Nástroj pro zpracování obrazu. Krátký kurz teorie zpracování obrazu. I. M. Zhuravel. Metody segmentace obrazu
Letos v létě se mi poštěstilo získat letní stáž ve firmě Itseez
. Byl jsem požádán, abych prozkoumal moderní metody, které by nám umožnily zvýraznit umístění objektů na obrázku. Tyto metody v podstatě spoléhají na segmentaci, takže jsem začal svou práci seznámením se s touto oblastí počítačového vidění.
Segmentace obrazu
- Toto je rozdělení obrázku do mnoha oblastí, které jej pokrývají. Segmentace se používá v mnoha oblastech, například ve výrobě pro indikaci vad při montáži dílů, v lékařství pro primární zpracování obrazu a také pro sestavování terénních map ze satelitních snímků. Pro ty, kteří mají zájem pochopit, jak takové algoritmy fungují, vítejte na cat. Podíváme se na několik metod z knihovny počítačového vidění OpenCV
.
Segmentační algoritmus podle povodí (WaterShed)


Algoritmus pracuje s obrazem jako funkcí dvou proměnných f=I(x,y) , Kde x, y – souřadnice pixelů:



Hodnotou funkce může být intenzita nebo velikost gradientu. Pro největší kontrast můžete z obrázku vzít přechod. Pokud po ose OZ Při vykreslování absolutní hodnoty gradientu se v místech, kde je rozdíl v intenzitě, tvoří vyvýšeniny a v homogenních oblastech roviny. Po nalezení minima funkce F , probíhá proces plnění „vodou“, který začíná od globálního minima. Jakmile hladina vody dosáhne dalšího lokálního minima, začne se plnit vodou. Když se začnou slučovat dvě oblasti, vytvoří se oddíl, který zabrání sloučení oblastí. Voda bude dále stoupat, dokud nebudou regiony odděleny pouze uměle vybudovanými přepážkami (obr. 1).



Obr.1. Ilustrace procesu plnění vodou
Takový algoritmus může být užitečný, pokud má obraz malý počet lokálních minim, ale pokud jich je velké množství, dochází k nadbytečnému rozdělení na segmenty. Pokud například přímo aplikujeme algoritmus na Obr. 2, dostaneme spoustu malých detailů na Obr. 3.

Rýže. 2. Původní obrázek

Rýže. 3. Obraz po segmentaci pomocí algoritmu WaterShed
Jak se vypořádat s malými detaily?
Chcete-li se zbavit přebytku malých detailů, můžete nastavit oblasti, které budou vázány na nejbližší minima. Oddíl bude vytvořen pouze v případě, že jsou sloučeny dvě oblasti se značkami, jinak se tyto segmenty sloučí. Tento přístup odstraňuje efekt redundantní segmentace, ale vyžaduje předběžné zpracování obrazu pro výběr značek, které lze interaktivně označit v obraze na obr. 4, 5.

Rýže. 4. Obrázek se značkami

Rýže. 5. Obraz po segmentaci pomocí algoritmu WaterShed pomocí značek
Pokud chcete jednat automaticky bez zásahu uživatele, můžete využít například funkci findContours() pro zvýraznění značek, ale i zde je pro lepší členění třeba vyloučit malé kontury Obr. 6., například jejich odstranění podél prahu po délce obrysu. Nebo použijte erozi s dilatací k odstranění malých detailů před zvýrazněním kontur.

Rýže. 6. Jako značky byly použity obrysy s délkou nad určitým prahem
Výsledkem algoritmu získáme masku se segmentovaným obrazem, kde jsou pixely jednoho segmentu označeny stejným štítkem a tvoří spojenou oblast. Hlavní nevýhodou tohoto algoritmu je použití postupu předzpracování pro obrázky s velkým počtem lokálních minim (snímky se složitou texturou a množstvím různých barev).
Obrázek mat = imread("coins.jpg", CV_LOAD_IMAGE_COLOR); // vybereme kontury Mat imageGray, imageBin; cvtColor(obrázek, obrázekGray, CV_BGR2GRAY); práh(imageGray, imageBin, 100, 255, THRESH_BINARY); std::vektor
Segmentační algoritmus (i, j) = Vec3b(255, 255, 255);
jinak vypráno.at

(i, j) = colorTab; ) ) imshow("transformace povodí", wshed); waitKey(0); můžete vybrat souřadnice pixelů (x, y) a komponenty RGB pixel. Vykreslením pixelů v prostoru prvku můžete na určitých místech vidět shluky.

Rýže. 7. (a) Pixely v prostoru 2D prvků. (b) Pixely, které dosahují stejného lokálního maxima, jsou zbarveny stejnou barvou. (c) - funkce hustoty, maxima odpovídají místům nejvyšší koncentrace pixelů. Obrázek je převzat z článku.
Abychom usnadnili popis kondenzací bodů, uvádíme funkce hustoty
: 
– příznakový vektor i
-tý pixel, d
- počet znaků, N
- počet pixelů, h
- parametrem zodpovědným za hladkost je jádro. Maxima funkce jsou umístěna v bodech kondenzace obrazových pixelů v prostoru rysů. Pixely patřící do stejného lokálního maxima se spojí do jednoho segmentu. Ukazuje se, že abyste zjistili, ke kterému z koncentračních center pixel patří, musíte krokovat podél gradientu, abyste našli nejbližší lokální maximum.
Odhad gradientu z funkce hustoty
Střední vektor posunu lze použít k odhadu gradientu funkce hustoty ![]()
Jako jádro v OpenCV se používá jádro Epanechnikov: 
- toto je objem d
-rozměrná koule s jednotkovým poloměrem. 
 znamená, že součet nejde přes všechny pixely, ale pouze přes ty, které spadají do koule o poloměru h
se středem v bodě, kde vektor ukazuje v prostoru prvků. Toto je zavedeno speciálně pro snížení počtu výpočtů. - objem d
-rozměrná koule s poloměrem h Můžete samostatně nastavit poloměr pro prostorové souřadnice a samostatně poloměr v barevném prostoru. - počet pixelů spadajících do koule. Velikost
znamená, že součet nejde přes všechny pixely, ale pouze přes ty, které spadají do koule o poloměru h
se středem v bodě, kde vektor ukazuje v prostoru prvků. Toto je zavedeno speciálně pro snížení počtu výpočtů. - objem d
-rozměrná koule s poloměrem h Můžete samostatně nastavit poloměr pro prostorové souřadnice a samostatně poloměr v barevném prostoru. - počet pixelů spadajících do koule. Velikost  lze považovat za odhad hodnoty v regionu .
lze považovat za odhad hodnoty v regionu . 

Pro chůzi po gradientu tedy stačí vypočítat hodnotu ![]() - střední vektor posunu. Je třeba mít na paměti, že pokud vyberete jiné jádro, střední vektor posunu bude vypadat jinak.
- střední vektor posunu. Je třeba mít na paměti, že pokud vyberete jiné jádro, střední vektor posunu bude vypadat jinak.
Při výběru souřadnic pixelů a intenzity barev jako prvků se pixely s podobnými barvami a umístěné blízko sebe sloučí do jednoho segmentu. Pokud tedy zvolíte jiný vektor prvku, budou pixely sloučeny do segmentů pomocí něj. Pokud například odstraníme souřadnice z útvarů, pak obloha a jezero budou považovány za jeden segment, protože pixely těchto objektů v prostoru útvaru by spadaly do jednoho lokálního maxima.
Pokud se objekt, který chceme vybrat, skládá z oblastí, které se výrazně liší barvou, pak (i, j) = Vec3b(255, 255, 255); nebude schopen spojit tyto oblasti do jedné a náš objekt se bude skládat z několika segmentů. Ale je dobré se vyrovnat s předmětem jednotné barvy na pestrém pozadí. Více (i, j) = Vec3b(255, 255, 255); používá se při implementaci algoritmu pro sledování pohybujících se objektů.
Ukázkový kód pro spuštění algoritmu:
Mat image = imread("jahoda.jpg", CV_LOAD_IMAGE_COLOR); Mat imageSegment; int prostorový Poloměr = 35; int colorRadius = 60; int pyramidÚrovně = 3; pyrMeanShiftFiltering(image, imageSegment, spaceRadius, colorRadius, pyramidLevels); imshow("MeanShift", imageSegment); waitKey(0);
Výsledek: 
Rýže. 8. Původní obrázek

Rýže. 9. Po segmentaci algoritmem (i, j) = Vec3b(255, 255, 255);
Segmentační algoritmus FloodFill
Pomocí FloodFill(způsob vyplnění nebo „zaplavení“) můžete vybrat oblasti jednotné barvy. Chcete-li to provést, musíte vybrat počáteční pixel a nastavit interval pro změnu barvy sousedních pixelů vzhledem k původnímu. Interval může být také asymetrický. Algoritmus sloučí pixely do jednoho segmentu (vyplní je stejnou barvou), pokud spadají do určeného rozsahu. Výstupem bude segment vyplněný určitou barvou a její plocha v pixelech.Tento algoritmus může být užitečný pro vyplnění oblasti s nepatrnými barevnými rozdíly s jednotným pozadím. Jeden případ použití FloodFill Může být možné identifikovat poškozené okraje předmětu. Pokud například vyplněním homogenních oblastí určitou barvou algoritmus vyplní i sousední oblasti, pak byla narušena integrita hranice mezi těmito oblastmi. Na obrázku níže můžete vidět, že je zachována celistvost hranic vyplněných oblastí: 

Rýže. 10, 11. Původní obrázek a výsledek po vyplnění několika oblastí
A následující obrázky ukazují pracovní možnost FloodFill pokud je poškozena jedna z hranic na předchozím obrázku.


Rýže. 12, 13. Ilustrace práce FloodFill když je narušena celistvost hranice mezi vyplněnými oblastmi
Ukázkový kód pro spuštění algoritmu:
Obrázek mat = imread("třešeň.jpg", CV_LOAD_IMAGE_COLOR); Bod počáteční bod; startPoint.x = image.cols/2; startPoint.y = image.rows/2; Skalární loDiff(20, 20, 255); Skalární vzestupDiff(5, 5, 255); Skalární fillColor(0, 0, 255); int sousedé = 8; Rect doména; int area = floodFill(obrazek, startPoint, fillColor, &domena, loDiff, upDiff, sousedi); obdélník(obrázek, doména, skalární(255, 0, 0)); imshow("floodFill segmentation", obrázek); waitKey(0);
Do proměnné plocha bude zaznamenán počet „vyplněných“ pixelů.
Výsledek: 

Segmentační algoritmus GrabCut
Jedná se o interaktivní algoritmus výběru objektů, vyvinutý jako pohodlnější alternativa k magnetickému lasu (k výběru objektu musel uživatel obkreslit jeho obrys myší). Aby algoritmus fungoval, stačí objekt spolu s částí pozadí uzavřít do obdélníku (drapáku). Objekt bude automaticky segmentován (oříznut).

Potíže mohou nastat během segmentace, pokud jsou v ohraničujícím rámečku barvy, které se vyskytují ve velkém množství nejen v objektu, ale také v pozadí. V tomto případě můžete přidat další značky objektu (červená čára) a pozadí (modrá čára).



Podívejme se na myšlenku algoritmu. Základem je interaktivní segmentační algoritmus GraphCut, kdy uživatel potřebuje umístit značky na pozadí a na objekt. S obrázkem se zachází jako s polem ![]() .Z
- hodnoty intenzity pixelů, N
-celkový počet pixelů. K oddělení objektu od pozadí algoritmus určí hodnoty prvků pole průhlednosti a může nabývat dvou hodnot, pokud = 0
, pak pixel patří pozadí if = 1
, pak objekt. Interní parametr obsahuje histogram rozložení intenzity popředí a histogram pozadí:
.Z
- hodnoty intenzity pixelů, N
-celkový počet pixelů. K oddělení objektu od pozadí algoritmus určí hodnoty prvků pole průhlednosti a může nabývat dvou hodnot, pokud = 0
, pak pixel patří pozadí if = 1
, pak objekt. Interní parametr obsahuje histogram rozložení intenzity popředí a histogram pozadí:
.
Úkolem segmentace je najít neznámé. Za energetickou funkci se považuje:
Navíc minimální energie odpovídá nejlepší segmentaci. 
V(a, z)
- termín je zodpovědný za spojení mezi pixely. Součet jde přes všechny dvojice pixelů, které jsou sousedy, dis(m,n)
- Euklidovská vzdálenost. ![]() odpovídá za účast dvojic pixelů na celkovém if a n = a m
, pak tato dvojice nebude brána v úvahu.
odpovídá za účast dvojic pixelů na celkovém if a n = a m
, pak tato dvojice nebude brána v úvahu. ![]() - odpovídá za kvalitu segmentace, tzn. oddělení objektu od pozadí.
- odpovídá za kvalitu segmentace, tzn. oddělení objektu od pozadí.
Po nalezení globálního minima energetické funkce E , dostaneme pole průhlednosti. Pro minimalizaci energetické funkce je obraz popsán jako graf a hledá se minimální řez grafu. Na rozdíl od GraphCut v algoritmu GrabCut pixely jsou uvažovány v prostoru RGB, proto se k popisu statistik barev používá model Gaussian Mixture Model (GMM). Operace algoritmu GrabCut můžete vidět spuštěním ukázky OpenCV
Segmentace obrazu pomocí U-Net v praxi
Zavedení
V tomto blogovém příspěvku se podíváme na to, jak Unet funguje, jak jej implementovat a jaká data jsou potřebná k jeho trénování. Za tímto účelem zvážíme:
- jako zdroj inspirace.
- Pytorchjako nástroj k realizaci naší myšlenky.
- Kaggle soutěže jako místo, kde můžeme testovat naše hypotézy na reálných datech.
Nebudeme se řídit článkem na 100 %, ale pokusíme se uvědomit si jeho podstatu a přizpůsobit si ho našim potřebám.
Prezentace problému
V tomto problému dostáváme obrázek auta a jeho binární masku (lokalizující pozici auta na obrázku). Chceme vytvořit model, který bude schopen oddělit obrázek auta od pozadí s přesností pixel po pixelu více než 99 %.
Abychom pochopili, co chceme, obrázek gif je níže:
Obrázek vlevo je původní obrázek, vpravo je maska, která bude na obrázek aplikována. Využijeme neuronovou síť Unet, která se naučí automaticky vytvářet masku.
- Přivádění obrázků aut do neuronové sítě.
- Použití ztrátové funkce, porovnání výstupu neuronové sítě s odpovídajícími maskami a vrácení chyby pro síť, aby se zjistilo, kde síť selhává.
Struktura kódu
Kód byl co nejvíce zjednodušen, aby bylo možné pochopit, jak funguje. Hlavní kód je v tomto souboru main.py Podívejme se na to řádek po řádku.
Kód
Projdeme si kód v main.py a článek. Nedělejte si starosti s detaily skrytými v jiných souborech projektu: podle potřeby vám ukážeme ty, které potřebujete.
Začněme od začátku:
def main(): #Hyperparameters input_img_resize = (572, 572) # Velikost změny velikosti vstupních obrázků neuronové sítě output_img_resize = (388, 388) # Velikost změny velikosti výstupních obrázků neuronové sítě batch_size = 3 epochy = 50 prahová hodnota = 0. 5 validation_size = 0. 2 sample_size = Žádné # -- Volitelné parametry threads = cpu_count() use_cuda = torch.cuda.is_available() script_dir = os.path.dirname(os.path. abspath(__file__ )) # Školení zpětných volání tb_viz_cb = TensorboardVisualizerCallback(os.path.join(script_dir,"../logs/tb_viz" )) tb_logs_cb = TensorboardLoggerCallback(os.path.join/script_logs/tb,". )) model_saver_cb = ModelSaverCallback(os.path.join(script_dir,"../output/models/model_" + helpers.get_model_timestamp()), verbose= True )
V první části definujete své hyperparametry, které můžete nakonfigurovat tak, aby vyhovovaly vašim potřebám, například v závislosti na paměti GPU. Optimální parametry definovat některé užitečné parametry a zpětná volání. TensorboardVisualizerCallback je třída, která bude ukládat předpovědi tensorboard v každé éře tréninkového procesu, Zpětné volání TensorboardLogger zachová hodnoty ztrátové funkce a „přesnost“ pixel po pixelu tensorboard. A nakonec ModelSaverCallback po dokončení tréninku váš model uloží.
# Stáhněte si datové sady ds_fetcher = DatasetFetcher () ds_fetcher. download_dataset()
Tato sekce automaticky stáhne a načte datovou sadu z Kaggle. Vezměte prosím na vědomí, že pro úspěšné fungování tohoto kódu budete potřebovat účet Kaggle s uživatelským jménem a heslem, které by měly být umístěny v proměnných prostředí KAGGLE_USER A KAGGLE_PASSWD před spuštěním skriptu. Před nahráním dat jste také povinni přijmout pravidla soutěže. To lze provést na kartěstáhnout soutěžní data
# Získejte cestu k souborům pro neuronovou síť X_train, y_train, X_valid, y_valid = ds_fetcher.get_train_files(sample_size= sample_size, validation_size= validation_size) full_x_test = ds_fetcher.get_test_files_sampleball_sampleb zpět (os.cesta. join (script_dir, "../output/submit.csv.gz" ), origin_img_size, prahová hodnota)
Tento řádek definuje zpětné volání funkce pro test (nebo predikci). Uloží předpovědi do souboru gzip pokaždé, když je vytvořena nová dávka předpovědí. Předpovědi se tedy nebudou ukládat do paměti, protože jsou velmi velké.
Po dokončení procesu predikce můžete odeslat výsledný soubor odeslat.csv.gz z výstupní složky v Kaggle.
# -- Definujte naši architekturu neuronové sítě# Původní papír má 1 vstupní kanál, v našem případě máme 3 (RGB) net = unet_origin. UNetOriginal ((3 , *img_resize)) klasifikátor = nn. klasifikátor. CarvanaClassifier (net, epochs) optimalizátor = optim. 5 počet_pracovníků = threads, pin_memory= use_cuda) valid_ds = TrainImageDataset (X_valid, y_valid, input_img_resize, output_img_resize, prahová hodnota= prahová hodnota) valid_loader = DataLoader (valid_ds, batch_size, sampler= SequentialSampler (valid_workers_ds_nu), vlákno= pin_moryy
vytisknout( "Školení na () vzorcích a ověřování na () vzorcích". format(len(train_loader. dataset), len(valid_loader. dataset))) # Trénujte klasifikátor klasifikátoru. vlak(train_loader, valid_loader, epochs, callbacks= )
Nakonec uděláme totéž jako výše, ale spustíme předpověď. Říkáme našim pred_saver_cb.close_saver() vymazat a zavřít soubor obsahující předpovědi.
Implementace architektury neuronové sítě
Článek Unet představuje přístup pro segmentaci lékařského obrazu. Ukazuje se však, že tento přístup lze použít i pro jiné segmentační problémy. Včetně té, na které teď budeme pracovat.
Než budete pokračovat, měli byste si přečíst celý článek alespoň jednou. Nebojte se, pokud matematice úplně nerozumíte, můžete tuto část a také kapitolu Experimenty přeskočit. Naším cílem je získat celkový obraz.
Účel původního článku je odlišný od našeho, některé části si budeme muset upravit podle našich potřeb.
V době psaní práce chyběly 2 věci, které jsou nyní nezbytné pro urychlení konvergence neuronové sítě:
- BatchNorm.
- Výkonné GPU.
První byl vynalezen pouhé 3 měsíce předtím Unet, a na autory je asi ještě brzy Unet přidal do našeho článku.
K dnešnímu dni BatchNorm používá se téměř všude. Můžete se toho zbavit v kódu, pokud chcete článek hodnotit na 100 %, ale konvergování sítě se možná nedožijete.
Pokud jde o GPU, článek uvádí:
Abychom minimalizovali režii a maximálně využili paměť GPU, upřednostňujeme velké vstupní dlaždice před velkou velikostí dávky, a proto dávku zredukujeme na jeden obrázek.
Použili GPU s 6 GB RAM, ale v dnešní době má GPU více paměti, aby pojal obrázky v jedné dávce. Aktuální várka se rovná třem, funguje pro grafický procesor v GPU s 8 GB RAM. Pokud takovou grafickou kartu nemáte, zkuste snížit dávku na 2 nebo 1.
Ohledně metod augmentace (tedy zkreslení původního obrázku podle nějakého vzoru) diskutované v článku, použijeme jiné, než jaké jsou popsány v článku, protože naše obrázky se od biomedicínských obrázků velmi liší.
Nyní začněme od začátku návrhem architektury neuronové sítě:
Takhle vypadá Unet. Můžete najít ekvivalentní implementaci Pytorch v modulu nn.unet_origin.py.
Všechny třídy v tomto souboru mají alespoň 2 metody:
- __init__()kde budeme inicializovat naše vrstvy neuronové sítě;
- vpřed()což je metoda, která se nazývá, když neuronová síť obdrží vstup.
Podívejme se na detaily implementace:
- ConvBnRelu je blok obsahující operace Conv2D, BatchNorm a Relu. Namísto psaní 3 z nich pro každý zásobník kodéru (skupina operací dolů) a zásobníky dekodérů (skupina operací nahoru), seskupíme je do tohoto objektu a podle potřeby jej znovu použijeme.
- StackEncoder zapouzdřuje celou „hromadu“ operací, včetně operací ConvBnRelu A MaxPool jak je uvedeno níže:
Sledujeme výstup poslední transakce ConvBnRelu PROTI x_trace a vrátit jej, protože budeme tento výstup zřetězovat pomocí zásobníků dekodérů.
- StackDecoder je stejný jako StackEncoder, ale pro operace dekódování, dole ohraničený červeně:
Všimněte si, že bere v úvahu operaci trimování/zřetězení (obklopené oranžově) předáním down_tensor, což není nic jiného než tenzor x_trace vrácený naším StackEncoder .
- UNetOriginal- tady se děje kouzlo. Toto je naše neuronová síť, která sestaví všechny výše uvedené malé kostky. Metody init A vpřed jsou opravdu složité, přidávají tuny StackEncoder , střední část a na konci několik StackDecoder . Poté dostaneme výstup StackDecoder , přidáme k němu konvoluci 1x1 podle článku, ale namísto definování dvou filtrů jako výstupu definujeme pouze 1, což bude ve skutečnosti naše predikce masky ve stupních šedi. Dále „zkomprimujeme“ náš výstup, abychom odstranili velikost kanálu (je pouze 1, takže ji nemusíme ukládat).
Chcete-li porozumět podrobnostem každého bloku, umístěte do dopředné metody každé třídy zarážku ladění, abyste si mohli prohlédnout objekty podrobně. Můžete také vytisknout tvar výstupních tenzorů mezi vrstvami provedením tisku ( x.size() ).
Trénink neuronové sítě
- Ztrátová funkce
Nyní do skutečného světa. Podle článku:
Energetická funkce je vypočítána pomocí soft-max po pixelech na konečné mapě rysů v kombinaci s funkcí ztráty křížové entropie.
Jde o to, že v našem případě chceme použít koeficient kostky jako ztrátová funkce místo toho, co nazývají „energetickou funkcí“, protože to je metrika používaná vKaggle soutěž , který je definován:
Xje naše předpověď a Y- správně označená maska na aktuálním objektu. |X| znamená výkon soupravy X(počet prvků v této sadě) a ∩ pro průsečík mezi nimi X A Y.
Kód pro koeficient kostky najdete v nn.losses.SoftDiceLoss .
class SoftDiceLoss (nn.Module): def __init__(self, weight= None, size_average= True): super (SoftDiceLoss, self).__init__() def forward(self, logits, targets): smooth = 1 num = targets.size (0 ) probs = F.sigmoid(logits) m1 = probs.view(num, - 1 ) m2 = targets.view(num, - 1 ) průnik = (m1 * m2) skóre = 2 . * (průnik.součet(1) + hladké) / (m1.součet(1) + m2.součet(1) + hladké) skóre = 1 - skóre.součet() / num návratové skóreDůvod, proč je křižovatka implementována jako násobení a síla jako součet() Podle osa 1 (součet tří kanálů) je, že předpovědi a cíl jsou one-hot zakódované vektory.
Předpokládejme například, že předpověď v pixelu (0, 0) je 0,567 a cíl je 1, dostaneme 0,567 * 1 = 0,567. Pokud je cíl 0, dostaneme na této pozici pixelu 0.
Pro zpětné šíření jsme také použili hladký faktor 1. Pokud je předpověď pevným prahem 0 a 1, je obtížné ji zpětně šířit ztráta kostek.
Poté porovnáme ztrátu kostek s křížovou entropií, abychom dostali naši funkci celkové ztráty, kterou můžete najít v metodě _kritérium z nn.Classifier.CarvanaClassifier . Podle původního článku také používají hmotnostní mapu ve funkci ztráty křížové entropie, aby některé pixely při tréninku více chybovaly. V našem případě nic takového nepotřebujeme, takže použijeme zkříženou entropii bez jakékoli váhové mapy.
2. Optimalizátor
Protože se nezabýváme biomedicínskými snímky, použijeme vlastní augmentace . Kód najdete v img.augmentation.augment_img. Tam provádíme náhodný posun, rotaci, překlápění a změnu měřítka.
Trénink neuronové sítě
Nyní můžete začít trénovat. Jak každá epocha postupuje, budete moci vizualizovat předpovědi vašeho modelu na ověřovací sadě.
Chcete-li to provést, musíte běžet Tensorboard ve složce logs pomocí příkazu:
Tensorboard --logdir=./logs
Příklad toho, co můžete vidět v Tensorboard po epoše 1:
Článek popisuje studium metod segmentace obrazu na různých příkladech. Účelem studie je odhalit výhody a nevýhody některých známých metod.
Metody, které budou diskutovány v tomto článku:
- Metoda regionálního pěstování;
- Metoda povodí;
- Metoda normálních řezů.
Studium segmentačních metod na modelových snímcích
Výzkum segmentačních metod byl zpočátku prováděn na obrazových modelech. Jako modely bylo použito devět typů obrázků.
Výsledky studie ukázaly:
- Metoda pěstování regionu lokalizuje defekty textury, a to jak ty, které se ostře liší od pozadí, tak ty, které vznikly otáčením a změnou jasu textury;
- Metoda růstu oblasti lokalizuje defekty v různé míře při různých úhlech natočení textury;
- Uvažovaná metoda segmentace povodí ve své původní podobě neposkytuje lokalizaci defektů textury;
- Metoda normálních řezů je dobrá při lokalizaci přítomnosti textury odlišné od pozadí, ale nezvýrazňuje změny jasu a rotace textury.
Studium segmentačních metod na obrázcích objektů
Pro studium segmentačních metod byla připravena databáze obrázků různých objektů. Výsledné snímky byly segmentovány různými metodami, jejichž výsledky jsou uvedeny na obrázcích v tabulce
| Původní obrázek | Metoda regionálního pěstování | Metoda normálních řezů | Metoda povodí |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
Výsledky:
- Metoda růstu regionu neposkytuje lokalizaci segmentů v obrazech objektů;
- Uvažované metody rozvodí a normálních řezů v původní podobě nezajišťují lokalizaci prezentovaných objektů;
- Metoda normálních řezů poskytuje lokalizaci objektů v obrazech objektů.
Výsledky
Výsledky studie:
- Metoda rostoucích regionů nezajišťuje lokalizaci segmentů jak v modelových snímcích, tak v objektových obrázcích a zajišťuje také lokalizaci prvků silniční dopravní infrastruktury.
- Uvažované způsoby rozvodí a normálních řezů v původní podobě nezajišťují plně lokalizaci prezentovaných objektů.
- Metoda normálních řezů zajišťuje lokalizaci objektů jak v modelových obrázcích, tak v obrázcích objektů a také zajišťuje lokalizaci prvků silniční dopravní infrastruktury.
- Metodu pěstování v oblasti a metodu normálního řezu lze doporučit pro použití v automatizovaných systémech vizuální kontroly.
Segmentace znamená identifikaci oblastí, které jsou homogenní podle nějakého kritéria, například jasu. Matematická formulace problému segmentace může být následující.
Nechť je funkce jasu analyzovaného obrazu; X– konečná podmnožina roviny, na které je 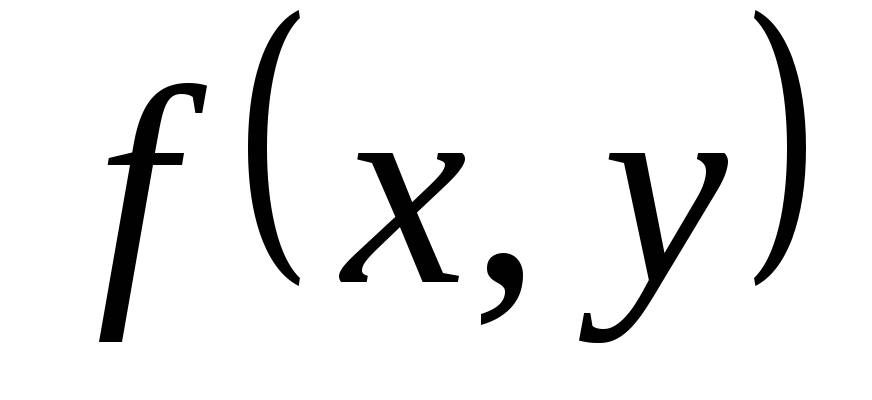 ;
; - oddíl X na K neprázdné připojené podmnožiny
- oddíl X na K neprázdné připojené podmnožiny  LP– predikát definovaný na množině S a přebírání skutečných hodnot tehdy a jen tehdy, když jakýkoli pár bodů z každé podmnožiny
LP– predikát definovaný na množině S a přebírání skutečných hodnot tehdy a jen tehdy, když jakýkoli pár bodů z každé podmnožiny  splňuje kritérium homogenity.
splňuje kritérium homogenity.
Segmentace obrazu  predikátem LP tzv. oddíl
predikátem LP tzv. oddíl 
 , splňující podmínky:
, splňující podmínky:
A) 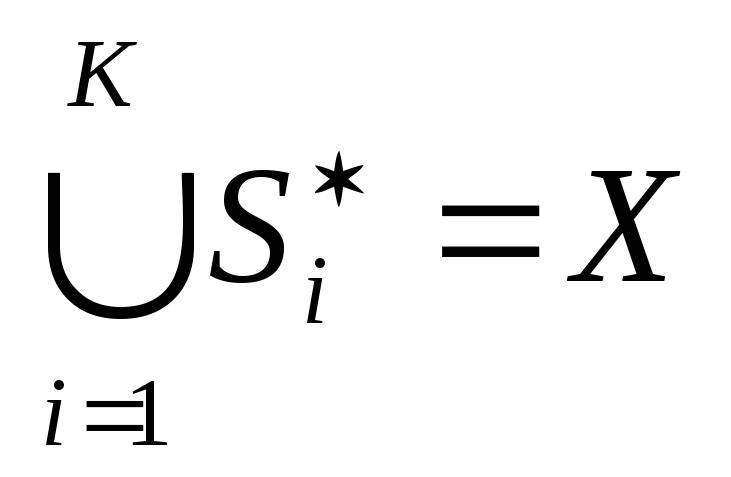 ;
;
b)  ;
;
PROTI) 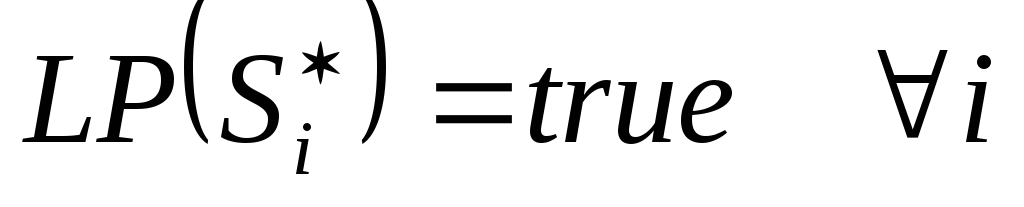 ;
;
d) související oblasti.
Podmínky a) ab) znamenají, že každý bod snímku musí být jednoznačně přiřazen k určité oblasti, c) určuje typ homogenity výsledných oblastí a konečně d) vyjadřuje vlastnost „maximálnosti“ rozdělení. oblasti.
Predikát LP se nazývá predikát homogenity a lze jej zapsat jako:
 (1)
(1)
Kde  -vztah ekvivalence;
-vztah ekvivalence;  - libovolné body z
- libovolné body z  Segmentaci lze tedy považovat za operátor formuláře:
Segmentaci lze tedy považovat za operátor formuláře:
Kde 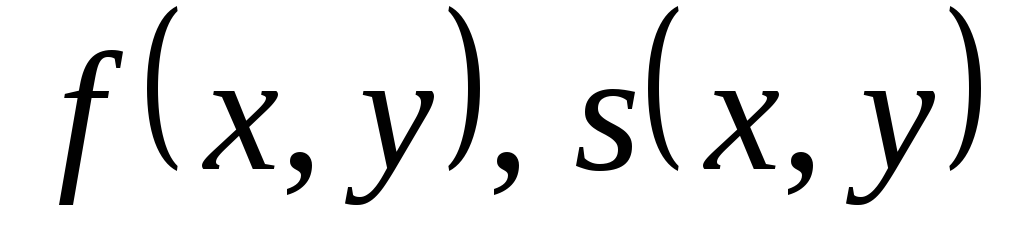 -funkce, které definují původní a segmentované obrázky;
-funkce, které definují původní a segmentované obrázky; 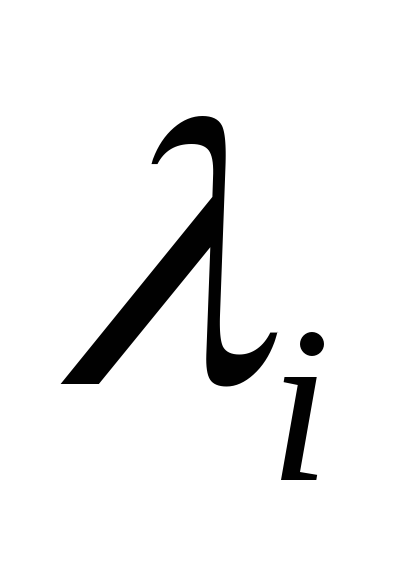 -označení já- regionu.
-označení já- regionu.
Existují dva obecné přístupy k řešení problému segmentace, které jsou založeny na alternativních metodologických koncepcích. První přístup je založen na myšlence „nespojitosti“ ve vlastnostech obrazových bodů při pohybu z jedné oblasti do druhé. Tento přístup redukuje problém segmentace na problém identifikace hranic regionu. Úspěšné řešení posledně jmenovaného umožňuje, obecně řečeno, identifikovat jak samotné regiony, tak jejich hranice. Druhý přístup realizuje touhu vybrat obrazové body, které jsou homogenní ve svých lokálních vlastnostech, a spojit je do oblasti, které bude později přiřazen název nebo sémantický štítek. V literatuře je první přístup tzv segmentace zvýrazněním hranic oblastí a druhý – segmentace vyznačením plošných bodů. Výše uvedená matematická definice problému nám umožňuje charakterizovat tyto přístupy z hlediska predikátu homogenity LP. V prvním případě jako LP musí existovat predikát, který má skutečné hodnoty na hraničních bodech regionů a nepravdivé hodnoty ve vnitřních bodech. Lze si však všimnout významného omezení tohoto přístupu, kterým je rozdělení  je zde dvouprvková sada. V praxi to znamená, že algoritmy detekce hran neumožňují identifikovat různé oblasti různými štítky.
je zde dvouprvková sada. V praxi to znamená, že algoritmy detekce hran neumožňují identifikovat různé oblasti různými štítky.
Pro druhý přístup predikát LP může mít tvar určený vztahem (5.1). Výše uvedené přístupy dávají vzniknout specifickým metodám a algoritmům pro řešení problému segmentace.
Metoda segmentace založená na prahu
Prahování obrazu znamená transformaci jeho jasové funkce operátorem formuláře

Kde s(x,y)– segmentovaný obraz; K –
počet oblastí segmentace;  - popisky segmentovaných oblastí;
- popisky segmentovaných oblastí; 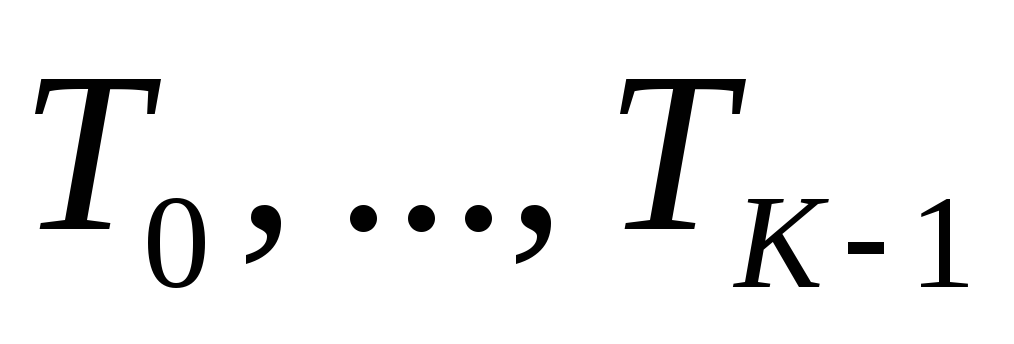 - prahové hodnoty, uspořádané tak, aby
- prahové hodnoty, uspořádané tak, aby 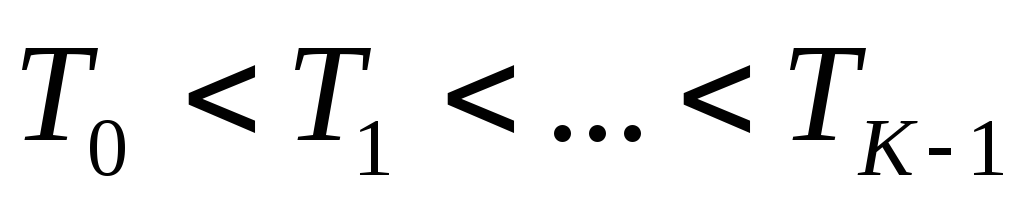 .
.
Ve zvláštním případě, kdy K= 2 prahování zahrnuje použití jediného prahu T. Při přiřazování prahových hodnot se zpravidla používá histogram hodnot funkce jasu obrazu.
Segmentační algoritmus založený na prahování v pseudokódu
Vjezd: mtrIntens – původní matice polotónového obrázku;
l, r – prahové hodnoty podle histogramu
Výstup: mtrIntensNew – segmentovaná obrazová matice
pro i:=0 na l-1 dělat
pro i:=l na r dělat
pro i:=r+1 na 255 dělat
LUT[i] = 255;
pro i:=1 na 100 dělat
pro j:=1 na 210 dělat
mtrIntensNew:=LUT]
Thresholding je asi nejjednodušší segmentační metoda, která vzbudila velkou pozornost odborníků. Metoda je zaměřena na zpracování snímků, jejichž jednotlivé homogenní oblasti se liší průměrným jasem. Nejjednodušším a zároveň často používaným typem segmentace je binární segmentace, kdy existují pouze dva typy homogenních oblastí. V tomto případě se transformace každého bodu zdrojového obrázku na výstupní provádí podle pravidla:
 (7.1)
(7.1)
kde je jediný parametr zpracování zvaný práh. Úrovně výstupního jasu a mohou být libovolné slouží pouze jako značky, pomocí kterých je výsledná mapa označena - přiřazení jejích bodů do tříd, resp. Pokud je výsledný přípravek připraven pro vizuální vnímání, pak jejich hodnoty často odpovídají úrovním černé a bílé. Pokud existují více než dvě třídy, pak prahování musí specifikovat rodinu prahů, které oddělují jasy různých tříd od sebe navzájem.
Ústředním problémem segmentace prahů je stanovení prahů, které by mělo být prováděno automaticky. V současnosti používané metody pro automatické stanovení prahu jsou podrobně popsány v přehledu. Rozmanitost metod je velmi široká, ale jsou založeny především na analýze histogramu původního snímku.
Nechť je histogram původního digitálního obrázku. Předpokládejme, že rozsah jeho jasu je od 0 (úroveň černé) do 255 (úroveň bílé). Původní myšlenka metody prahování histogramu byla založena na předpokladu, že rozdělení pravděpodobnosti pro každou třídu je unimodální (obsahující jeden vrchol) a hraničních bodů oddělujících oblasti různých tříd v obrázku je málo. Tyto předpoklady musí splňovat histogram, který má multimodální charakter. Jednotlivé režimy odpovídají různým třídám a prohlubně, které je oddělují, odpovídají hraničním oblastem, které mají malý počet bodů v nich obsažených. Segmentační prahy jsou určeny polohou prohlubní. Rýže. 7.1 ilustruje výše uvedené ve vztahu k případu dvou tříd. Ve skutečnosti je extrémně vzácné používat takové jednoduché úvahy pro výběr prahové hodnoty. Skutečnost je taková, že skutečné histogramy jsou obvykle velmi zubaté, jak ilustruje výsledek experimentu na obr. 7.2. To slouží jako první překážka pro stanovení minimálního počtu bodů. Druhou překážkou je rozostření hranic mezi homogenními oblastmi snímku, v důsledku čehož se zvyšuje úroveň histogramu v těch jeho částech, které zobrazují hraniční body. To samozřejmě vede ke snížení poklesů v histogramu nebo dokonce k jejich vymizení.

Obr. 7.1 K volbě prahu binární segmentace
Jedním z účinných způsobů, jak tyto obtíže překonat, je stanovení prahové hodnoty na základě tzv. diskriminačního kritéria. Uvažujme tento přístup ve vztahu ke dvěma třídám, protože zobecnění na případ většího počtu tříd není zásadní problém. Domníváme se tedy, že distribuce je konstruována pro obraz obsahující dva typy oblastí a existuje optimální hranice, která je v určitém smyslu nejlépe odděluje. Pro určení optimálního prahu sestrojíme diskriminační funkci , jejíž argument má význam zkušebního prahu. Jeho hodnota, která maximalizuje funkci, je optimální práh. Uvažujme konstrukci diskriminační funkce.
Nechť je hypotetická prahová hodnota, která rozděluje rozdělení do dvou tříd. V tomto případě většinou nehraje velkou roli, ke které z tříd budou obrazové body s jasem přiřazeny, a to z důvodu malého počtu hraničních bodů oddělujících oblasti různých tříd. Pravděpodobnost, že náhodně vybraný bod snímku patří do třídy, je rovna
 (7.2)
(7.2)
Podobně pravděpodobnost její příslušnosti k nějaké třídě je určena vzorcem
 (7.3)
(7.3)
Navíc díky normalizaci rozdělení pravděpodobnosti platí rovnost
Dále předpokládáme , že distribuční oblast , ohraničená bodem , popisuje část obrazu , která patří , a oblast , ![]() - patřící k . To nám umožňuje zavést dvě distribuce a , odpovídající a , je sestavit z distribuce pomocí výrazů:
- patřící k . To nám umožňuje zavést dvě distribuce a , odpovídající a , je sestavit z distribuce pomocí výrazů:
![]()
![]()
![]()
Zde dělení pravděpodobností zajišťuje normalizaci zavedených podmíněných rozdělení.
Pro takto vytvořená rozdělení pravděpodobnosti lze nalézt momenty. Výrazy pro matematická očekávání a mají tvar
 (7.4)
(7.4)
Kde  - nestandardizované matematické očekávání pro ,
- nestandardizované matematické očekávání pro ,  - matematické očekávání pro celý rámec.
- matematické očekávání pro celý rámec.
Podobně je dán denní rozptyl celého rámce
 (7.6)
(7.6)
Abychom zkonstruovali diskriminační funkci, zavedeme navíc další energetický parametr zvaný mezitřídní disperze:
Bezrozměrná diskriminační funkce je dána
![]() (7.8)
(7.8)
Optimální práh, jak je uvedeno výše, se považuje za splňující požadavek
![]() (7.9)
(7.9)
Vysvětleme si význam kritéria (7.9). Jmenovatel ve výrazu (7.8) je rozptyl celého snímku, a proto nezávisí na hodnotě zkušebního prahu, který rozděluje obraz do tříd. Proto se maximální bod vyjádření (7.8) shoduje s maximálním bodem čitatele, tzn. je určena povahou závislosti mezitřídního rozptylu (7.7) na prahu . Protože má tendenci k nule, pravděpodobnost, jak vyplývá z (7.2), také směřuje k nule. Vzhledem k tomu, že celý obrázek patří do třídy, existuje tendence. V důsledku toho se oba členy v (7.7) stanou nulou. Totéž je pozorováno u druhé extrémní hodnoty prahu = 255. Vzhledem k nezápornosti veličin obsažených v (7.7) a (7.9) a rovnosti funkce k nule na okrajích definičního oboru je uvnitř tohoto definičního oboru maximum, jehož úsečka je brána jako optimální práh. Stojí za zmínku kvalitativní charakter těchto úvah. Podrobnější studie například ukazují, že při zpracování některých obrázků má diskriminační funkce několik maxim, i když jsou v obrázku pouze dvě třídy. To se projevuje zejména tehdy, když jsou celkové plochy pozemků obsazené třídami a výrazně odlišné. Proto je úloha v obecném případě poněkud komplikovaná nutností určit absolutní maximum funkce.
Z výpočtového hlediska je pro provedení algoritmu nutné najít matematické očekávání a rozptyl pro celý obraz. Dále se pro každou hodnotu určí pravděpodobnosti pomocí (7.2) a (7.3) (nebo normalizačních podmínek), dále matematickými očekáváními tříd a pomocí vztahů (7.4), (7.5). Takto zjištěné veličiny umožňují určit hodnotu.
Množství výpočtů lze snížit provedením některých transformací vzorce (7.7) pro mezitřídní rozptyl. Pomocí vzorců (7.2)...(7.5) je snadné získat vztah pro matematická očekávání:
![]() (7.11)
(7.11)
Vyjádřením množství z (7.10) a jeho dosazením do (7.11) nakonec zjistíme:
 (7.12)
(7.12)
Vztah (7.12), používaný jako pracovní, zahrnuje pouze dvě veličiny - pravděpodobnost a nenormalizované matematické očekávání, což výrazně snižuje množství výpočtů při automatickém nalezení optimálního prahu.
Na Obr. Obrázek 7.2 ukazuje experimentální výsledky ilustrující popsanou metodu automatické binární segmentace. Obrázek 7.2, a ukazuje letecký snímek řezu „Pole“ zemským povrchem a obrázek 7.2, b – výsledek jeho binární segmentace, provedené na základě automatického stanovení prahu pomocí diskriminační metody. Distribuční histogram původního snímku je na obr. 7.2, c a diskriminační funkce vypočítaná z výsledného histogramu je na obr. 7.2, d. Silná nepravidelnost histogramu, která generuje velké množství minim, vylučuje možnost přímého stanovení jediného informačního minima oddělujícího třídy od sebe. Funkce je výrazně plynulejší a navíc v tomto případě unimodální, díky čemuž je určení prahu velmi jednoduchý úkol. Optimální práh, při kterém se získá segmentovaný obraz, je =100. Výsledky ukazují, že popsaná metoda pro nalezení prahu, která je vývojem histogramového přístupu, má silný vyhlazovací efekt ve vztahu k drsnosti samotného histogramu.
Dotkneme se problematiky prahové segmentace nestacionárních obrazů. Pokud se v rámci snímku změní průměrný jas, měly by se změnit i prahové hodnoty segmentace. V těchto případech se často uchýlí k rozdělení snímku do samostatných oblastí, ve kterých lze zanedbat změny průměrného jasu. To umožňuje aplikovat principy prahování v rámci jednotlivých oblastí, které jsou vhodné pro práci se stacionárními obrazy. V tomto případě zpracovaný snímek zobrazuje oblasti, na které je původní snímek rozdělen, a hranice mezi oblastmi jsou jasně viditelné. To je podstatná nevýhoda metody.
Pracnější, ale také efektivnější postup využívá posuvné okno, ve kterém se každá nová poloha pracovního prostoru liší od předchozí pouze o jeden krok po řádku nebo sloupci. Optimální práh nalezený v každém kroku se vztahuje k centrálnímu bodu aktuální oblasti. U této metody se tedy práh mění v každém bodě snímku a tyto změny mají charakter srovnatelný s povahou nestacionárního charakteru samotného obrazu. Proces zpracování se samozřejmě výrazně zkomplikuje.
Kompromisem je postup, při kterém se místo posuvného okna s jedním krokem používá „skákací“ okno, které se v každé fázi zpracování pohybuje o několik kroků. V „zmeškaných“ bodech snímku lze prahovou hodnotu určit pomocí interpolace (často se používá nejjednodušší lineární interpolace) na základě jejích hodnot nalezených v nejbližších bodech.




Obr. 7.2 Příklad binární segmentace s automatickým stanovením prahu
Posouzení účinnosti prahové segmentace na Obr. 7.2, b, je třeba poznamenat, že tato metoda umožňuje získat určitou představu o povaze homogenních oblastí, které tvoří pozorovaný snímek. Zřejmá je přitom jeho zásadní nedokonalost způsobená jednobodovostí přijímaných rozhodnutí. V následujících částech se proto budeme věnovat statistickým metodám, které nám umožňují zohlednit při segmentaci geometrické vlastnosti oblastí – velikost, konfiguraci atd. Poznamenejme hned, že příslušné geometrické charakteristiky jsou specifikovány vlastními pravděpodobnostními modely a nejčastěji v implicitní podobě.



