Ввоз средств шифрования в Россию: разоблачая мифы. Единая ли процедура ввоза для разных средств шифровальных средств
Геометрические и содержательные характеристики полей могут быть как абсолютно независимыми, так и взаимосвязанными. Например, в приходном ордере рядом с полями "количество" и "цена" находится поле "сумма".
Документы, которые подлежат сканированию, могут быть объединены в группы по нескольким признакам. По способу нанесения информации можно выделить документы, в которых используются метки, печатный или рукописный тексты. Так, например, "Избирательные бюллетени" используют меточный способ, в то время как "Прайс-листы" – печатный, а первичные бухгалтерские документы – в основном рукописный.
Выполнение описания настроек системы на конкретную форму документа предполагает также выполнение разработки настройки на модель ввода документа в информационную базу или в электронный архив и составление настройки соответствия полей формы документа и полей индексации для ввода в информационную базу или архив. Построение этих настроек опирается на существование трех подходов к вводу данных в базу:
Ввод ключевых слов. В этом случае одно или несколько ключевых слов будет использоваться в качестве индексов для конкретного изображения. В дальнейшем возможен быстрый доступ к изображению документа с применением введенных ключевых слов - индексов.
Ввод всего текста документа. Производится ввод всех слов документа и после этого возможно осуществление полнотекстового поиска изображения документа с помощью полнотекстового индекса, составляемого для этого документа. Этот метод может применяться при необходимости получения текстового варианта документа.
Формоориентированный ввод данных. Данный метод используется для полной замены ручного ввода данных в компьютерные системы и в основном применяется для ввода данных из форм (стандартных, однотипных документов). В этом случае атрибуты документа будут использованы для составления индекса документа для его поиска и хранения в базе или архиве.
Основной этап автоматизированного ввода бумажных документов включает в себя выполнение таких операций как:
Сканирование;
Контроль качества отсканированных изображений и повторное сканирование;
Предварительная обработка текста;
Основная обработка текста документа;
Контроль качества распознавания и редактирование;
Сканирование – это очень ответственная операция, и, следовательно, к выбору конкретной модели сканера необходимо подходить достаточно ответственно. При выборе следует учитывать следующие факторы: размеры документов, их состояние, является ли документ односторонним или двухсторонним, производительность сканеров, необходимое разрешение изображения, надежность получаемых изображений и другие.
В настоящее время на рынке технических средств предлагается достаточно большое количество различных моделей сканеров, которые можно классифицировать по производительности на следующие виды (см табл. 5.1):
Персональные;
Настольные;
Высокопроизводительные потоковые.
По качеству сканирования, зависящего от разрешающей способности, их можно разделить на следующие группы:
С низкой разрешающей способностью (200–400 точек на дюйм);
Со средней разрешающей способностью (600–800 точек/дюйм);
С высокой разрешающей способностью (1600–2800 точек/дюйм);
Специального назначения.
Ввод документов предъявляет достаточно низкие требования к качеству сканирования, обычно бывает достаточно разрешения 200-300 точек/дюйм. Профессиональные издательские сканеры имеют разрешение порядка точек/дюйм и даже персональные сканеры имеют разрешение порядка 600-800 точек/дюйм. Единственная отличительная особенность - автоматическая подача страниц документов и высокая скорость сканирования (от 10 до 200 листов формата А4 в минуту). Данные высокоскоростные сканеры предназначены для ввода разброшюрованных документов.
Для ввода ветхих документов применяют сканеры с вакуумным прижимом документов, которые предъявляют весьма низкие требования к документу и обрабатывают его в щадящем режиме. В совсем редких случаях, когда документ настолько стар, что его нельзя помещать даже в планшетный сканер, применяют сканеры специального назначения. Такие сканеры позволяют сканировать не полностью раскрытые книги и документы плохого качества. Скорость ввода у таких устройств - 0,25-3 страницы в минуту.
Обработка данных, содержащихся в документе, предполагает выполнение следующих основных операций:
Предварительная обработка изображений;
Основная обработка изображений документа.
Предварительная обработка изображения документов используется для улучшения полученных изображений и необходима по следующим причинам:
Улучшение читаемости изображения. Обработанные изображения более понятны при визуальном просмотре.
Повышение точности распознавания. Применение специальных методов улучшения изображения может значительно повысить точность оптического распознавания символов.
Уменьшение размера изображения. Размер файлов обработанных изображений может быть меньше первоначального размера на 80%. Под уменьшением размера понимается как простое сжатие файла, так и удаление ненужной информации.
Предварительная обработка изображения документов предусматривает использование следующих методов: очищение изображения применяется для снятия с изображений отдельных элементов (например, точки, пятна); снятие фона и выделений (например, с ценных бумаг); восстановление букв и символов – если они оказываются пересеченными элементами формы, например, линией, (для последующего распознавания символа необходимо удалить линию, таким образом, чтобы буква не пострадала); вращение изображения на произвольный угол; масштабирование изображения; регулирование уровня серого; компрессия и декомпрессия изображения.
Процесс основной обработки документов предусматривают выполнение операций:
Нахождения полей (сегментация документа);
Распознавание текста документов.
Они могут быть выполнены последовательно и независимо, если поля полностью определены своими визуальными характеристиками. Такая ситуация характерна для машиночитаемых форм и документов с явными разделителями полей в виде линий или больших промежутков.
Распознавание документа, анализ содержания документа и извлечение данных может осуществляются с помощью следующих систем распознавания текстов, отличающихся по стоимости, качеству и скорости работы:
OCR (Optical Character Recognition) – технология оптического распознавания печатных символов, т. е. перевода сканированного изображения печатных символов в их текстовое представление;
ICR (Intelligent Character Recognition) – распознавание раздельных печатных символов, написанных от руки;
OMR (Optical Mark Recognition) – распознавание отметок (обычно перечеркнутые крест-накрест либо галочками квадраты или круги);
Стилизованные цифры – распознавание рукописных цифр, написанных от руки по шаблону, как на почтовых конвертах;
Существует несколько подходов к реализации технологий ввода рукописных символов:
Распознавание on-line осуществляется в тот момент, когда человек пишет специальным пером на сенсорном экране, воспринимающем дополнительную информацию о траектории движения руки, наклоне пера, силе нажима и т. д. Применяется в основном в персональных электронных записных книжках типа 3Com PalmPilot для рукописного ввода числовых и символьных данных.
Распознавание off-line – распознавание произвольного рукописного текста, введенного в компьютер через сканер.
Распознавание рукопечатных символов является подмножеством технологии распознавания off-line. Этот метод применяется, как правило, для ввода стандартных форм. Распознавание рукописного текста значительно сложнее, чем печатного, поскольку если в последнем случае мы имеем дело с ограниченным числом вариаций изображений шрифтов (шаблонов), то в рукописном варианте число шаблонов неизмеримо больше.
Для OCR- систем в основном используются три технологии распознавания напечатанного текста:
Матричная (Matrix - based),
Описательная (основана на описании правил построения символов),
Нейронная (основана на использовании нейронных сетей).
Строгое соблюдение стандарта внешнего вида формы существенно повышает точность распознавания полей документа.
Контроль распознанных данных является следующей операцией, реализуемой системой ввода.
Системы автоматического распознавания обычно вместе с результатом возвращают так называемую «степень уверенности». Для повышения надежности данных после распознавания применяются определенные пользователем автоматизированные методы проверки данных (например, можно проверить, имеется ли распознанная информация в базе данных , и если нет, то пометить поле как некорректное). Для повышения надежности данных используются дополнительные механизмы, такие как применение словарей и таблиц, определяемых пользователем. Помимо этого, системы включают специальные встроенные средства для определения специальных процедур проверки для каждого поля документа.
Если данные после распознавания помечены как не корректные, то они автоматически направляются на ручное редактирование. Во время редактирования оператор видит реальное изображение нераспознанного поля и имеет возможность откорректировать его. После ввода оператором новых данных снова применяются правила проверки данных, т. е. на всех этапах ввода, как автоматического, так и ручного, осуществляется проверка данных в соответствии с правилами, определенными пользователем.
Индексирование и загрузка данных. Заключительная операция процесса - это экспорт изображений документов и сопутствующих данных в конкретную систему документооборота или базу данных и индексирование. Основными требованиями к экспорту являются поддержка различных форматов данных и его скорость.
После того, как документ распознан, он поступает в базу данных или в систему управления документами, где проводится его индексирование. В отличие от обычной системы распознавания система ввода стандартных форм использует формальное описание исходной формы документа, описание модели ввода и модели соответствия полей ввода и индексирования. Это позволяет автоматически производить индексирование документов и загружать информацию в поля базы данных или архив без участия оператора.
В зависимости от конкретной задачи и типа документа, он может быть загружен в полнотекстовый модуль или информация из него извлеченная должна будет попасть в систему атрибутивной индексации (например, значения из полей формы попадают в карточку документа). При этом, может быть сохранено изображение документа.
5.2 Требования, предъявляемые к СМВ. Характеристика систем
Основной фактор при оценке эффективности систем распознавания заключается в стоимости исправления ошибок при распознавании, а не в точности и скорости системы. В некоторых случаях затраты на исправление ошибок при распознавании могут перекрыть все плюсы автоматизации и сделать ручной ввод по изображению более эффективным. При разработке и использовании СМВ проектировщику требуется выполнить также большой объем работ по интеграции этой системы ввода в действующую или разрабатываемую информационную систему . На производительность системы очень большое влияние оказывают используемая технология ввода, ее настройка на текущую задачу и вид документов. Здесь нужно учитывать состав оборудования, программное обеспечение и совместимость формата распознанной информации с уже существующими системами.
Существует множество компаний, которые предлагают решения или компоненты систем обработки форм. Решение о внедрении системы обработки форм, а также выбор того или иного приложения должны производиться с учетом в первую очередь следующих требований:
Тип обрабатываемых документов и вид содержащихся в них данных;
Точность распознавания;
Наличие эффективной системы редактирования;
Настраиваемость системы на требования конкретного заказчика и способность изменяться согласно меняющимся внешним условиям без программирования;
Наличие поддержки сканеров различных типов, а также разного рода плат обработки изображений документов;
Наличие редактора форм, настраивающего систему на новые формы или изменения старой формы, на которую система была предварительно ориентирована;
Наличие редактора схем обработки документов, открытого интерфейса подключения различных модулей распознавания (в зависимости от типа формы можно для повышения качества распознавания подключать тот или иной модуль, который наиболее подходит для данного типа формы);
Наличие редактора схем экспорта в базу данных (данные, которые извлекаются при обработке формы, должны быть переданы или в базу данных для хранения, или в другие бизнес-приложения для обработки).
Помимо этого к выбору ПО для СМВ можно предъявить совокупность общих требований:
Открытость. Система должна позволять включать в себя различные технологии и программные продукты в зависимости от конкретного приложения, даже если эти продукты поставляются другими фирмами. Необходима возможность интеграции с различными workflow-системами и с системами документооборота.
Возможность настройки. Пользовательский интерфейс должен быть настраиваемым для достижения максимальной эффективности работы операторов.
Масштабируемость. Необходимо иметь возможность добавлять и уменьшать системные ресурсы при различных уровнях загрузки системы.
Возможность администрирования. Пользователь должен иметь возможность гибкого управления системой. Необходимо иметь возможность контролировать используемые ресурсы и инструментарий для получения различных видов отчетов.
Рассмотрим в качестве примера две системы класса СМВ - Cognitive Forms компании Cognitive Technologies и FineReader.
Cognitive Forms – российская система промышленного (иногда говорят поточного) ввода стандартных форм документов, которая работает под управлением операционных систем Windows 95/NT и MacOS. Система принадлежит к классу OCR/ICR/OMR и позволяет вводить в базы данных и информационные системы формы с печатным, рукописным заполнением и отметками (checkbox).
Cognitive Forms предназначена для автоматизированного ввода в информационные системы и базы данных произвольных, одно - и многостраничных форм документов, соответствующих определенным требованиям к оформлению и заполнению и подготовленных на лазерных, струйных и матричных принтерах или на стандартных бланках с использованием пишущих машинок.
Эта система позволяет осуществлять распределенную поточную обработку (сканирование, распознавание, редактирование и контроль) в сети с производительностью распознавания достраниц А4 в смену на одном компьютере и осуществлением автоматического контроля результатов распознавания. Экспорт данных может осуществляться в базы данных, банковские системы типа «Операционный день» и системы создания электронных архивов и автоматизации документооборота.
Внедрение системы позволяет обеспечить ускорение ввода стандартных форм документов в 5–10 раз по сравнению с ручным вводом.
Сканированные образы могут быть сохранены в электронном архиве банка для ведения истории делопроизводства организации.
Cognitive Forms состоит из трех основных модулей:
Cognitive FormDesigner отвечает за проектирование описания формы документа для программ распознавания и редактирования.
Cognitive FormReader обеспечивает автоматическое распознавание потока стандартных форм, поступающих со сканера. В автоматическом режиме осуществляет поточное распознавание форм по заданному описанию и контекстную проверку результатов.
Cognitive FormEditor предназначен для операторского контроля распознанных форм и сохранения информации из введенных форм в записи базы данных и позволяет оператору визуально контролировать и редактировать распознанные поля форм.
Cognitive Forms дает возможность осуществлять распределенную, в рамках локальной сети, обработку вводимых форм и добиться эффективного доступа к данным в режиме реального времени. Например, на Pentium II-233 время распознавания системой Cognitive Forms одного бланка составляет около 2 сек. Для промышленного ввода применяются высокопроизводительные сканеры: Kodak, Bell+Howell, BancTec, Fujitsu и др., а также сетевые устройства (Hewlett-Packard). Производительность некоторых моделей достигает сотен страниц в минуту.
Эффективность применения системы ввода бумажных документов в ЭИС основана, в первую очередь, на значительном сокращении участия человека во вводе данных. Как следствие, можно наблюдать уменьшение времени ввода документов и количества ошибок. Для организаций, обрабатывающих большие потоки форм (центральные налоговые и почтовые ведомства , статистические организации, центры авторизации по расчетам за кредитные карты), использование описанных технологий позволит решить проблемы эффективности обработки сотен тысяч и даже миллионов форм в сжатые сроки.
В основу системы FineReader, разработанной компанией ABBYY, положены три принципа распознавания, сформулированные при наблюдении за поведением животных и человека: Целостность, Целенаправленность и Адаптивность, позволившие получить решение, использующее в своей основе принципы распознавания, характерные для живых систем, - технология Целостностного Целенаправленного Адаптивного распознавания (IPA-технология).
Целостность. Объект описывается как целое с помощью значимых элементов и отношений между ними. Объект признается объектом данного класса только при наличии всех элементов описания и нужных отношений между ними.
Целенаправленность. Распознавание строится как процесс выдвижения и целенаправленной проверки гипотез. Традиционный подход, состоящий в интерпретации того, что наблюдается на изображении, заменятся подходом, состоящем в целенаправленном поиске того, что ожидается на изображении.
Адаптивность. Способность системы к самообучению, т. е. сначала система FineReader выдвигает гипотезу об объекте распознавания (символе, части символа или нескольким склеенным символам), а затем подтверждает или опровергает ее, пытаясь последовательно обнаружить все структурные элементы в нужных отношениях. В качестве структурных используются элементы, значимые для восприятия объекта с точки зрения человека, - отрезки, дуги, кольца и точки.
Следуя принципу адаптивности программа самостоятельно "настраивается" на новый шрифт (или на новый почерк), используя положительный опыт, полученный на первых уверенно распознанных символах.
Целенаправленный поиск и учет контекста позволяют распознавать разорванные и искаженные изображения, делая систему устойчивой к дефектам печати.
Эти принципы используются как при распознавании отдельных символов, так и при анализе раскладки страницы (выделении участков текста, картинок, таблиц). Благодаря использованию IPA-технологии FineReader демонстрирует высокое качество распознавания при малой чувствительности к дефектам печати, а безупречный анализ раскладки страницы отмечен в большинстве сравнительных тестов. Компания ABBYY получила патент на использование IPA-технологии. Система FineReader имеет два варианта реализации: FineReader Office и FineReader от Pro, которые постоянно развиваются.
Система FineReader имеет следующие входные форматы файлов: BMP: черно-белые, серые, цветные; PCX, DCX: черно-белые, серые, цветные; JPEG: серые, цветные; PNG: черно-белые, серые, цветные; TIFF: черно-белые, серые, цветные, многостраничные.
При получении документов применяетя несколько методов сжатия текста: несжатый, CCITT Group 3, CCITT Group 3 FAX (2D), CCITT Group 4, PackBits, JPEG.
Система FineReader сохраняет результат распознавания в следующих форматах: Microsoft Word 95, Microsoft Excel 95, Microsoft Word 97, Microsoft Excel 97, Microsoft Word 2000, Microsoft Excel 2000, Text, Rich Text Format, Unicode Text, DBF, HTML, CSV, Unicode HTML, PDF.
Требования к системе: операционная система Microsoft Windows 2000, Windows NT Workstation 4.0 с пакетом обновления 3 (SP3) или выше, или Windows 95/98 .
Система поддерживает работу 19 типов сканеров, включая Acer, Samsung , Mitsubishi , Scanpaq, Canon, Syscan, E-Lux, Nikon, Silitek, Epson, Storm, Fujitsu, Packard Bell, HP, IBM, Xerox, Kodak и др. и более 100 моделей 100% TWAIN-совместимых сканеров других фирм.
Тема 6. Автоматизация хранения электронных
документов
6.1 Понятие информационно-поисковой системы (ИПС). Состав компонент и технология работы с ИПС
В работе современных предприятий важную роль играют его информационные ресурсы, под которыми можно понимать проектную документацию , переписку с партнерами, внутренние приказы и распоряжения, финансовые данные и другие документы, которые служат основой для принятия новых решений и используются в процессах управления предприятием. И если для хранения структурированных данных можно применять специализированные информационные системы (типа бухгалтерской или торговой системы или системы планового отдела), основанные, на использовании СУБД, то для неструктурированных данных нужны системы общего назначения - электронные архивы, работающие на принципах информационно-поисковой системы.
Информационно-поисковая система (ИПС) - это система, предназначенная для хранения и поиска документов с текстовой, графической, табличной информацией по атрибутам, ключевым словам документа и содержанию в какой-либо предметной области.
Выделяют ИПС двух типов: фактографические и документографические системы. ИПС фактографического типа предназначены для хранения и поиска фактов, показателей, характеристик каких-либо объектов или процессов (например, сведения о работниках, о предприятиях, акционерах и т. д.). Документографические ИПС отличаются тем, что объектом хранения и поиска в этих системах служат документы, отчеты, рефераты, обзоры, журналы, книги и т. д. Сценарий поиска документа при помощи ИПС обычно сводится к вводу запроса на поиск, состоящего из одного или нескольких слов, после чего предъявляется список имен найденных документов. Пользователь может открыть любой из найденных документов и если поисковая система позволяет, вхождения искомых слов в документе выделяются - «подсвечиваются».
Можно выделить следующие особенности организации и функционирования документографической ИПС, отличающие ее от систем управления базами структурированных данных:
Документы могут храниться на бумаге, микрографических носителях или существовать в электронных форматах. Микрографические форматы включают микрофильмы, микрофиши, слайды и другие микроформы, производимые разнообразными документными камерами. Электронные форматы еще многочисленнее, они включают документы, подготовленные в текстовых процессорах, системах электронной почты и других компьютерных программах, оцифрованные изображения прошедших сканирование документов и проч. При этом предполагается обязательное хранение как электронных копий документов, так и их бумажных оригиналов.
Если документы занимают большой объем и полные электронные копии выдавать на просмотр или хранить не возможно, то для таких документов создают и хранят электронные адреса их хранения.
Поиск осуществляется нахождением документа по двум принципам: по атрибутам документа - дате создания, размеру, автору и пр. и по его содержанию (тексту). Обычно поиск по содержанию документа выполняется двумя способами: по ключевым словам и по всему тексту, который называют полнотекстовым, подчеркивая тем самым, что для поиска используется весь текст документа, а не только его реквизиты. –
Для поиска документов создают и хранят их поисковые образы. Поисковый образ документа (ПОД) - совокупность кодов ведущих ключевых слов (дескрипторов), которые описывают смысл, содержание документа.
Ключевые слова и их коды хранятся в специальном словаре - тезаурусе.
Для того чтобы осуществлять поиск документов, нужно создать информационно-поисковый язык (ИПЯ), в состав которого входит тезаурус и грамматика языка, т. е. совокупность правил задания множества высказываний на множестве ключевых слов.
Чтобы отыскать документ, нужно создать с помощью ИПЯ поисковый образ запроса (ПОЗ), который представляет собой совокупность закодированных ключевых слов, описывающие те документы, которые нужно найти. Схема взаимодействия компонент ИПС представлена на рис. 6.1.
файл-сервер", поэтому для решения поставленных задач и проблем наиболее перспективным является выбор варианта архитектуры интегрированных систем управления документами - "клиент-сервер", который существенно увеличивают эффективность работы пользователей, поскольку системы данного класса обеспечивают не только быстрый поиск необходимых пользователям документов, но и помогают им организовывать и совместно использовать информацию. И, что особенно важно, СУД создают удобную для пользователя структуру представления всей информации, хранящейся в сети. Создатель документа будет избавлен от необходимости каждый раз придумывать, где его хранить, как защищать и какие права на него предоставлять коллегам.
Системы управления документами должны решать проблему с управлением большими объемами документов на следующих принципах:
1. Управление должно осуществляться над электронными документами, созданными в разных прикладных программах для персональных компьютеров, таких как: текстовые процессоры, электронные таблицы, электронная почта.
Семинар
Проектирование систем управления документами
Понятие информационно-поисковой системы (ИПС).
Состав компонент и технология работы с ИПС.
В работе современных предприятий важную роль играют его информационные ресурсы, под которыми можно понимать проектную документацию, переписку с партнерами, внутренние приказы и распоряжения, финансовые данные и другие документы, которые служат основой для принятия новых решений и используются в процессах управления предприятием. И если для хранения структурированных данных можно применять специализированные информационные системы (типа бухгалтерской или торговой системы или системы планового отдела), основанные, на использовании СУБД, то для неструктурированных данных нужны системы общего назначения – электронные архивы, работающие на принципах информационно-поисковой системы.
Информационно-поисковая система (ИПС) – это система, предназначенная для хранения и поиска документов с текстовой, графической, табличной информацией по атрибутам, ключевым словам документа и содержанию в какой-либо предметной области. Выделяют ИПС двух типов: фактографические и документографические системы. ИПС фактографического типа предназначены для хранения и поиска фактов, показателей, характеристик каких-либо объектов или процессов (например, сведения о работниках, о предприятиях, акционерах и т.д.). Документографические ИПС отличаются тем, что объектом хранения и поиска в этих системах служат документы, отчеты, рефераты, обзоры, журналы, книги и т.д. Сценарий поиска документа при помощи ИПС обычно сводится к вводу запроса на поиск, состоящего из одного или нескольких слов, после чего предъявляется список имен найденных документов. Пользователь может открыть любой из найденных документов и если поисковая система позволяет, вхождения искомых слов в документе выделяются - «подсвечиваются». Можно выделить следующие особенности организации и
функционирования документографической ИПС, отличающие ее от систем управления базами структурированных данных: – Документы могут храниться на бумаге, микрографических носителях или существовать в электронных форматах. Микрографические форматы включают микрофильмы, микрофиши, слайды и другие микроформы, производимые разнообразными документными камерами. Электронные форматы еще многочисленнее, они включают документы, подготовленные в текстовых процессорах, системах электронной почты и других компьютерных программах, оцифрованные изображения прошедших сканирование документов и проч. При этом предполагается обязательное хранение как электронных копий документов, так и их бумажных оригиналов.
Если документы занимают большой объем и полные электронные копии выдавать на просмотр или хранить не возможно, то для таких документов создают и хранят электронные адреса их хранения.
Поиск осуществляется нахождением документа по двум принципам: по
атрибутам документа – дате создания, размеру, автору и пр. и по его содержанию (тексту). Обычно поиск по содержанию документа выполняется двумя способами: по ключевым словам и по всему тексту, который называют полнотекстовым, подчеркивая тем самым, что для поиска используется весь текст документа, а не только его реквизиты.
Для поиска документов создают и хранят их поисковые образы. Поисковый образ документа (ПОД) – совокупность кодов ведущих ключевых слов (дескрипторов), которые описывают смысл, содержание документа.
Ключевые слова и их коды хранятся в специальном словаре – тезаурусе .
Для того, чтобы осуществлять поиск документов, нужно создать информационно-поисковый язык (ИПЯ), в состав которого входит тезаурус и грамматика языка, т.е. совокупность правил задания множества высказываний на множестве ключевых слов.
Чтобы отыскать документ, нужно создать с помощью ИПЯ поисковый образ запроса (ПОЗ) , который представляет собой совокупность закодированных ключевых слов, описывающие те документы, которые нужно найти.
Схема взаимодействия компонент ИПС представлена на рис. 1.
Рис. 1. Схема взаимодействия компонент ИПС
ИПС состоит из следующих обеспечивающих подсистем:
Лингвистическое обеспечение, включающее в свой состав информационно-поисковый язык;
Техническое обеспечение системы, включающее ЭВМ и устройства создания, хранения, чтения и размножения копий на бумажных носителях, в микроформатах и в электронной форме;
Информационное обеспечение, состоящее из БД документов (БД Док.), адресов (БД Адр.) и БД поисковых образов документов (БД ПОД) и списков дескрипторов и их кодов - тезауруса;
Программное обеспечение ИПС предназначено для автоматизации следующих основных функций, которые должна выполнять эта система:
Составления, кодирования и загрузки базы данных ПОД;
Загрузки БД документов и их адресов хранения;
Составления, кодирования ПОЗ;
Выполнение операции поиска и выдачи ответа на запрос в виде документа или адресов хранения документов на экран ЭВМ, на бумагу, в файл;
Актуализация баз данных ПОД, документов и адресов;
Актуализация тезауруса;
Выдача справок.
Рассмотрим основные понятия, употребляемые в сфере поиска документов.
Релевантность - степень соответствия найденного документа запросу. Найденный по запросу документ может иметь отношение к запросу, т. е. содержать нужную (искомую) информацию, а может и не иметь никакого отношения. В первом случае документ называется релевантным (по-английски relevant - «относящийся к делу» ), во втором - нерелевантным , или шумовым. Как правило, в любой поисковой системе по запросу выдается несколько (чаще много) найденных документов. Многие из них могут повествовать не о том. И наоборот, некоторые важные, релевантные, документы могут быть пропущены при поиске. Ясно, что количество тех и других определяет качество поиска, которое можно определить достаточно точно. Основными понятиями в мире поисковых средств являются идеи точности и полноты поиска.
Точность поиска (Т) определяется тем, какая часть информации, выданная в ответ на запрос, является релевантной, т.е. относящейся к этому запросу и является параметром, показывающим, какова доля релевантных документов в общем числе найденных. Этот показатель рассчитывается по формуле:

Если, например, все выданные по запросу документы относятся к делу, то точность равна 100%; если, напротив, все документы шумовые, то точность поиска равна нулю.
Полнота поиска (П) - дополнительный параметр, показывающий, какова доля (или процент) найденных релевантных документов в общем количестве релевантных документов, т.е. характеризуется соотношением между всей релевантной информацией, имеющейся в базе, и той ее частью, которая включена в ответ и рассчитывается по формуле:

Если в области поиска на самом деле имеется 100 документов, содержащих нужную информацию, а по запросу найдено из них всего 30, то полнота поиска равна 30%. Кроме этого при оценке поисковых систем учитывается, с какими типами данных может работать та или иная система, в какой форме представляются результаты поиска и какой уровень подготовки пользователей необходим для работы в этой системе. Следует отметить, что точность поиска и его полнота зависят не только от свойств поисковой системы, но и от правильности построения конкретного запроса, а также от субъективного представления пользователя о том, какая нужна ему информация. Если стоит проблема оценки нескольких систем и выбора наиболее эффективной, можно вычислить средние значения полноты и точности рассматриваемых конкретных систем, протестировав их на эталонной базе документов.
Индексация документов (т.е. составление ПОД), которая означает предварительную подготовку текстов для поиска и применяется главным образом для ускорения поиска; как правило, текстовые базы данных, предназначенные для многократного поиска, обрабатывают заранее, составляя так называемый индекс (ПОД) . При индексации поисковая система составляет списки слов, встречающихся в тексте, и приписывает каждому слову его код - координаты в тексте (чаще всего номер документа и номер слова в документе). При поиске слово ищется в индексе, и по найденным координатам выдаются нужные документы. Если слов в запросе несколько, над их координатами производится операция пересечения. В том случае, если множество документов пополняется, приходится пополнять и индекс.
Единица поиска - это квант текста, в пределах которого в данной поисковой системе осуществляется поиск, от величины которого зависит показатель точности поиска, величина шума и время ответа на запрос. Единицей поиска может быть документ, предложение или абзац. В технологии использования ИПС можно выделить три группы операций:
Операции, связанные с получением поисковых образов документов (ПОД), описывающих содержание документов и загрузкой их в базу данных (БД ПОД), а также загрузкой самих документов или их адресов хранения в БДДок и БДАдр.;
Операции составления поисковых образов запроса (ПОЗ) с использованием тезауруса, поиска и выдачи результатов на просмотр и отбор или файл или на печать найденных документов или списка адресов;
Операции ведения информационно-поисковой системы, включающие актуализацию БД ПОД, БДДок., БДАдр. и тезауруса вследствие возникновения и необходимости пополнения памяти системы новыми документами или ключевыми словами. В состав операций ведения ИПС входит также процедура выдачи справок о работе системы, о ее структуре, методах поиска и классах и видах хранимых u1076 документах.
Как только посылка поступит на один из наших складов за рубежом или в России, вы получите оповещение по электронной почте. В дальнейшем Вы сможете отследить Вашу посылку на нашем сайте в разделе «Отслеживание», для этого необходимо ввести свой tracking-number.
Пожалуйста, убедитесь что Вы верно указали свой почтовый адрес в профиле IPS, и что Ваш электронный почтовый ящик не переполнен.
Если ваш продавец (интернет-магазин) сообщил Вам, что Ваша посылка прибыла в один из наших офисов, но вы все еще не можете отследить ее, пожалуйста, свяжитесь с нами, по возможности, предоставив полную информацию о вашей посылке (название магазина, отправителя и адрес отправления, идентификационный номер, дату отправления и т.д.).
- Вы хотите получить пока одну-две посылки:
- Вы планируете регулярно (несколько раз в месяц) получать письма, журналы или посылки из-за рубежа:
- Тарифы на наши услуги для наших постоянных клиентов ниже тарифов для непостоянных клиентов на 10-30 % (в зависимости от вида услуг).
- Расчет тарифов за доставку посылки из-за рубежа производится в соответствии с реальным весом этой посылки, а не за округленный вес до полного числа килограмм.
- Действуют накопительные скидки.
- Упаковка, переупаковка писем/посылок для наших постоянных клиентов производится бесплатно.
- Для постоянных клиентов осуществляется доставка или пересылка писем/посылок из наших зарубежных адресов на любой другой международный адрес или в руки любому лицу за рубежом.
- Постоянный клиент получает информацию обо всех изменениях заранее.
- Постоянный клиент может заказать нужную ему нестандартную услугу, даже если эта услуга не обозначена в списке услуг IPS и ее нужно выполнить за пределами России.
- Бесплатно хранить длительное время письма/посылки в наших зарубежных офисах.
- Самостоятельно забирать свои посылки в наших зарубежных офисах.
-
Могу я использовать абонируемый почтовый ящик в Вашем офисе для получения обычной почты, корреспонденции, счетов, подписки из Москвы или из России?
Конечно. Абонентская плата у нас дешевле, чем на Почте России. В данном случае, кроме абонентской платы Вы больше ничего не платите.
Мне нужно отправить посылку за рубеж. Чем услуги IPS по отправке отличаются от других курьерских компаний?
- Через нас клиент может отправить 3-мя режимами:
- почтовый режим – самый дешевый, но и самый медленный – 10-12 раб.дней;
- курьерский режим средней скорости доставки – 4-5 раб.дней (Экспресс-смарт);
- курьерский режим высшей скорости доставки - 1-2 раб.дня (Экспресс-бизнес).
- Мы самостоятельно оформляем за клиента все документы для таможни.
- Бесплатно консультируем по оптимизации логистического процесса отправки любого груза в любую страну мира.
- Через нас клиент может отправить 3-мя режимами:
-
У меня 4 маленьких посылки. Вы сможете упаковать эти посылки в одну?
Cможем. Мы обеспечим консолидацию посылок. Для постоянных клиентов (абонирующих почтовый ящик) – эта услуга бесплатная.
Каким образом я могу оплатить доставку?
На данный момент доступны наличный и безналичный способы оплаты.
Какая компенсация мне будет выплачена в случае потери посылки?
Наша доставка имеет высокую степень надежности. Однако если такое случилось и посылка была застрахована – полная застрахованная сумма.
Как долго занимает доставка посылки?
Обычно доставка занимает от 7 до 12 дней со дня поступления посылки на наш склад в соответствующей стране.
Могу ли я хранить мою посылку на вашем складе в США/Великобритании/Германии в течение 1-2 месяцев? Взимается ли за это дополнительная плата?
Если Вы не абонируете почтовый ящик компания IPS будет хранить бесплатно Вашу посылку только в течение 7 дней с момента поступления на склад. В случае хранения посылки свыше 7 дней взимается дополнительная плата. IPS оставляет за собой право по своему усмотрению распоряжаться посылками, которые хранятся на складе более чем на 60 дней, владельцы которых не осуществили оплату хранения.
Каковы преимущества доставки с компанией IPS?
Преимущества доставки с компанией IPS:
- надежность доставки;
- разумная и понятная стоимость доставки;
- выполняемый срок доставки -7-12 дней;
- наличие московского офиса, где всегда готовы помочь;
- возможность покупки товаров, не доступных в России;
- возможность покупки товаров в магазинах, не доставляющих товары в Россию;
- возможность экономии на доставке, используя услугу консолидации отправления и переупаковки.
-
Какую информацию я должен указать в поле «Адрес доставки» при покупке товаров в интернет-магазинах?
Вы должны ввести: адрес нашего зарубежного офиса, предоставленный Вам нашей компанией, Ваши Фамилию и Имя, номер Вашего почтового ящика.
Должен ли я что-то Вам сообщить после совершения покупки и отправки посылки на предоставленный мне адрес?
После осуществления заказа необходимо сообщить нам о совершенном заказе, предоставить данные заказа – описание вложения, его вес, стоимость. Эта информация необходима для обработки Ваших посылок.
Существуют ли ограничения возможных вложений?
С компанией IPS вы можете отправить посылку с любым вложением, не запрещенным законодательством Российской Федерации.
К запрещенным вложениям относятся:
- взрывчатые вещества,
- легковоспламеняющиеся предметы,
- радиоактивные материалы,
- сжатый газ,
- огнестрельное оружие,
- любые предметы, которые, по своей природе упаковки могут привести к травме сотрудников IPS или вызвать повреждение других предметов.
С полным перечнем запрещенных вложений вы сможете ознакомиться .
Перед тем как сделать покупку в интернет-магазине, пожалуйста, убедитесь, что ваша покупка не относится к категории опасных грузов.
Гарантирует ли IPS подлинность и качество приобретенного мною продукта?
IPS не несет ответственности перед клиентом за подлинность и качество приобретенного им товара. В целях собственной безопасности, пожалуйста, приобретайте товары только в проверенных интернет-магазинах.
Как правильно упаковать посылку?
Тем не менее, если это необходимо, пожалуйста, обеспечьте надлежащую упаковку вашего отправления, либо проинформируйте сотрудников IPS о необходимости дополнительной упаковки вашей посылки.
Мы не несем ответственность за любые убытки и повреждения, которые могут возникнуть во время обработки, перевозки или доставки вследствие ненадлежащей упаковки посылки отправителем.
Какие документы необходимо предоставить для подтверждения оценочной стоимости отправки?
Необходимо предоставить инвойс, подготовленный отправителем, указанные в нем суммы должны включать все налоги, а также все другие возможные сборы.
В каких интернет-магазинах я могу совершать покупки?
Что делать, если продавец выслал не тот товар / не правильное количество товара?
Так как компания IPS осуществляет только доставку вашей посылки в Россию, все вопросы, касательно комплектации и соответствия товара, а так же возможность обмена, либо возврата необходимо решать непосредственно с продавцом или отправителем.
Я хочу приобрести ювелирные изделия из драгоценных металлов с драгоценными камнями. Это возможно?
Нет. Мы не доставляем изделия из драгоценных металлов и/или с драгоценными камнями.
Когда я буду знать конечную стоимости доставки?
Только после того, как посылка поступит на наш, выбранный Вами, зарубежный склад.
Как только ваша посылка будет обработана, вы будете уведомлены по электронной почте относительно сроков доставки и конечной стоимости доставки. Вашей посылке будет присвоен персональный номер, вы сможете, следуя инструкциям в письме, оплатить стоимость доставки и отследить статус своего отправления.
В случае, если вы хотите произвести консолидацию вашего отправления, необходимо производить оплату после окончательного формирования посылки.
Клиенту, абонирующему почтовый ящик, не нужно совершать никаких оплат до получения своей корреспонденции/посылок в московском офисе IPS.
Если я решил отказаться от доставки в Россию посылки, которая пришла на мое имя в зарубежный офис IPS, будут ли с меня удержаны какие-то суммы, если будет необходимо вернуть посылку отправителю или уничтожить её?
Если по какой-либо причине вы решили остановить доставку в Россию вашей посылки, пожалуйста, срочно переговорите с вашим отправителем, чтобы он не отправлял на адрес IPS вашу посылку.
В случае, если посылка все же пришла на адрес склада IPS, мы можем по вашему указанию, отправить посылку обратно (или переправить на другой адрес) с удержанием 10$ административного сбора, а также 100% стоимости затрат на возврат/доставку посылки.
Так же мы можем утилизировать посылку с удержанием 10$ административного сбора (для посылок, не превышающих 15 кг). В случае хранения посылки более, чем 21 день, IPS взимает оплату в размере $.50 в день за одну посылку.
Каков минимальный оплачиваемый вес доставляемой посылки?
Для клиентов, абонирующих почтовый ящик - минимальный оплачиваемый вес составляет 1 фунт с последующим шагом в 0,1 фунт.
Доставка посылки из-за границы. Как это работает?
Всем нашим клиентам (будь это постоянный клиент или клиент, желающий получить посылку единоразово) мы предоставляем почтовые адреса в трех городах мира – Лондоне, Нью-Йорке, Ганновере. На любой из них Ваш респондент (интернет-магазин, друг, родственник, коллега и т.п.) может выслать Вам посылку и через – 7-10 рабочих дней после того, как она поступит на один из этих адресов, Вы получите ее в Москве.
Как мне получить адреса?
Есть два варианта:
Вам нужно подъехать с паспортом в офис IPS. Здесь сделают ксерокопию Вашего паспорта, запишут Ваши контактные телефоны и выдадут нужный Вам адрес (в Лондоне, в Нью-Йорке или в Ганновере).
Вам имеет смысл заключить договор на постоянное обслуживание. Для этого нужно абонировать почтовый ящик и регулярно вносить абонентский платеж. Минимальный размер месячной абонентской платы – 755,2руб (с учетом НДС 18%). (Есть и другие размеры абонентской платы, они зависят от набора дополнительный бесплатных услуг, уже включенных в абонентское обслуживание). В этом случае Вы получаете все три адреса и можете пользоваться ими по своему усмотрению.
Для получения адреса - можно мне к Вам не приезжать, а отправить копию паспорта по e-mail?
Можно, но тогда нужна предоплата.
В двух вышеуказанных случаях (см. вопрос 2) мы обслуживаем клиентов в режиме наложенного платежа - мы привозим (т.е. сначала оказываем услугу), а потом только получаем оплату от клиента. Поэтому для нас важно удостовериться, что наш клиент –реальное лицо.
Если Вы хотите нам отправить копию паспорта электронно, то для дальнейшего обслуживания важна предоплата от Вас в размере не менее 4000,0 руб. Если после оказания и оплаты услуги доставки у Вас остается сумма – по первому Вашему требованию эта сумма будет Вам возвращена на те реквизиты, с которых она была отправлена Вами нам. Либо в дальнейшем вы сможете использовать ее для оплаты услуг в нашей компании.
Почему выгодно абонировать почтовый ящик?
Клиент, который абонирует почтовый ящик, становится нашим постоянным клиентом.
Постоянные клиенты имеют следующие льготы:
Добрый день, мои уважаемые читатели. Сегодня мы коснемся чрезвычайно интересной и важной темы – информационно поисковые системы. Умение правильно работать с ними, знание основных понятий и принципов работы смогут помочь начинающим пользователям научиться быстро и оперативно искать различную информацию в сети, получать нужные данные и быстро развивать свой интернет бизнес.
В данной статье я расскажу об истории создания систем поиска, принципах их работе и структуре. Помимо этого, остановлюсь на очень важных фишках, которые необходимо обязательно знать при работе с ИПС.
Итак, давайте более подробно изучим, что такое ИПС, какие компоненты входят в их состав.
Информационно – поисковые системы (ИПС) и их виды
Данное понятие возникло еще в конце 80 – х, начале 90 – х годов прошлого века. Именно тогда и возникли их первые прототипы, как в России, так и за рубежом. Согласно определению – это система, которая позволяет искать, обрабатывать, отбирать требуемые данные запроса в своей особой базе, где находятся описания различных источников информации, а также правила пользования ими.
Основной ее задачей является поиск нужной пользователю информации. Для того, чтобы он был более эффективным, используется понятие релевантности, то есть то, насколько сами результаты поиска точно подходят тому или иному запросу.
К основным типам ИПС относятся следующие понятия:
Индексация каталога может производиться, как вручную, так и автоматически с обновлением индекса. В свою очередь сам результат работы системы включает в себя особый список. В него входят гиперссылка на требуемые ресурсы и описание того или иного документа в интернете.
Из наиболее популярных каталогов можно выделить: Yahoo , Magellan (зарубежные) и Weblist , Улитка и @ Rus из отечественных.

К наиболее распространенным зарубежным ИПС относят – Google, Altavista, Excite. Русские – «Яндекс» и «Рамблер».
- В мире существует огромное количество различных видов ИПС, которые содержат множество источников информации. Разумеется, что даже наличие самого современного и мощного сервера не может удовлетворить запросы миллионов пользователей. Именно поэтому, появились специальные метапоисковые системы. Они могут одновременно пересылать запросы пользователей различным поисковым серверам, а на основе своего обобщения имеют возможность предоставить пользователю документ, содержащий ссылки на требуемый ресурс. К их числу можно отнести – MetaCrawler или SavvySearch.
История создания ИПС
Самые первые ИПС появились в середине 90 – х годов 20 века. Они весьма напоминали обычные указатели, которые находятся в любых книгах, некие справочники. В их базе данных содержались специальные ключевики (слова), которые различными способами собирались с многочисленных сайтов. Так, как интернет – технологии были не совершенными, то и сам поиск выполнялся только по ключевым словам.
Значительно позднее был разработан специальный полнотекстовый поиск, облегчающий нахождение необходимой пользователю информации. Система производила фиксацию ключевых слов. Благодаря ей, пользователи могли производить нужные запросы по тем или иным словам и различным словосочетаниям.

Одной из первых, была «Wandex». Ее разработкой занимался очень известный программист Мэтью Греэм в 1993 году. Также, в этом же году возникла и новая «поисковка» «Aliweb» (кстати, и по сей день успешно работает). Однако все они имели достаточно сложную структуру и не обладали современными технологиями.
Одной из наиболее удачных явилась «WebCrawler», которая впервые была запущена в 1994 году. Отличительной особенностью и главным преимуществом, выгодно выделяющим ее среди других систем поиска, явилось то, что она могла находить любые ключевики на той или иной странице. После этого, это стало своего рода эталоном и для всех остальным ИПС, которые разрабатывались позднее.
Значительно позже возникли и другие поисковики, которые иногда конкурировали между собой. Это были – «Excite», «AltaVista», «InfoSeek», «Inktomi» и многие другие. Начиная с 96 года, российские пользователи сети начали работать с «Рамблером» и «Апортом». Но, настоящим триумфом для российского интернета, стал созданный в 1997 году «Яндекс».
Этот российский аналог «Google» стал настоящей гордостью российских программистов. Сегодня, он уверенно теснит конкурента в рунете и также является одним из лидеров по поисковым запросам среди ИПС в России.
На сегодняшний день, имеются многочисленные специальные «поисковики», которые созданы для решения определенных задач. Так, например, информационно – поисковая система «Патрон», разработана для того, чтобы хранить и искать данные по патронам для различного оружия и сейчас применяется, как в органах Министерства Внутренних Дел и спецслужб, так и для охотников – профессионалов и любителей.
Имеются и другие, разработанные для нотариусов, врачей, инженеров, военных, автолюбителей и т д
Как работает ИПС

Работа информационно – поисковой системы является очень сложной. Однако при желании можно разобраться в ее структуре. Первое, что необходимо отметить, что существует особая программа – она называется поисковым роботом (пауком). Данная программа систематически мониторит различные страницы и индексирует их.
Веб сервер создает запрос пользователя на получение той или иной информации, а затем предоставляет данный запрос машине поиска. Поисковик исследует требуемую базу данных, потом составляет полный список страниц, а затем передает веб-серверу. Он в свою очередь окончательно формирует все результаты запроса в «читаемый» вид, затем передает их на «комп» пользователя.
ИПС предназначена для следующих целей:
- Хранить значительные объемы данных;
- Производить оперативный поиск нужной информации;
- Добавлять, а также удалять различные данные;
- Выводить информацию в простом и удобном виде.
Существуют несколько основных типов ИПС:
- Автоматизированные
- Библиографические
- Диалоговые
- Документальные
Какие поисковые системы наиболее популярны сегодня?

На первом месте, без всякого сомнения, находиться неотъемлемый лидер – «Google». На сегодняшний день, к нему адресуется около 80 процентов различных мировых запросов по самым различным сферам. Что касается второго места, то его, также заслуженно, занимает американский «eBay».
На третьем месте, наш, отечественный, российский «Яндекс». На четвертом – «Yahoo» и на пятом – MSN. Еще одним отечественным браузером, но занимающим только 10 место в рейтинге Европы – это российский «Rambler».
Этот поисковик знают огромное количество пользователей. На сегодняшний день это первая по популярности система в мире! Ежемесячно она обрабатывает более 41 млрд запросов и проводит индексацию 25 миллиардов страниц.
Что касается истории создания компании «Google», то еще в 1996 году, пара студентов университета Стэнфорда – Ларри Пейдж и Сергей Брин разработали браузер, созданный на новых методах поиска. Назвали они ее просто и лаконично, как собственно и дизайн поисковой системы «Google». Собственно название google – это искаженный googol (число десять в сотой степени).

В основе нее специальный поисковый робот, который называется «Googlebot». Он производит сканирование страниц и их индексацию. В качестве алгоритма авторитетности, эта ПС . Собственно именно он обеспечивает то, как будут выдаваться страницы посетителю в поисковых результатах.
Одним из первых, эта фирма разработала и на различных языках, который значительно облегчает введение данных в систему. Ну, и наконец, именно и послужил основой для слова «гуглить», которое все чаще встречается в сленге молодых тинейджеров.
«Yahoo » – вторая по популярности в США. Ее организовали в 1994 году два аспиранта Стэнфорда – Дэвид Фило и Джерри Янг. В конце 90 –х ими был приобретен портал RocketMail и на основе него создан бесплатный почтовый сервер «Yahoo». Сегодня на ее серверах можно хранить любое количество писем. В 2010 году появляется и русскоязычный ресурс почты – Yahoo! Почта.
Яндекс
Одним из лучших российских поисковиков, вне всякого сомнения, является «Яндекс». На сегодняшний день он стоит на четвертом месте по общему количеству запросов. В то же самое время, по популярности «Яндекс» занимает сегодня первое место в Российской Федерации. Общее количество произведенных запросов превышает 250 миллионов каждый день
Он был представлен в сентябре 1997 года, а уже в мае 2011, произведя размещение своих акций на IPO, эта фирма смогла заработать наибольшее количество акций среди других интернет – компаний.

Сегодня, «Yandex» имеет 50 сервисов, из которых некоторые уникальные – Яндекс.Поиск, Яндекс.Карты, Яндекс.Маркет. Помимо этого, российских пользователей очень интересуют такие сервисы, как «Поиск по блогам», «Яндекс Пробки». Основные запросы для пользователей в основном из следующих стран ближнего зарубежья: Россия, Белоруссия, Турция и Казахстан.
Исторически фирму основал бизнесмен – программист Аркадий Волож в 1989 году. Само название компании было придумано Ильей Сегаловичем, директором «Яндекса». Благодаря сотрудничеству с институтом проблем передачи информации был создан справочный словарь с поиском.
В отличие от других браузеров, учитывает и морфологию русского языка. Таким образом, сама система предназначена именно для работы в русскоязычном сегменте интернета.
Начиная с 2010 года, помимо браузера «Yandex.ru» появился еще один поисковик «Yandex.com». Данный интернет – ресурс используется для поиска по зарубежным порталам.
Поисковая система « Ebay »
Ebay представляет собой интернет – компанию из США, которая специализируется на проведении интернет – аукционов. Она производит управление портала eBay.com, а также версиями в других странах мира. Помимо этого, в собственности фирмы есть еще одна eBay Enterprise.

Основателем фирмы является американский программист Пьер Омидьяр, который в середине 90 – х годов разработал интернет – аукцион для своего личного портала. В то же время, eBay – это своего рода посредник при купле продаже. Чтобы использовать его продавцы вносят определенный взнос, а покупатели получают возможность бесплатного использования сайта.
Общие принципы его работы следующие:
- В основном все люди добропорядочны
- Каждый может внести свой вклад
- В открытом общении люди проявляют свои лучшие качества
Уже в 1995 году на тысячах онлайн аукционов продавались миллионы различных предметов. Сегодня, это мощная платформа для купли продажи, как физлицами, так и юрлицами.
С 2010 года возникла и русскоязычная версия популярного ресурса и стала называться «Международный торговый центр eBay». Оплата на аукционе производится через платежную систему «PayPal».
Для того, чтобы продать предметы на данном портале необходимо написать сколько он стоит, его стартовая цена, когда начнутся торги, а также сколько будут длиться торги. Как и в обычном аукционе, выбранный товар получает заплативший самую высокую цену.
Из плюсов подобного аукциона стоит отметить то, что продавец и покупатель могут находиться в любом месте земного шара, а наличие локальных филиалов и временных рамок предоставляют возможность участвовать в аукционах огромному количеству продавцов и покупателей.

Данная поисковая система является ведущим интернет – браузером, разработанным компанией «Microsoft». Он появился одновременно с выпуском первой операционной системы Windows 95. Далее этим названием стал пользоваться и сервис электронной почты Hotmail, а также различные веб-узлы Майкрософт. В начале 2002 года он являлся одним из самых крупных интернет – провайдеров в США и имел 9 миллионов подписчиков.
Поисковая система Rambler
Вторым крупным российским поисковиком, является интернет – портал «Rambler». По своей сути, вместе с «Яндекс» он является родоначальником рунета, а также главным игроком на рынке медиа услуг.
Основателем его является Сергей Лысаков, который в 1994 году разработала поисковую систему, а в 1996 году был зарегистрирован и домен www.rambler.ru. Начиная с 2012 года, «Рамблер» стал работать, как новостной портал.
Сегодня он имеет 11 место по популярности среди других сайтов РФ. Также, был разработан и специальный классификатор Rambler Top-100. По своей сути он был первый и в России. Сегодня – это удобный каталог объектов недвижимости «Rambler – недвижимость».
Поисковик mail

Одной из самых крупных почтовых служб явилась, созданная в 1998 году, Mail.ru. Сегодня она представляет собой службу электронной почты, каталог интернет – ресурсов и информационные разделы. Помимо очень удобной почты, она имеет ряд специальных проектов, которые весьма популярны и нужны подписчикам: «Авто Mail.ru», Афиша «Mail.ru», «Дети mail.ru», «Здоровье mail.ru», «Леди mail.ru», «Новости mail.ru» и «Недвижимость mail.ru».
Для любителей спорта и Hi-Tech есть соответствующие рубрики.
На этом я завершаю свой материал. Если вам нравилось, то, пожалуйста, подписывайтесь на мой блог и приглашайте своих родных, друзей и знакомых.
(Пока оценок нет)
Прочитано: 469 раз
В данной статье я хотел бы рассмотреть различные техники поиска информации о VoIP-устройствах в сети, а затем продемонстрировать несколько атак на VoIP.
Введение
В последние несколько лет наблюдались высокие темпы внедрения IP-телефонии (VoIP). Большинство организаций, внедривших VoIP, либо игнорируют проблемы безопасности VoIP и ее реализации, либо попросту не знают о них. Как и любая другая сеть, сеть VoIP чувствительна к неправильной эксплуатации. В данной статье я хотел бы рассмотреть различные техники поиска информации о VoIP-устройствах в сети, а затем продемонстрировать несколько атак на VoIP. Я сознательно не стал спускаться до деталей уровня протокола, поскольку данная статья предназначена для пентестеров, которые хотят для начала попробовать основные приемы. Однако я настоятельно рекомендую изучить протоколы, используемые в VoIP-сетях.
Возможные атаки на VoIP
- Отказ в обслуживании (DoS)
- Похищение регистрационных данных и манипуляция ими
- Атаки на систему аутентификации
- Подмена (спуфинг) Caller ID
- Атаки типа "Человек посередине"
- "Шаманство над VLAN-ами" (Vlan hopping)
- Пассивное и активное прослушивание
- Спам через интернет-телефонию (SPIT)
- VoIP фишинг (Vishing)
Конфигурация лаборатории для тестирования VoIP
Чтобы продемонстрировать проблемы безопасности VoIP в рамках данной статьи, я использовал следующую конфигурацию лаборатории:
- Trixbox i (192.168.1.6) - IP-PBX сервер с открытым исходным кодом
- Backtrack 4 R2 (192.168.1.4) - ОС на машине атакующего
- ZoIPer ii (192.168.1.3) - программный телефон для Windows (пользователь A - жертва)
- Linphone iii (192.168.1.8) - программный телефон для Windows (пользователь B - жертва)
Конфигурация нашей лаборатории

Рисунок 1
Рассмотрим схему лаборатории, представленную выше. Это - типичная конфигурация VoIP-сети небольшой организации с маршрутизатором, который выделяет IP-адреса устройствам, IP-PBX системе и пользователям. Если пользователь A данной сети захочет связаться с B , произойдет следующее:
- Звонок A направляется на IP-PBX сервер для аутентификации пользователя.
- После успешной аутентификации A IP-PBX сервер проверяет присутствие экстеншена (внутреннего номера) пользователя B . Если экстеншен присутствует, звонок перенаправляется B .
- На основании ответа B (например, прием звонка, сброс и т. п.) IP-PBX сервер отвечает пользователю A .
- Если все в порядке, A начинает общение с B .
Теперь, когда у нас есть ясная картина взаимодействия, давайте перейдем к развлекательной части - атакам на VoIP.
Поиск VoIP устройств
Поиск устройств (enumerating) - лежит в основе каждой успешной атаки/пентеста, поскольку он обеспечивает атакующего как необходимыми подробностями, так и общим представлением о конфигурации сети. VoIP - не исключение. В VoIP-сети нам, как атакующим, будет полезна информация о VoIP-шлюзах/серверах, IP-PBX системах, клиентских программных и VoIP-телефонах и номерах пользователей (экстеншенах). Давайте посмотрим на некоторые широко используемые инструменты для поиска устройств и создания отпечатков (fingerprints). Для упрощения демонстрации предположим, что нам уже известны IP-адреса устройств.
Smap
Smap iv сканирует отдельный IP-адрес или подсеть на предмет включенных SIP-устройств. Давайте используем smap против IP-PBX сервера. Рисунок 2 показывает, что мы смогли найти сервер и получить информацию о его User-Agent.

Рисунок 2
Svmap
Svmap - другой мощный сканер из набора инструментов sipvicious v . Данный инструмент позволяет выставить тип запроса, использующийся при поиске SIP-устройств. Тип запроса по умолчанию - OPTIONS. Давайте запустим сканер для пула из 20 адресов. Как видно, svmap может обнаруживать IP-адреса и информацию о User-Agent.

Рисунок 3
Swar
При поиске VoIP-устройств для определения действующих SIP-экстеншенов может помочь поиск по номерам пользователей. Svwar vi позволяет сканировать полный диапазон IP-адресов. Рисунок 4 показывает результат сканирования пользовательских номеров в диапазоне от 200 до 300. В результате получаем экстеншены пользователей, зарегистрированные на IP-PBX сервере.

Рисунок 4
Итак, мы рассмотрели процесс поиска VoIP-устройств и получили некоторые интересные детали конфигурации. Теперь давайте воспользуемся этой информацией для атаки на сеть, конфигурацию которой мы только что исследовали.
Атака на VoIP
Как уже обсуждалось, VoIP-сеть подвержена множеству угроз безопасности и атак. В данной статье мы рассмотрим три критические атаки на VoIP, которые могут быть направлены на нарушение целостности и конфиденциальности VoIP-инфраструктуры.
В дальнейших разделах продемонстрированы следующие атаки:
- Атака на VoIP-аутентификацию
- Прослушивание через ARP-спуфинг
- Имитация Caller ID
1. Атака на VoIP-аутентификацию
Когда новый или существующий VoIP-телефон подсоединяется к сети, он посылает на IP-PBX сервер запрос REGISTER для регистрации ассоциированного с телефоном идентификатора пользователя/экстеншена. Этот запрос на регистрацию содержит важную информацию (вроде информации о пользователе, данных аутентификации и т. п.) которая может представлять большой интерес для атакующего или пентестера. Рисунок 5 показывает перехваченный пакет запроса на аутентификацию по протоколу SIP. Перехваченный пакет содержит лакомую для атакующего информацию. Давайте используем данные пакета для атаки на аутентификацию.

Рисунок 5
Демонстрация атаки
Сценарий атаки
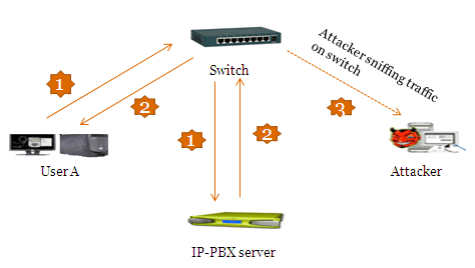
Рисунок 6
Шаг 1: Для упрощения демонстрации предположим, что у нас есть физический доступ к VoIP-сети. Теперь, используя инструменты и техники, описанные в предыдущих разделах статьи, мы проведем сканирование и поиск устройств, чтобы получить следующую информацию:
- IP-адрес SIP-сервера
- Существующие идентификаторы и экстеншены пользователей
Шаг 2: Давайте перехватим несколько запросов на регистрацию с помощью wireshark vii . Мы сохраним их в файле с именем auth.pcap. Рисунок 7 показывает файл wireshark с результатами перехвата (auth.pcap).

Рисунок 7
Шаг 3:
Теперь мы используем набор инструментов sipcrack viii . Набор входит в состав Backtrack и находится в директории /pentest/VoIP. Рисунок 8 показывает инструменты из набора sipcrack.
Рисунок 8
Шаг 4: Используя sipdump, давайте выгрузим данные аутентификации в файл с именем auth.txt. Рисунок 9 показывает файл захвата wireshark, содержащий аутентификационные данные пользователя 200.

Рисунок 9
Шаг 5: Эти данные аутентификации включают в себя идентификатор пользователя, SIP-экстеншен, хэш пароля (MD5) и IP-адрес жертвы. Теперь мы используем sipcrack, чтобы взломать хэши паролей с помощью атаки по заготовленному словарю. Рисунок 10 показывает, что в качестве словаря для взлома хэшей используется файл wordlist.txt. Мы сохраним результаты взлома в файле с именем auth.txt.

Рисунок 10
Шаг 6: Замечательно, теперь у нас есть пароли для экстеншенов! Мы можем использовать эту информацию, чтобы перерегистрироваться на IP-PBX сервере с нашего собственного SIP-телефона. Это позволит нам выполнять следующие действия:
- Выдавать себя за легального пользователя и звонить другим абонентам
- Прослушивать и манипулировать легальными звонками, исходящими и входящими на экстеншен жертвы (пользователя A в данном случае).
2. Прослушивание через Arp-спуфинг
Каждое сетевое устройство имеет уникальный MAC-адрес. Как и остальные сетевые устройства, VoIP телефоны уязвимы к спуфингу MAC/ARP. В данном разделе мы рассмотрим снифинг активных голосовых звонков путем прослушивания и записи действующих разговоров по VoIP.
Демонстрация атаки
Сценарий атаки

Рисунок 11
Шаг 1: В целях демонстрации, давайте предположим, что мы уже определили IP-адрес жертвы, используя ранее описанные техники. Далее, используя ucsniff ix как средство ARP-спуфинга, мы подменим MAC-адрес жертвы.
Шаг 2: Важно определить MAC-адрес цели, который требуется подменить. Хотя ранее упоминавшиеся инструменты были способны определять MAC-адрес автоматически, хорошей практикой будет определить MAC независимо, отдельным способом. Давайте используем для этого nmap x . Рисунок 12 показывает результаты сканирования IP-адреса жертвы и полученный в результате MAC-адрес.

Рисунок 12
Шаг 3: Теперь, когда у нас есть MAC-адрес жертвы, давайте используем ucsniff, чтобы подменить ее MAC. ucsniff поддерживает несколько режимов спуфинга (режим наблюдения, режим изучения и режим MiTM, т. е. «человек-посередине»). Давайте используем режим MiTM, указав IP-адрес жертвы и SIP-экстеншен в файле с именем targets.txt. Этот режим гарантирует, что прослушиваются только звонки (входящие и исходящие) жертвы (пользователь A ), не затрагивая другой трафик в сети. Рисунки 13 и 14 показывают, что ucsniff подменил MAC пользователя A (в ARP-таблице).

Рисунок 13

Рисунок 14
Шаг 4: Мы успешно подменили MAC-адрес жертвы и теперь готовы прослушивать входящие и исходящие звонки пользователя A по VoIP-телефону.
Шаг 5: Теперь, когда пользователь B звонит пользователю A и начинает диалог, ucsniff принимается записывать их беседу. Когда звонок завершается, ucsniff сохраняет записанную беседу целиком в wav-файл. Рисунок 15 показывает, что ucsniff обнаружил новый звонок с экстеншена 200 на экстеншен 202.
Рисунок 15
Шаг 6: Когда мы закончим, мы вызывем ucsniff снова с ключом -q, чтобы прекратить спуфинг MAC в системе и, таким образом, гарантировать, что после завершения атаки все встало на свои места.
Шаг 7: Сохраненный аудиофайл можно проиграть, используя любой известный медиаплеер вроде windows media player.
Спуфинг Caller ID
Это одна из простейших атак на VoIP-сети. Спуфинг ID абонента соответствует сценарию, когда неизвестный пользователь может выдать себя за легального пользователя VoIP-сети. Для реализации данной атаки может быть достаточно легких изменений в INVITE запросе. Существует множество способов формирования искаженных нужным образом SIP INVITE сообщений (с помощью scapy, SIPp и т. д.). Для демонстрации используем вспомогательный модуль sip_invite_spoof из фреймворка metasploit xi .
Сценарий атаки

Рисунок 16
Шаг 1: Давайте запустим metasploit и загрузим вспомогательный модуль voip/sip_invite_spoof.
Шаг 2: Далее, установим значение опции MSG в User B . Это даст нам возможность выдавать себя за пользователя B . Пропишем также IP-адрес пользователя A в опции RHOSTS. После настройки модуля, мы запускаем его. Рисунок 17 демонстрирует все настройки конфигурации.

Рисунок 17
Шаг 3: Вспомогательный модуль будет посылать измененные invite-запросы жертве (пользователю A ). Жертва будет получать звонки с моего VoIP телефона и отвечать на них, думая, что говорит с пользователем B . Рисунок 18 показывает VoIP-телефон жертвы (A ), которая получает звонок якобы от пользователя B (а на самом деле от меня).

Рисунок 18
Шаг 4: Теперь A считает, что поступил обычный звонок от B и начинает говорить с тем, кто представился как User B .
Заключение
Множество существующих угроз безопасности относится и к VoIP. Используя поиск устройств, можно получить критичную информацию, относящуюся к VoIP-сети, пользовательским идентификаторам/экстеншенам, типам телефонов и т. д. С помощью специальных инструментов, возможно проводить атаки на аутентификацию, похищать VoIP звонки, подслушивать, манипулировать звонками, рассылать VoIP-спам, проводить VoIP-фишинг и компрометацию IP-PBX сервера.
Я надеюсь, что данная статья была достаточно информативной, чтобы обратить внимание на проблемы безопасности VoIP. Я бы хотел попросить читателей отметить, что в данной статье не обсуждались все возможные инструменты и техники, использующиеся для поиска VoIP-устройств в сети и пентестинга.
Об авторе
Сохил Гарг - пентестер в PwC. Области его интересов включают разработку новых векторов атак и тестирование на проникновение в охраняемых средах. Он участвует в оценках защищенности различных приложений. Он докладывал о проблемах безопасности VoIP на конференциях CERT-In, которые посещали высокопоставленные правительственные чиновники и представители ведомств обороны. Недавно он обнаружил уязвимость в продукте крупной компании, дающую возможность повышения привилегий и прямого доступа к объекту.
Ссылки
i http://fonality.com/trixbox/ii http://www.zoiper.com/
iii http://www.linphone.org/
iv http://www.wormulon.net/files/pub/smap-blackhat.tar.gz
v
vi http://code.google.com/p/sipvicious/
vii http://www.wireshark.org/
viii Этот инструмент можно найти в Backtrack 5 в каталоге /pentest/voip/sipcrack/
ix http://ucsniff.sourceforge.net/
x http://nmap.org/download.html
xi http://metasploit.com/download/



