudio, así como eliminar espacios en los contornos.
Conclusiones
De esta forma se resuelve el problema de formular características típicas de objetos patológicos en imágenes médicas, lo que permitirá en el futuro realizar análisis operativos de datos sobre patologías específicas. Los parámetros importantes para determinar la evaluación de la calidad de la segmentación son las probabilidades de falsas alarmas y fallos. Estos parámetros determinan la aplicación de la automatización del método de análisis. La segmentación es una de las más importantes a la hora de resolver el problema de clasificación y reconocimiento de objetos en imágenes. Los métodos de contorneado basados en la segmentación de los límites de áreas (Sobel, Canny, Prewit, Laplassiano) han sido bastante bien investigados y aplicados. Este enfoque está determinado por el hecho de que la concentración de la atención de una persona al analizar imágenes a menudo se centra en los límites entre zonas que tienen un brillo más o menos uniforme. En base a esto, los contornos a menudo sirven como base para definir diversas características para interpretar imágenes y objetos en ellos. La tarea principal de los algoritmos para segmentar áreas de interés es la construcción de una imagen binaria que contenga áreas estructurales cerradas de datos en la imagen. En cuanto a las imágenes médicas, estas áreas son los límites de órganos, venas, MCC y tumores. Los principios desarrollados del análisis automatizado por computadora de imágenes médicas se utilizan eficazmente tanto para tareas operativas de diagnóstico médico de una institución oncológica especializada como para fines educativos.
Investigado con el apoyo del programa Lejano Oriente, subvención No. 15-I-4-014o.
Revisores:
Kosykh N.E., Doctor en Ciencias Médicas, Profesor, Investigador Jefe, Centro de Computación, Rama del Lejano Oriente de la Academia de Ciencias de Rusia, Khabarovsk;
Levkova E.A., Doctora en Ciencias Médicas, Profesora, Universidad Estatal de Transporte del Lejano Oriente, Khabarovsk.
Enlace bibliográfico
Doronicheva A.V., Savin S.Z. MÉTODO DE SEGMENTACIÓN DE IMÁGENES MÉDICAS // Investigación Fundamental. – 2015. – N° 5-2. – págs. 294-298;URL: http://fundamental-research.ru/ru/article/view?id=38210 (fecha de acceso: 06/04/2019). Llamamos su atención sobre las revistas publicadas por la editorial "Academia de Ciencias Naturales".
El artículo describe el estudio de los métodos de segmentación de imágenes utilizando varios ejemplos. El propósito del estudio es descubrir las ventajas y desventajas de algunos métodos conocidos.
Métodos que se discutirán en este artículo:
- Método de cultivo regional;
- método de cuenca;
- Método de cortes normales.
Estudio de métodos de segmentación en imágenes modelo.
Inicialmente, la investigación sobre métodos de segmentación se llevó a cabo en modelos de imágenes. Se utilizaron como modelos nueve tipos de imágenes.
Los resultados del estudio mostraron:
- El método de crecimiento de regiones localiza defectos de textura, tanto aquellos que difieren marcadamente del fondo como aquellos que se forman al rotar y cambiar el brillo de la textura;
- El método de crecimiento de regiones localiza defectos en diversos grados en diferentes ángulos de rotación de la textura;
- El método de segmentación de cuencas considerado en su forma original no proporciona localización de defectos de textura;
- El método de corte normal es bueno para localizar la presencia de una textura diferente del fondo, pero no resalta los cambios en el brillo y la rotación de la textura.
Estudio de métodos de segmentación de imágenes de objetos.
Para estudiar los métodos de segmentación se preparó una base de datos de imágenes de diversos objetos. Las imágenes resultantes se segmentaron utilizando varios métodos, cuyos resultados se presentan en las figuras de la tabla.
| imagen original | Método de crecimiento de la región | Método de cortes normales | Método de cuenca |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Resultados:
- El método de crecimiento de regiones no proporciona localización de segmentos en imágenes de objetos;
- Los métodos considerados de cuencas hidrográficas y secciones normales en su forma original no proporcionan localización de los objetos presentados;
- El método de corte normal proporciona localización de objetos en imágenes de objetos.
Resultados
Resultados del estudio:
- El método de crecimiento de regiones no proporciona localización de segmentos tanto en imágenes de modelos como en imágenes de objetos, y también proporciona localización de elementos de la infraestructura de transporte por carretera.
- Los métodos considerados de cuencas hidrográficas y secciones normales en su forma original no garantizan completamente la localización de los objetos presentados.
- El método de corte normal proporciona localización de objetos tanto en imágenes de modelos como en imágenes de objetos, y también proporciona localización de elementos de la infraestructura de transporte por carretera.
- El método de crecimiento de regiones y el método de sección normal se pueden recomendar para su uso en sistemas de inspección visual automatizados.
La segmentación significa identificar áreas que son homogéneas según algún criterio, por ejemplo, la luminosidad. La formulación matemática del problema de segmentación puede ser la siguiente.
Sea la función de brillo de la imagen analizada; incógnita– un subconjunto finito del plano en el que 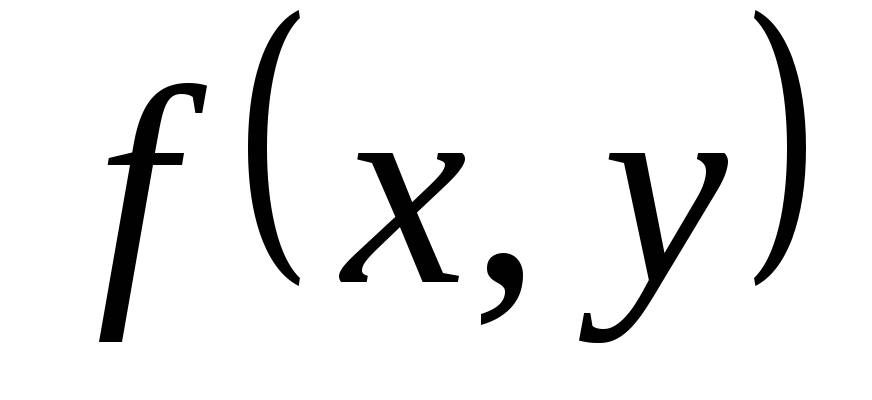 ;
; - partición incógnita en k subconjuntos conectados no vacíos
- partición incógnita en k subconjuntos conectados no vacíos  LP– un predicado definido en un conjunto S y tomando valores verdaderos si y sólo si cualquier par de puntos de cada subconjunto
LP– un predicado definido en un conjunto S y tomando valores verdaderos si y sólo si cualquier par de puntos de cada subconjunto  satisface el criterio de homogeneidad.
satisface el criterio de homogeneidad.
Segmentación de imágenes  por predicado LP llamada partición
por predicado LP llamada partición 
 , cumpliendo las condiciones:
, cumpliendo las condiciones:
A) 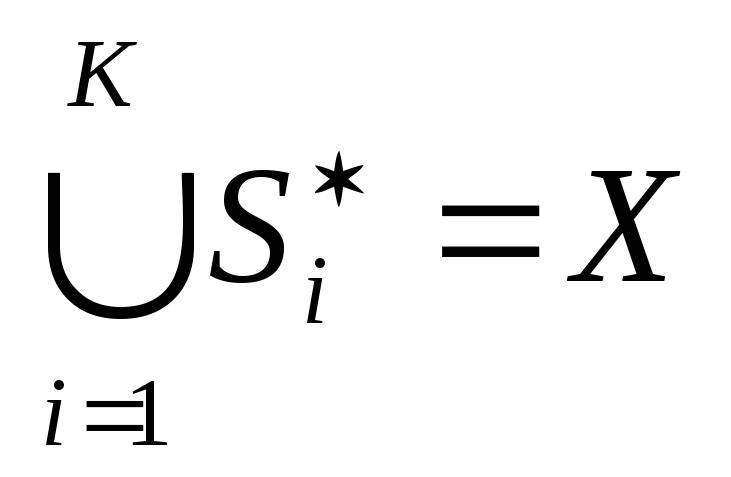 ;
;
b)  ;
;
V) 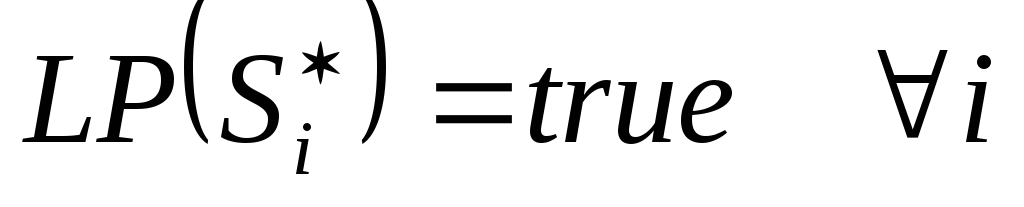 ;
;
d) áreas relacionadas.
Las condiciones a) y b) significan que cada punto de la imagen debe asignarse de forma única a un área determinada, c) determina el tipo de homogeneidad de las áreas resultantes y, finalmente, d) expresa la propiedad de “maximidad” de la partición. áreas.
Predicado LP se llama predicado de homogeneidad y se puede escribir como:
 (1)
(1)
Dónde  -relación de equivalencia;
-relación de equivalencia;  - puntos arbitrarios de
- puntos arbitrarios de  Por tanto, la segmentación puede considerarse como un operador de la forma:
Por tanto, la segmentación puede considerarse como un operador de la forma:
Dónde  -funciones que definen las imágenes originales y segmentadas, respectivamente;
-funciones que definen las imágenes originales y segmentadas, respectivamente; 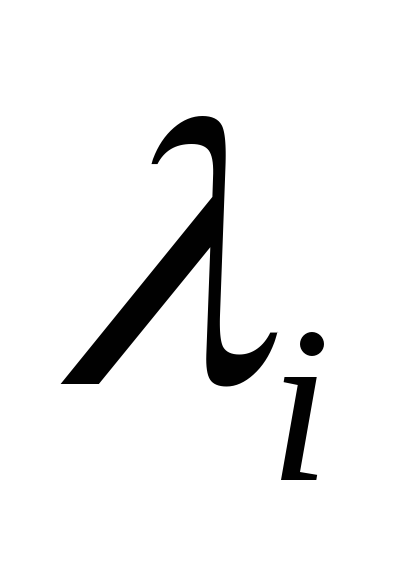 -etiqueta i-ª región.
-etiqueta i-ª región.
Hay dos enfoques generales para resolver el problema de la segmentación, que se basan en conceptos metodológicos alternativos. El primer enfoque se basa en la idea de "discontinuidad" en las propiedades de los puntos de la imagen cuando se mueven de un área a otra. Este enfoque reduce el problema de la segmentación al problema de identificar los límites de las regiones. Una solución exitosa de esto último permite, en términos generales, identificar tanto las regiones mismas como sus límites. El segundo enfoque realiza el deseo de seleccionar puntos de imagen que sean homogéneos en sus propiedades locales y combinarlos en un área, a la que luego se le asignará un nombre o etiqueta semántica. En la literatura, el primer enfoque se llama segmentación resaltando los límites de las áreas, y el segundo – segmentación marcando puntos de área. La definición matemática anterior del problema nos permite caracterizar estos enfoques en términos del predicado de homogeneidad. LP. En el primer caso, como LP debe haber un predicado que tome valores verdaderos en los puntos límite de las regiones y valores falsos en los puntos internos. Sin embargo, se puede observar una limitación importante de este enfoque, que es que la partición  Aquí hay un conjunto de dos elementos. En términos prácticos, esto significa que los algoritmos de detección de bordes no permiten identificar diferentes áreas con diferentes etiquetas.
Aquí hay un conjunto de dos elementos. En términos prácticos, esto significa que los algoritmos de detección de bordes no permiten identificar diferentes áreas con diferentes etiquetas.
Para el segundo enfoque el predicado LP puede tener la forma determinada por la relación (5.1). Los enfoques anteriores dan lugar a métodos y algoritmos específicos para resolver el problema de segmentación.
Método de segmentación basado en umbrales
Umbralizar una imagen significa transformar su función de brillo mediante un operador de la forma

Dónde s(x,y)– imagen segmentada; k –
número de áreas de segmentación;  - etiquetas de áreas segmentadas;
- etiquetas de áreas segmentadas;  - valores umbral, ordenados de modo que
- valores umbral, ordenados de modo que 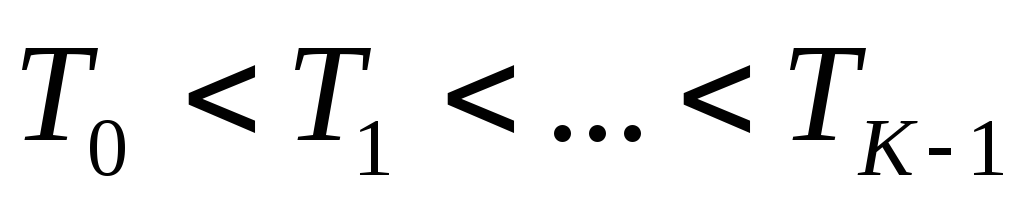 .
.
En el caso especial cuando k= 2 umbralización implica el uso de un único umbral t. Al asignar umbrales, como regla general, se utiliza un histograma de los valores de la función de brillo de la imagen.
Algoritmo de segmentación basado en umbrales en pseudocódigo
Entrada: mtrIntens – la matriz original de la imagen de medios tonos;
l, r – umbrales según el histograma
Salida: mtrIntensNew – matriz de imágenes segmentadas
para yo:=0 a l-1 hacer
para yo:=l a r hacer
para yo:=r+1 a 255 hacer
LUT[i]=255;
para yo:=1 a 100 hacer
para j:=1 a 210 hacer
mtrIntensNuevo:=LUT]
Una de las principales tareas del procesamiento y análisis de imágenes es la segmentación, es decir. dividir una imagen en áreas para las cuales se cumple un cierto criterio de homogeneidad, por ejemplo, resaltar áreas de aproximadamente el mismo brillo en la imagen. El concepto de área de imagen se utiliza para definir un grupo coherente de elementos de imagen que tienen un determinado atributo (propiedad) común.Una de las formas principales y más sencillas es crear una segmentación utilizando un umbral. Un umbral es un signo (propiedad) que ayuda a dividir la señal deseada en clases. La operación de división de umbral es comparar el valor de brillo de cada píxel de la imagen con un valor de umbral específico.
Binarización
La operación de umbralización que da como resultado una imagen binaria se llama binarización. El objetivo de la operación de binarización es reducir radicalmente la cantidad de información contenida en la imagen. En el proceso de binarización, la imagen de semitonos original, que tiene un cierto número de niveles de brillo, se convierte en una imagen en blanco y negro, cuyos píxeles tienen solo dos valores: 0 y 1.
El umbral de una imagen se puede realizar de diferentes maneras.
Binarización con umbral más bajo
Binarización con umbral más bajoLa binarización con un umbral más bajo es la operación más simple, que utiliza solo un valor de umbral:
Todos los valores en lugar del criterio pasan a ser 1, en este caso 255 (blanco) y todos los valores (amplitudes) de píxeles que son mayores que el umbral t - 0 (negro).
Binarización con umbral superior
En ocasiones se puede utilizar una variante del primer método, que produce un negativo de la imagen obtenida mediante el proceso de binarización. Operación de binarización con umbral superior:
Binarización con doble restricción.
Para resaltar áreas en las que los valores de brillo de los píxeles pueden variar dentro de un rango conocido, se introduce la binarización con doble limitación (t 1
También son posibles otras variaciones con umbrales, en las que sólo se pasa una parte de los datos (filtro de banda media).
Umbral incompleto
Esta transformación produce una imagen que puede ser más fácil de analizar en mayor profundidad porque pierde el fondo con todos los detalles presentes en la imagen original.
Transformación de umbral multinivel
Esta operación forma una imagen que no es binaria, sino que consta de segmentos con diferentes brillos.
En cuanto a la binarización, eso es esencialmente todo. Aunque podemos agregar que hay uno global, que se usa para toda la imagen, y también hay uno local, que captura parte de la imagen (imagen).
Umbral local
método otsaEl método utiliza un histograma de la distribución de los valores de brillo de los píxeles de una imagen rasterizada. Un histograma se construye usando los valores p i =n i /N, donde N es el número total de píxeles de la imagen, n i es el número de píxeles con el nivel de brillo i. El rango de brillo se divide en dos clases utilizando el umbral de nivel de brillo k,k, un valor entero de 0 a L. Cada clase corresponde a frecuencias relativas ω 0 ω 1:
Niveles promedio para cada una de las dos clases de imágenes:
A continuación, se calcula el valor máximo para evaluar la calidad de dividir la imagen en dos partes:
donde (σ cl)2=ω 0 ω 1 (μ 1 -μ 0) 2 es la varianza entre clases y (σ total) 2 es la varianza total de toda la imagen.
Umbral basado en el gradiente de brillo de la imagen
Supongamos que la imagen analizada se puede dividir en dos clases: objetos y fondo. El algoritmo para calcular el valor umbral consta de los siguientes 2 pasos:
1. El módulo del gradiente de brillo se determina para cada píxel.
imágenes
2. Cálculo del umbral:
Total
Con mucho gusto compartí con ustedes lo que encontré. En el futuro, si tengo éxito y tengo tiempo, intentaré implementar algunos de los algoritmos. Esto es sólo una pequeña parte de todo lo que existe hoy en día, pero estoy feliz de poder compartirlo también.Gracias por su atención.



