Správné sémantické jádro. Jak odhadnout hodnoty KEI. Odstranění nepotřebných „klíčů“
Jak vytvořit sémantické jádro webu
Dobrý den, milí čtenáři blogu. Tento článek byl napsán jako součást maratonu. Dovolte mi připomenout, že se učíme vytvářet webové stránky pro YAN a vydělávat na nich peníze. Přidat se k nám můžete kdykoliv – všechny podrobnosti najdete v článcích s označením „maraton“. Hledejte na blogu.
Jak vytvořit sémantické jádro webu? Pojďme na to přijít
Jako obvykle, než přejdeme přímo k praxi, rád bych vyjádřil několik teoretických myšlenek a popsal svou problematiku.
Kompilace sémantického jádra webu není tak náročná, jak si možná myslíte. Je to jen rutinní, „únavná“ práce. Ale není to nic složitého, přísně tajné.
Pro úspěšnou práci musíte. Dovolte mi připomenout, že tam jsme sestavili podsekce našeho budoucího webu a udělali jsme to co nejpodrobněji.
Čím podrobněji a lépe bude předchozí lekce dokončena, tím snáze se s tím vyrovnáte. Pokud se tam dělají 2-3 sekce, určitě tomu materiálu věnujte čas. Nyní pochopíte, proč je to důležité.
Jaké programy jsou potřeba ke kompilaci jádra?
Používám pouze dva programy/služby:
- Sběratel klíčů;
- Služba rooke.ru
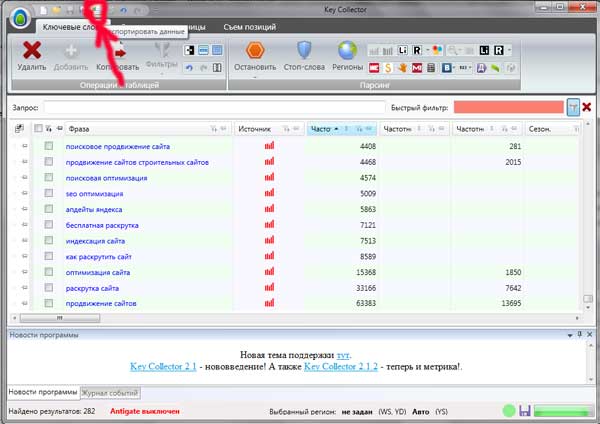
S pomocí Key Collector analyzujeme potřebná klíčová slova a tvoříme skupiny těchto slov pro psaní článků.
S naší ruční službou analyzujeme konkurenty.
Tyto nástroje mi naprosto stačí. Podotýkám, že placený sběrač klíčů lze nahradit programem Slovoeb. Vyberte si sami, co použít.
Sběratel klíčů: práce se sémantickým jádrem
Upřímně řečeno, nedokážu si představit, jak jsem bez tohoto programu dříve fungoval. Ve skutečnosti za vás udělá veškerou rutinní práci, stačí stisknout několik tlačítek, zahodit odpadky a zkopírovat zprávu s dobrými klíčovými slovy pod článek. Pojďme na to přijít.
Jsem zvyklý vše ukazovat na příkladech. Tím je to mnohem jasnější. Zejména pokud jde o práci s programy/službami.
V předchozí lekci jsme se jako příklad podívali na téma „kanalizace“. Teď se od toho příliš nevzdálíme.
Potřebujeme například vybrat klíče pro psaní článků pro tuto část našeho jádra.

Je nutné vytvořit sémantické jádro sekce
Toto klíčové slovo analyzujeme ve sběrači klíčů (zajišťujeme shromažďování všech typů frekvencí).
Jasně vidíme skupiny žádostí, právě pro ně budeme v budoucnu psát články.

V tomto případě ano požadavek „kabel pro čištění odtoku“, dalším hlavním požadavkem skupiny bude „vyčištění kanalizačních blokád“ a tak dále odshora dolů.
Po dokončení analýzy je třeba zahodit „fiktivní klíče“: jedná se o klíčová slova, jejichž přesná frekvence je menší nebo rovna „!5“ (tento parametr závisí na návštěvnosti tématu a lze jej zvýšit nebo snížit). Odstraňujeme také klíčová slova, která se pro váš článek zjevně nehodí (jiná města, homonymní slova atd.).

Zahození fiktivních požadavků
Zbývající klíče seřadíme sestupně (nahoře máme nejčastější klíč skupiny).
Minutku :)
Určitě máte zájem o vydělávání peněz na internetu.
Nabízím nástroje, které sám používám již několik let:
Uložte projekt a exportujte klíče do souboru aplikace Excel. Na jejich základě v budoucnu napíšeme článek.

Export do Excelu
Popsal jsem podrobný proces sestavování sémantického jádra webu, opakuji, když se do toho pustíte, nasbíráte stovky dotazů, můžete parsovat jen více či méně časté klíče a na jejich základě si můžete ihned zapisovat témata pro články a potřebné klíče k nim. Ale zpočátku je lepší dělat vše, jak je popsáno: podrobně a krok za krokem.
Abychom však pochopili, jak článek napsat (jak dlouho, kolikrát opakovat klíč atd.), nestačí nám znát klíčové dotazy k němu, potřebujeme také analyzovat konkurenty.
Děláme to pomocí výše uvedené služby rooke.ru.
Analýza konkurentů pomocí služby rooke.ru
Než provedeme analýzu, musíme provést potřebná nastavení. Dovolte mi poznamenat, že systém vám umožňuje provádět analýzu konkurence zcela zdarma.

Začátek vytváření Republiky Kazachstán v rookee
V poli adresy webu označujeme jakýkoli web: může to být váš blog, může to být web vytvářený pro YAN – není v tom žádný rozdíl.
Poté musíte zvolit prioritní vyhledávač. V našem případě jsme si vybrali Yandex, protože právě pro tento vyhledávač vytváříme naše webové stránky a budeme také propagovat jeho používání.

Proces vytvoření Republiky Kazachstán
Vyberte téma webu.

Vyberte si, co potřebujete
Systém předpovídá rozpočet propagace a počítá počet návštěvníků.
Pojďme k naší reklamní společnosti. Přidáme požadovaný požadavek (analyzujeme konkurenty na základě stejného KS - „kabel pro čištění kanalizace“). Nezapomeňte zrušit zaškrtnutí políčka a začít propagovat přidané dotazy.

Přidejte požadovaný požadavek do systému
Požadavek je přidán do systému, pak musíme analyzovat konkurenty. Klikněte na odpovídající tlačítko.

Analýza konkurence
Vše, co musíme udělat, je shromáždit následující parametry (jiné nedoporučuji, protože ztratíte čas).

Jaká nastavení mám nastavit?
Když za vás systém udělá všechnu práci (prohlédne si vaši konkurenci, vše spočítá), vytiskne výsledný soubor.
Ti nejlínější (doufám, že takoví nejste) toho mohou využít.
Z tabulky bereme tyto údaje: průměrný počet znaků textu, celkový počet výskytů, přesné výskyty.

Systém provedl analýzu, kterou jsme potřebovali
Pro ty, kteří se nebojí strávit 30-60 sekund navíc (já ano): exportujte tabulku do Excelu, odfiltrujte dva výsledky s maximálním počtem znaků a dva s minimem.
Na základě šesti zbývajících výsledků analyzujeme stejné ukazatele: objem článku, počet výskytů. Získáváme tak objektivnější a reálnější data.

Export tabulky s konkurenty
Tím vlastně analýza konkurentů končí.
Máme všechna data pro vypracování technických specifikací pro psaní článku copywriterem (jeho objem, počet výskytů „hlavního klíče“, klávesy s nízkým klíčem stačí použít 1krát).
Jak správně poskládat sémantické jádro?
Popsal jsem své zkušenosti se sestavováním sémantického jádra. Myslím, že je to správné, protože to přináší výsledky: návštěvnost webu.
Abychom stručně popsali procesy, můžeme říci, že Správná kolekce sémantického jádra je následující:
- Analýza výsledků;
- Filtrujeme zbytečné, „prázdné“ požadavky;
- Na základě nejčastějšího klíče ze synonymní skupiny dotazů analyzujeme konkurenty;
- Shromažďujeme všechna data do jednoho souboru (toto je vaše jádro);
- Dostáváme prvotní data pro napsání článku.
Ano, nehádám se, může se vám zdát, že je to příliš obtížný úkol, „zabere“ vám to spoustu času, nebudete to zvládat...
Brzy se uvidíme.
UPD: pokud jste příliš líní, abyste to všechno udělali sami: ponořte se do nuancí, kupte si Key Collector, pak si můžete objednat sémantické jádro od Vadima Zakharova za rozumné ceny. Vadima znám mnoho let, celou tu dobu úspěšně spolupracujeme.
Sémantické jádro je poněkud otřepané téma, že? Dnes to společně napravíme sběrem sémantiky v této lekci!
nevěříš mi? - přesvědčte se sami - stačí zadat frázi sémantické jádro webu do Yandexu nebo Google. Myslím, že dnes tuto nepříjemnou chybu napravím.
Ale opravdu, jaké to pro vás je... ideální sémantika? Možná si myslíte, že je to hloupá otázka, ale ve skutečnosti to vůbec hloupé není, jen většina webmasterů a majitelů stránek pevně věří, že ví, jak skládat sémantická jádra, a že s tím vším si poradí každý školák, a sami se snaží učit ostatní... Ale ve skutečnosti je všechno mnohem složitější. Jednou se mě zeptali – co byste měli udělat jako první? — samotný web a obsah popř sedm jader, a zeptal se ho člověk, který se nepovažuje za nováčka v SEO. Tato otázka mi pomohla pochopit složitost a nejednoznačnost tohoto problému.
Sémantické jádro je základem základů – úplně prvním krokem, který stojí před spuštěním jakékoli reklamní kampaně na internetu. Spolu s tím je sémantika webu nejpracnějším procesem, který bude vyžadovat spoustu času, ale v každém případě se více než vyplatí.
No... Pojďme tvořit jeho spolu!
Krátká předmluva
K vytvoření sémantického pole pro web potřebujeme jeden jediný program - Sběratel klíčů. Na příkladu Sběratele rozeberu příklad sbírání malé rodinné skupiny. Kromě placeného programu existují také bezplatné analogy jako SlovoEb a další.
Sémantika se skládá z několika základních fází, z nichž je třeba zdůraznit následující:
- brainstorming - analýza základních frází a příprava parsování
- parsování - rozšíření základní sémantiky založené na Wordstatu a dalších zdrojích
- screening - screening po parsování
- analýza - analýza četnosti, sezónnosti, konkurence a dalších důležitých ukazatelů
- zjemnění - seskupení, oddělení komerčních a informačních frází jádra
Nejdůležitější fáze sběru budou diskutovány níže!
VIDEO - sestavení sémantického jádra pro soutěžící
Brainstorming při vytváření sémantického jádra – protahování našich mozků
V této fázi je to nutné udělat mentální výběr sémantické jádro webu a vymyslet co nejvíce frází, aby vyhovovaly našemu tématu. Spusťte tedy sběrač klíčů a vyberte Analýza Wordstat, jak je znázorněno na snímku obrazovky:

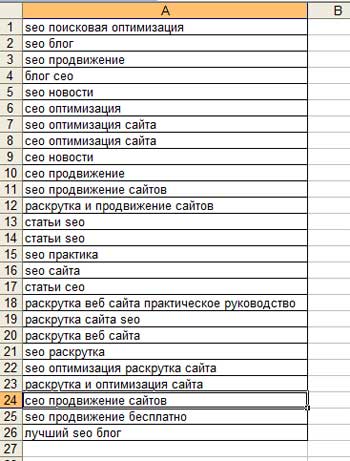
Otevře se před námi malé okénko, kam potřebujeme zadat co nejvíce frází k našemu tématu. Jak jsem již řekl, v tomto článku vytvoříme vzorovou sadu frází pro tento blog, takže fráze mohou být následující:
- SEO blog
- SEO blog
- blog o SEO
- blog o SEO
- povýšení
- povýšení projekt
- povýšení
- povýšení
- propagace blogu
- propagace blogu
- propagace blogu
- propagace blogu
- propagace s články
- propagace článku
- miralinky
- pracovat v sape
- nákup odkazů
- odkazy na nákup
- optimalizace
- optimalizace stránky
- vnitřní optimalizace
- sebepropagace
- jak propagovat zdroj
- jak propagovat svůj web
- jak propagovat web sami
- jak propagovat web sami
- sebepropagace
- propagace zdarma
- propagace zdarma
- optimalizace pro vyhledávače
- jak propagovat web v Yandexu
- jak propagovat web v Yandexu
- propagace pod Yandex
- Propagace Google
- propagace na Googlu
- indexování
- zrychlení indexování
- místo pro výběr dárců
- screening dárců
- propagace stráží
- použití stráží
- propagace blogu
- Algoritmus Yandex
- Aktualizace prsou
- aktualizace vyhledávací databáze
- Aktualizace Yandex
- odkazy navždy
- věčné odkazy
- pronajmout odkazy
- pronajatý odkaz
- propojení s měsíční platbou
- sestavení sémantického jádra
- propagační tajemství
- propagační tajemství
- SEO tajemství
- tajemství optimalizace
Myslím, že to stačí, takže seznam má půl stránky;) Obecně platí, že v první fázi je potřeba maximálně analyzovat své odvětví a vybrat co nejvíce frází, které odrážejí téma webu . I když, pokud jste v této fázi něco vynechali, nezoufejte - vynechané fráze se určitě objeví v dalších fázích, jen budete muset udělat spoustu práce navíc, ale to nevadí. Vezmeme náš seznam a zkopírujeme ho sběrateli klíčů. Dále klikněte na tlačítko - Analýza z Yandex.Wordstat:

Analýza může trvat poměrně dlouho, takže byste měli být trpěliví. Sestavení sémantického jádra obvykle trvá 3–5 dní a první den zabere příprava základního sémantického jádra a analýza.
Sepsal jsem podrobný návod, jak se zdrojem pracovat a jak vybírat klíčová slova. O propagaci webu se můžete dozvědět i na základě nízkofrekvenčních dotazů.
Navíc řeknu, že místo brainstormingu můžeme použít hotovou sémantiku konkurentů pomocí jedné ze specializovaných služeb, například SpyWords. V rozhraní této služby jednoduše zadáme klíčové slovo, které potřebujeme a vidíme hlavní konkurenty, kteří jsou u této fráze přítomni v TOP. Kromě toho lze pomocí této služby kompletně stáhnout sémantiku webových stránek jakékoli konkurence.

Dále můžeme vybrat kteréhokoli z nich a vytáhnout jeho dotazy, které zůstanou k prosátí z odpadu a použity jako základní sémantika pro další analýzu. Nebo to můžeme udělat ještě jednodušeji a použít .
Čištění sémantiky
Jakmile se analýza Wordstat úplně zastaví - je čas odstranit sémantické jádro. Tato fáze je velmi důležitá, proto jí věnujte náležitou pozornost.
Takže moje analýza skončila, ale fráze jsem dostal Tolik, a proto nám prosévání slov může zabrat více času. Než tedy přejdete k určení frekvence, měli byste provést počáteční čištění slov. Uděláme to v několika fázích:
1. Pojďme odfiltrovat dotazy s velmi nízkými frekvencemi
Chcete-li to provést, klikněte na symbol pro řazení podle frekvence a začněte mazat všechny dotazy s frekvencí nižší než 30:

Myslím, že se s tímto bodem snadno vyrovnáte.
2. Odstraníme dotazy, které nedávají smysl
Jsou dotazy, které mají dostatečnou frekvenci a nízkou konkurenci, ale jsou Vůbec se nehodí k našemu tématu. Takové klíče musí být odstraněny před kontrolou přesných výskytů klíče, protože ověření může být velmi časově náročné. Takové klíče ručně odstraníme. Pro můj blog se tedy následující ukázalo jako zbytečné:
kurzy optimalizace pro vyhledávače prodej propagovaného webu
Analýza sémantického jádra
V této fázi musíme určit přesné frekvence našich klíčů, pro které musíte kliknout na symbol lupy, jak je znázorněno na obrázku:

Proces je poměrně dlouhý, takže si můžete jít uvařit čaj)
Když byla kontrola úspěšná, musíme pokračovat v čištění našeho jádra.
Doporučuji smazat všechny klíče s frekvencí méně než 10 žádostí. Pro svůj blog také smažu všechny dotazy s hodnotami nad 1 000, protože s takovými dotazy neplánuji pokračovat.
Export a seskupení sémantického jádra
Nemyslete si, že tato fáze bude poslední. Vůbec ne! Nyní musíme výslednou skupinu přenést do Excelu pro maximální přehlednost. Dále budeme třídit podle stránek a pak uvidíme mnoho nedostatků, které opravíme.
Export sémantiky webu do Excelu není vůbec obtížný. Chcete-li to provést, stačí kliknout na odpovídající symbol, jak je znázorněno na obrázku:
Po vložení do Excelu se nám zobrazí následující obrázek:
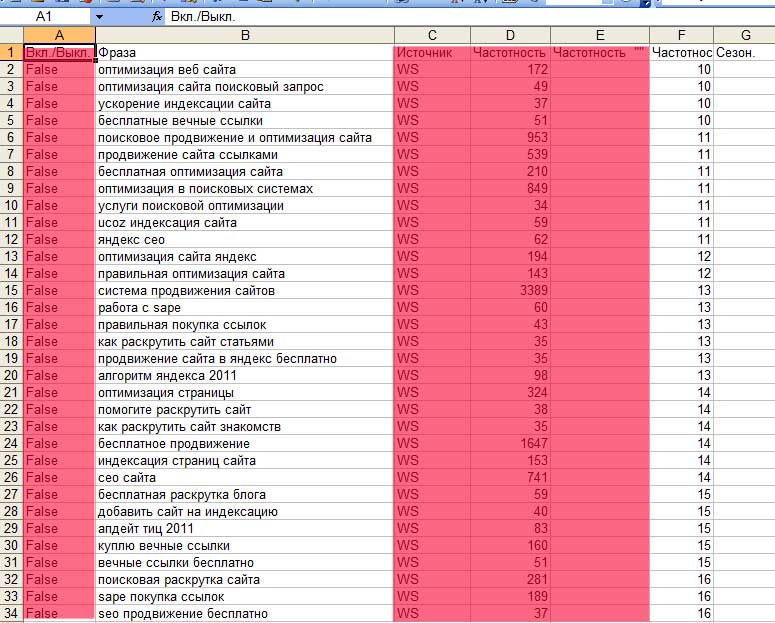
Sloupce označené červeně je nutné smazat. Poté vytvoříme v Excelu další tabulku, která bude obsahovat finální sémantické jádro.
Nová tabulka bude mít 3 sloupce: URLstránky, klíčová fráze a on frekvence. Pro adresu URL vyberte buď existující stránku, nebo stránku, která bude vytvořena v budoucnu. Nejprve vybereme klíče pro hlavní stránku mého blogu:

Po všech manipulacích vidíme následující obrázek. A hned vyvstává několik závěrů:
- takovéto vysokofrekvenční dotazy by měly mít mnohem větší konec méně frekventovaných frází, než vidíme
- seo novinky
- objevil se nový klíč, který jsme dříve nevzali v úvahu - SEO články. Tento klíč je třeba analyzovat
Jak jsem již řekl, nelze před námi skrýt ani jeden klíč. Dalším krokem pro nás je brainstorming těchto tří frází. Po brainstormingu zopakujeme všechny kroky od prvního bodu pro tyto klíče. To vše se vám může zdát příliš dlouhé a únavné, ale je to tak – sestavení sémantického jádra je velmi zodpovědná a pečlivá práce. Dobře navržené pole ale výrazně pomůže při propagaci webu a může výrazně ušetřit váš rozpočet.
Po všech provedených operacích jsme byli schopni získat nové klíče pro hlavní stránku tohoto blogu:
- nejlepší seo blog
- seo novinky
- SEO články
A některé další. Myslím, že technika je vám jasná.
Po všech těchto manipulacích uvidíme, které stránky našeho projektu je třeba změnit () a které nové stránky je třeba přidat. Většinu klíčů, které jsme našli (s frekvencí až 100 a někdy i mnohem vyšší), lze snadno propagovat samostatně.
Konečné vyřazení
V zásadě je sémantické jádro téměř hotové, ale je tu ještě jeden poměrně důležitý bod, který nám pomůže výrazně zlepšit naši sémantickou skupinu. K tomu potřebujeme Seopult.
*Ve skutečnosti zde můžete použít kteroukoli z podobných služeb, které vám umožní zjistit konkurenci podle klíčových slov, například Mutagen!
V Excelu tedy vytvoříme další tabulku a zkopírujeme tam pouze názvy klíčů (střední sloupec). Abych neztrácel spoustu času, zkopíruji pouze klíče pro hlavní stránku mého blogu:

Poté zkontrolujeme cenu za jedno kliknutí pomocí našich klíčových slov:
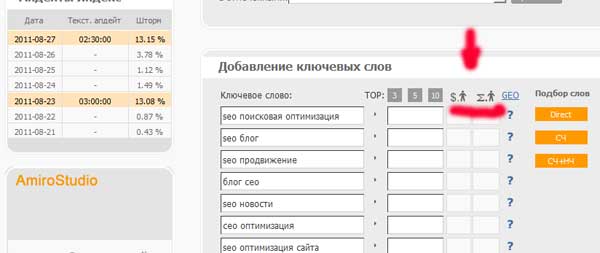
Náklady na přechod u některých frází přesáhly 5 rublů. Takové fráze je třeba z našeho jádra odstranit.

Možná se vaše preference budou mírně lišit, pak můžete vyloučit levnější fráze nebo naopak. V mém případě jsem vymazal 7 frází.
Užitečné informace!
na sestavení sémantického jádra s důrazem na eliminaci nejvíce málo konkurenčních klíčových slov.
Pokud máte vlastní internetový obchod - číst, který popisuje, jak lze sémantické jádro použít.
Shlukování sémantického jádra
Jsem si jistý, že jste toto slovo v souvislosti s optimalizací pro vyhledávače již slyšeli. Pojďme zjistit, co je to za zvíře a proč je to potřeba při propagaci webu.
Klasický model propagace vyhledávače vypadá takto:
- Výběr a analýza vyhledávacích dotazů
- Seskupování požadavků podle stránek webu (vytváření vstupních stránek)
- Příprava SEO textů pro vstupní stránky na základě skupiny dotazů na tyto stránky
Clustering se používá k usnadnění a zlepšení druhé fáze ve výše uvedeném seznamu. Shlukování je ve své podstatě softwarová metoda, která slouží ke zjednodušení této fáze při práci s velkou sémantikou, ale ne vše je tak jednoduché, jak by se na první pohled mohlo zdát.
Abyste lépe porozuměli teorii shlukování, měli byste si udělat krátký exkurz do historie SEO:
Ještě před pár lety, kdy pojem clustering nekoukal na každém rohu, SEO specialisté v drtivé většině případů seskupovali sémantiku ručně. Ale při seskupování obrovské sémantiky do 1000, 10 000 a dokonce 100 000 dotazů se tento postup pro obyčejného člověka změnil ve skutečnou dřinu. A pak se všude začala používat metoda seskupování podle sémantiky (a dnes tento přístup používá mnoho lidí). Metoda seskupování podle sémantiky zahrnuje kombinování dotazů, které mají sémantickou příbuznost, do jedné skupiny. Do jedné skupiny byly například sloučeny požadavky „koupit pračku“ a „koupit pračku do 10 000“. A všechno by bylo v pořádku, ale tato metoda obsahuje řadu kritických problémů a pro jejich pochopení je nutné zavést do našeho vyprávění nový termín, a to „ požadovat záměr”.
Nejjednodušeji lze tento termín popsat jako uživatelskou potřebu, jeho přání. Záměr není nic jiného než přání uživatele zadávat vyhledávací dotaz.
Základem seskupování sémantiky je shromáždit do jedné skupiny dotazy, které mají stejný záměr, nebo co nejbližší záměry, a zde se najednou objeví dvě zajímavé vlastnosti, a to:
- Stejný záměr může mít několik dotazů, které nemají žádnou sémantickou podobnost, například „údržba auta“ a „přihlásit se k údržbě“
- Dotazy, které mají absolutní sémantickou podobnost, mohou obsahovat radikálně odlišné záměry, například situace v učebnici - „mobilní telefon“ a „mobilní telefony“. V jednom případě si chce uživatel koupit telefon a ve druhém se dívat na film
Seskupování sémantiky podle sémantické korespondence tedy nebere v úvahu záměr požadavků. A takto sestavené skupiny vám nedovolí napsat text, který se dostane na TOP. Při ručním seskupování, aby se toto nedorozumění odstranilo, analyzovali kluci s profesí „užitečný SEO specialista“ výsledky vyhledávání ručně.
Podstatou shlukování je porovnat vygenerované výsledky vyhledávače při hledání vzorů. Z této definice byste si měli okamžitě poznamenat, že samotné shlukování není konečnou pravdou, protože generovaný výstup nemusí plně odhalit záměr (v databázi Yandex prostě nemusí být stránka, která správně sloučila požadavky do skupiny).
Mechanika shlukování je jednoduchá a vypadá takto:
- Systém jeden po druhém zapisuje všechny jemu zadané dotazy do výsledků vyhledávání a pamatuje si výsledky z TOP
- Po zadání dotazů jeden po druhém a uložení výsledků systém hledá průsečíky ve výsledcích. Pokud je stejný web se stejným dokumentem (stránka webu) v TOP pro několik požadavků najednou, pak lze tyto požadavky teoreticky sloučit do jedné skupiny
- Důležitým se stává parametr, jako je síla seskupení, která systému přesně říká, kolik křižovatek by mělo být, aby bylo možné přidat požadavky do jedné skupiny. Například síla seskupení 2 znamená, že výsledky pro 2 různé dotazy musí obsahovat alespoň dva průniky. Ještě jednodušeji řečeno, alespoň dvě stránky dvou různých webů musí být současně v TOP pro jeden a další požadavek. Příklad níže.
- Při seskupování velkých sémantik se stává relevantní logika vazeb mezi dotazy, na základě které se rozlišují 3 základní typy shlukování: měkké, střední a tvrdé. O typech shlukování si povíme více v dalších záznamech tohoto deníku.
Sémantické jádro stránek je to, co uživatelé na internetu používají k vyhledávání služeb, produktů a jakýchkoli dalších informací, které tato stránka nabízí. Pro webmastery je to akční plán na propagaci zdroje. V ideálním plánu Sémantické jádro webu je vytvořeno jednou, než začne optimalizace a propagace.
Sémantické jádro webu se obvykle skládá v několika fázích:
- Jsou vybrány všechny druhy slov (fráze), které jsou vhodné k tématu webu. Nejprve se můžete omezit na 100–200 vyhledávacích dotazů. Abyste věděli, které dotazy jsou pro vás vhodné, odpovězte si na otázku „Čemu chci svůj web věnovat?“
- Rozšíření sémantického jádra pomocí asociativních dotazů
- Nevhodná slova by měla být odstraněna. Zde odfiltrujete fráze, které nebudete používat k propagaci svých stránek. Takových slov je většinou více než polovina.
- Odpadají vysoce konkurenční dotazy, pro které nemá smysl stránky propagovat. Obvykle jsou odstraněna tři slova z pěti nebo více.
- A konečně, toto je správné rozložení seznamu vyhledávacích dotazů na stránkách zdrojů. Doporučuje se ponechat vysoce konkurenční dotazy na hlavní stránce zdroje, méně konkurenční dotazy seskupit podle významu a umístit na jiné stránky. Chcete-li to provést, musíte vytvořit dokument v aplikaci Excel a rozdělit klíčová slova na stránky.
Výběr vyhledávacích dotazů a frekvence kontroly
První věc, kterou musíte udělat, je shromáždit co nejvíce různých dotazů na vaše téma, které zajímají uživatele na internetu. K tomu existují dvě metody:
- Bezplatné, mezi které patří: Wordstat Yandex, Slovoeb, staromódní způsob, rady od Google (External Keyword Tool), analýza sémantiky konkurentů a tipy pro vyhledávání.
- Placené, které zahrnují Key Collector, Semrush, Pastukhov databáze a některé další služby.
Tyto nástroje jsou vhodné pro různé účely (například Semrush se nejlépe používá pro burzhunet). To vše lze samozřejmě svěřit optimalizátorům, ale existuje možnost, že obdržíte neúplné sémantické jádro.
Mnoho lidí používá Pastukhovovu databázi ke shromažďování klíčových frází, ale s Key Collector je mnohem pohodlnější shromažďovat požadavky ze služeb.
V počáteční fázi je lepší shromažďovat dotazy v Excelu, vypadá to takto:

Pokud je Google pro váš zdroj důležitější, zaměřte se na něj, ale také vezměte v úvahu a analyzujte klíčová slova z Yandexu. Je také velmi důležité shromažďovat velké množství nízkofrekvenčních dotazů, díky nimž získáte provoz mnohem rychleji.
Další možností, kterou můžete využít, je zjistit klíčové fráze (slova) od vašich konkurentů a použít je. V této fázi jednoduše shromáždíte co nejvíce klíčových frází (slov), které jsou relevantní k tématu vašeho zdroje, a poté přejdete k další fázi – filtrování.
Analýza požadavků, odstranění figurín
Tato fáze je již jednodušší, zde je potřeba odfiltrovat fiktivní slova a ta, která nesouvisejí s tématem webu. Máte například rozvoz obědů v Kyjevě, ale na seznamu jsou i další města.
Jak identifikovat prázdné požadavky? Přejděte na Yandex Wordstat a zadejte klíčové slovo:

Za měsíc vidíte 881 zobrazení, ale přesněji:

Nyní se objevuje úplně jiný obrázek. Možná to není nejlepší příklad, ale hlavní věc je, že dostanete nápad. Existuje velké množství klíčových frází, u kterých je vidět dostatečná návštěvnost, i když ve skutečnosti tam nic není. Proto je třeba takové fráze vyřadit.
Pokud například osoba před (nebo po) zadání požadavku „doručení oběda“ zadala do vyhledávacího pole jinou frázi (tzv. jedna vyhledávací relace), pak Yandex předpokládá, že tyto vyhledávací fráze jsou nějak propojeny. Pokud je takový vztah pozorován mezi několika lidmi, pak se takové asociativní dotazy zobrazí v pravém sloupci wordstat.

Takové vyhledávací dotazy jsou seřazeny v okně wordstat v sestupném pořadí podle frekvence jejich zadávání ve spojení s hlavním dotazem v tomto měsíci (je zobrazena frekvence jejich použití ve vyhledávači Yandex). Tyto informace musíte použít k rozšíření sémantického jádra vašeho zdroje.
Distribuce požadavků na stránky
Poté musíte shromážděná klíčová slova (fráze) distribuovat na stránky vašeho webu. Distribuce je mnohem jednodušší, když ještě nemáte samotné stránky.
Zaměřte se především na klíčová slova ve vyhledávacích dotazech a jejich frekvenci. Chcete-li se vypořádat s konkurencí, měli byste udělat toto: věnovat hlavní stránku jednomu nebo dvěma vysoce konkurenčním dotazům.
Pro středně konkurenční nebo málo konkurenční dotazy odpovídajícím způsobem optimalizujte stránky sekcí a článků.
Pokud existuje sémantická podobnost ve vyhledávacích dotazech, jednoduše shromážděte stejné fráze a definujte je v jedné skupině. Při vytváření klíčových slov k propagaci zdroje vždy používejte nejen standardní nástroje, ale také kreativní přístup.
Kombinací nestandardních a klasických metod můžete jednoduše a rychle vytvořit sémantické jádro webu, zvolit nejoptimálnější strategii propagace a dosáhnout úspěchu mnohem rychleji!
Pokud znáte bolest „nesympatie“ vyhledávačů ke stránkám vašeho internetového obchodu, přečtěte si tento článek. Budu mluvit o cestě ke zvýšení viditelnosti webu, přesněji o jeho první fázi – sběru klíčových slov a sestavení sémantického jádra. O algoritmu jeho tvorby a používaných nástrojích.
Proč vytvářet sémantické jádro?
Pro zvýšení viditelnosti stránek webu. Ujistěte se, že vyhledávací roboty Yandex a Google začnou nacházet stránky vašeho webu na základě požadavků uživatelů. Sběr klíčových slov (kompilace sémantiky) je samozřejmě prvním krokem k tomuto cíli. Dále je načrtnuta podmíněná „kostra“ pro distribuci klíčových slov na různé vstupní stránky. A pak jsou napsány a implementovány články/metaznačky.
Mimochodem, na internetu můžete najít mnoho definic sémantického jádra.
1. „Sémantické jádro je uspořádaný soubor hledaných slov, jejich morfologických forem a frází, které nejpřesněji charakterizují typ činnosti, produktu nebo služby nabízené webem.“ Wikipedie.
Chcete-li v Serpstatu shromáždit sémantiku konkurence, zadejte jeden z klíčových dotazů, vyberte oblast, klikněte na „Hledat“ a přejděte do kategorie „Analýza klíčových frází“. Poté vyberte „SEO Analysis“ a klikněte na „Výběr fráze“. Exportovat výsledky:

2.3. K vytvoření sémantického jádra používáme Key Collector/Slovoeb
Pokud potřebujete vytvořit sémantické jádro pro velký internetový obchod, bez Key Collectoru se neobejdete. Ale pokud jste začátečník, je výhodnější použít bezplatný nástroj - Sloboeb (nenechte se tímto názvem vyděsit). Stáhněte si program a v nastavení Yandex.Direct zadejte přihlašovací jméno a heslo pro svůj Yandex.Mail:  Vytvořte nový projekt. Na záložce „Data“ vyberte funkci „Přidat fráze“. Vyberte svůj region a zadejte požadavky, které jste obdrželi dříve:
Vytvořte nový projekt. Na záložce „Data“ vyberte funkci „Přidat fráze“. Vyberte svůj region a zadejte požadavky, které jste obdrželi dříve:  Rada: vytvořte samostatný projekt pro každou novou doménu a vytvořte samostatnou skupinu pro každou kategorii/vstupní stránku. Například:
Rada: vytvořte samostatný projekt pro každou novou doménu a vytvořte samostatnou skupinu pro každou kategorii/vstupní stránku. Například:  Nyní sbírejte sémantiku z Yandex.Wordstat. Otevřete kartu „Sběr dat“ - „Dávkový sběr slov z levého sloupce Yandex.Wordstat“. V okně, které se otevře, zaškrtněte políčko „Nepřidávat fráze, pokud jsou již v jiných skupinách“. Zadejte několik nejoblíbenějších (vysokofrekvenčních) frází mezi uživateli a klikněte na „Začít sbírat“:
Nyní sbírejte sémantiku z Yandex.Wordstat. Otevřete kartu „Sběr dat“ - „Dávkový sběr slov z levého sloupce Yandex.Wordstat“. V okně, které se otevře, zaškrtněte políčko „Nepřidávat fráze, pokud jsou již v jiných skupinách“. Zadejte několik nejoblíbenějších (vysokofrekvenčních) frází mezi uživateli a klikněte na „Začít sbírat“: 
Mimochodem, pro velké projekty v Key Collector můžete sbírat statistiky ze služeb analýzy konkurence SEMrush, SpyWords, Serpstat (ex. Prodvigator) a dalších doplňkových zdrojů.



