Что такое веб-архив
Существует настоящая, реальная машина времени, в которой можно ненадолго вернуться в прошлое и увидеть, например, как выглядел тот или иной сайт несколько лет назад. Думаете, никому не нужны копии сайтов многолетней давности? Ошибаетесь! Для очень многих людей сервис по архивированию информации весьма полезен.
Во-первых, это просто интересно! Из чистого любопытства и от избытка свободного времени можно посмотреть, как выглядел любимый, популярный ресурс на заре его рождения.
Во-вторых, далеко не все владельцы сайтов ведут свои архивы. Знать место, где можно найти информацию, которая была на сайте в какой-то момент, а потом пропала, не просто полезно, а очень важно.
В-третьих, само по себе сравнение является важнейшим методом анализа, который позволяет оценить ход и результаты нашей деятельности. Кстати, при проведении анализа веб-ресурса очень эффективно использовать ряд методов сравнения.
Поэтому наличие уникальнейшего архива веб-страниц интернета позволяет нам получить доступ к огромному количеству аудио-, видео- и текстовых материалов. По утверждению разработчиков, «интернет-архив» хранит больше материалов, чем любая библиотека мира. Мы попали в правильное место!
Что нужно, чтобы найти копии сайтов интернета
Для того, чтобы отправиться в прошлое, нужно перейти на сайт archive.org и воспользоваться поисковой строкой.

Простой поиск в архиве сохраненных сайтов выдает нам ссылки на все сохраненные копии запрашиваемой страницы.

Из этого видно, что сайт сайт был создан в 2012 году (Кстати, важно отметить, с помощью практически идеального хостинга Спринтхост — рекомендую!). Переключаясь на нужный нам год, можно увидеть даты, выделенные кружочками, это и есть даты сохранения копии сайта. Например, в 2015 году, пока можно будет увидеть только одну копию от 7 февраля.
Конечно, это потрясающий ресурс! Ведь здесь индексируются и архивируются все сайты интернета! Это не только скриншоты… Имея в руках такой инструмент, можно восстановить массу потерянной со временем информации.
Надо заметить, что, безусловно все восстановить однозначно не получится, так как если на страницах сайта используются элементы Java Script, или скрипты или графика взяты со стороннего сервера, то на восстановление такой информации рассчитывать не придется. Поэтому к сохранению данных своего сайта нужно относиться с особенным вниманием, несмотря ни на что.
Пользуясь случаем, я сделала скриншоты и восстановила в памяти, как выглядел мой сайт, начиная с 2012 года. Любопытно посмотреть))
Сайт буквально недавно «родился»)) Январь 2012.. .

Проходит время, и хочется что-то изменить… Конец 2012-го.

Наверное, пора уже что-то менять. 2013-й. Это тема, которая и сегодня установлена на моем сайте.

К смене темы отношусь с осторожностью, так как помню последний «переезд», после которого несколько месяцев восстанавливала посещаемость сайта. Как-то не очень удачно получилось.
Надеюсь, что и моим читателям эта замечательная интернет-библиотека — «машина времени» сможет помочь перемещаться во времени, когда они этого захотят. Посмотрите, как выглядели раньше некоторые сайты, еще во времена своего зарождения. Какими раньше были google или яндекс, можно увидеть только на archive.org, аналогов у этого ресурса нет. Приятного путешествия, друзья!
Здравствуйте, уважаемые читатели блога сайт. Не так давно я писал про то, которая безусловно заслуживает всяких лестных эпитетов, несмотря на присущие ей небольшие недостатки и критику ее статей со стороны научного сообщества.
Сам факт того, что некоммерческий проект уже не одно десятилетие трудится на благо всего интернет сообщества, заслуживает огромного уважения. Но в сети есть еще подобный масштабный проект, который не получая с этого дохода выполняет очень важную роль — сохраняет архивы сайтов , видео, аудио и печатной продукции.
Что примечательно, в последней колонке этого списка (его можно открыть в Excel) будет отображаться количество архивов, созданных для каждого сайта в Web Archive (правда, проверить наличие домена в веб-архиве можно и в ряде онлайн сервисов, например, на этом или на этом).

Список буржуйских доменных имен, освобождающихся или уже освободившихся, предлагается скачать по этой ссылке . Ну, а дальше просматриваем содержимое сайтов, которое сохранил Web Archive и пытаемся найти что-то стоящее. Потом проверяем уникальность этих материалов (ссылку приводил чуть выше) и в случае удачи публикуем их на своем ресурсе, либо продаем в какой-нибудь .
Да, способ муторный и мною лично не проверенный. Но, думаю, что при некоторой степени автоматизации и обмозговывания он может давать неплохой выхлоп. Наверное, кто-нибудь уже это поставил на поток. А вы как думаете?
Удачи вам! До скорых встреч на страницах блога сайт
посмотреть еще ролики можно перейдя на");">

Вам может быть интересно
Сравнение сайтов в SEObuilding.RU для бесплатного анализа потенциальных доноров при покупке ссылок
 Бесплатный онлайн сервис по подбору красивых и свободных для регистрации доменов (Frishki.ru)
Бесплатный онлайн сервис по подбору красивых и свободных для регистрации доменов (Frishki.ru)
 Фотостоки и фотобанки - 30 бесплатных легальных источников фотографий, изображений и иконок
Фотостоки и фотобанки - 30 бесплатных легальных источников фотографий, изображений и иконок
 SEObuilding.RU - комплектный бесплатный анализ сайтов с расчетом их траста, стоимости и многого другого
SEObuilding.RU - комплектный бесплатный анализ сайтов с расчетом их траста, стоимости и многого другого
 Проверка (анализ) сайта - 85 онлайн сервисов и программ
Проверка (анализ) сайта - 85 онлайн сервисов и программ
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.сайт/
Где http://www.сайт/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

6. Archive.is, для собственного кэша

Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса..
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari .
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:

После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:
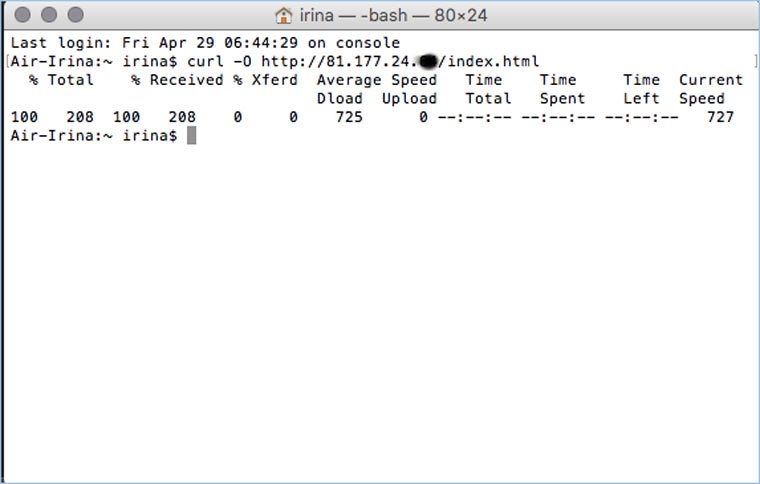
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com :
А о сборе информации про людей читайте в статьях и .
Есть ли история у интернет-сайтов? Есть сервисы и инструменты, которые позволяют узнать историю для большинства сайтов.
Как же нам узнать и посмотреть своими глазами историю интересного нам сайта? Ответ вы узнаете из этой статьи.
Интернет – это динамическая среда, в которой все меняется очень быстро. Так, у доменных имен могут меняться их владельцы, обновляться или даже полностью меняться контент сайта, его дизайн, разметка, функциональность. Стоит пустить сайт на самотек – и он уже через пару лет сильно устареет.
Благодаря одному интересному инструменту мы можем узнать историю, отправившись в прошлое, будто бы на машине времени.
Вебархив — www.archive.org
Это интернет-сайт, который индексирует сайты, делает снимки их состояния в разное время и кладет их на свои полки архива, то есть на жесткие диски.
Интересно узнать историю Google.com? Это сделать очень просто – заполняем и смотрим:

История поисковика Google уходит своими корнями в далекий по меркам интернета 1998 год. Посмотрим как он выглядел тогда:

Вот такой вид имела поисковая система Google в то время. Посмотрим еще на любимый Яндекс примерно в то же время:

Любой популярный сайт, как правило, архивируется подобным образом, так что любой желающий может пострадать ностальгией и вспомнить, как давным-давно выглядели его любимые сайты.
Разумеется, сохранить всю историю всех сайтов невозможно, но тем не менее, в базе данных веб архива насчитывается более 450 000 000 сайтов. Архив может быть полезен в самых разных случаях и, кроме того, он абсолютно бесплатен!
Если нужно узнать хронологию сайта, то сервис незаменим, так как можно:
1. Определить тематику усиленного имени и сайта
С помощью веб архива мы сможем увидеть контент, который был на сайте этого домена, а значит – распознать тематику ресурса.
2. Узнать историю сайта
Частно начинающие вебмастеры забрасывают свои сайты, недооценивая их потенциал. А опытные веб-мастеры просто охотятся на такие домены с хорошей историей, чтобы создать на них сайты. Одним из инструментов, который они используют для анализа истории и содержания старого сайта является веб архив.
Поэтому не стоит пренебрегать возможностями, которые нам предоставляет веб архив. Ведь применяя этот инструмент, можно извлечь достаточно много полезной информации о сайте, в том числе просмотреть контент старого сайта.
Каждый сайт - это история, которая имеет начало и конец. Но как проследить этапы становления проекта, его жизненный цикл? Для этих целей существует специальный сервис, который именуется веб-архивом. В этой статье мы поговорим о представлении подобных ресурсов, их использовании и возможностях.
Что такое веб-архив и зачем он нужен?
Веб-архив - это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие - открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции. Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Как использовать веб-архив?

Как уже отмечалось выше, веб-архив - это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Проекты, предоставляющие историю сайта

Сегодня существует несколько проектов, которые предоставляют сервисные услуги по отысканию сохраненных копий. Вот некоторые из них:
- Самым популярным и востребованным у пользователей является web.archive.org. Представленный сайт считается наиболее старым на просторах интернета, создание датируется 1996 годом. Сервис проводит автоматический и ручной сбор данных, а вся информация размещается на огромных заграничных серверах.
- Вторым по популярности сайтом считается peeep.us. Ресурс весьма интересен, ведь его можно использовать для сохранения копии информационного потока, который доступен только вам. Заметим, что проект работает со всеми доменными именами и расширяет границы использования веб-архивов. Что касается полноты информации, то представленный сайт не сохраняет картинки и фреймы. С 2015 года также внесен в список запрещенных на территории России.
- Аналогичным проектом, который описывали выше, является archive.is. К отличиям можно отнести полноту сбора информации, а также возможности сохранения страниц из социальных сетей. Поэтому если вы утеряли пост или интересную информацию, можно выполнить поиск через веб-архив.
Возможности использования веб-архивов

Теперь каждый знает, что такое веб-архив, какие сайты предоставляют услуги сохранения копий проектов. Но многие до сих пор не понимают, как использовать представленную информацию. Возможности архивных данных выражаются в следующем:
- Выбор доменного имени. Не секрет, что многие веб-мастера используют уже прокачанные домены. Стоит понимать, что опытные юзеры отслеживают не только целевые параметры, но и историю предыдущего использования. Каждый пользователь сети желает знать, что приобретает: имелись ли ранее запреты или санкции, не попадал ли проект под фильтры.
- Восстановление сайта из архивов. Иногда случается беда, которая ставит под угрозу существование собственного проекта. Отсутствие своевременных бэкапов в профиле хостинга и случайная ошибка может привести к трагедии. Если подобное произошло, не стоит расстраиваться, ведь можно воспользоваться веб-архивом. О процессе восстановления поговорим ниже.
- Поиск уникального контента. Ежедневно на просторах интернета умирают сайты, которые наполнены контентом. Это случается с особым постоянством, из-за чего теряется огромный поток информации. Со временем такие страницы выпадают из индекса, и находчивый веб-мастер может позаимствовать информацию на личный проект. Конечно, существует проблема с поиском, но это вторичная забота.
Мы рассмотрели основные возможности, которые предоставляют веб-архивы, самое время перейти к более подробному изучению отдельных элементов.
Восстанавливаем сайт из веб-архива

Никто не застрахован от проблем с сайтами. Большинство их них решается с использованием бэкапов. Но что делать, если сохраненной копии на сервере хостинга нет? Воспользоваться веб-архивом. Для этого следует:
- Зайти на специализированный ресурс, о которых мы говорили ранее.
- Внести собственное доменное имя в строку поиска и открыть проект в новом окне.
- Выбрать наиболее удачный снимок, который располагается ближе к проблемной дате и имеет полноценный вид.
- Исправить внутренние ссылки на прямые. Для этого используем ссылку «http://web.archive.org/web/любой_порядковый_номер_id_/Название сайта».
- Скопировать потерянную информацию или данные дизайна, которые будут применены для восстановления.
Заметим, что процесс несколько утомительный, с учетом скорости работы архива. Поэтому рекомендуем владельцам больших веб-ресурсов чаще выполнять бэкапы, что сохранит время и нервы.
Ищем уникальный контент для собственного сайта

Некоторые веб-мастера используют интересный способ получения нового, никому не нужного контента. Ежедневно сотни сайтов уходят в небытие, а вместе с ними теряется информация. Чтобы стать владельцем контента, нужно выполнить следующее:
- Внести URL
https://www.nic.ru/auction/forbuyer/download_list.shtml#buying в строку поиска. - На сайте аукциона доменных имен скачать файлы с именем ru.
- Открыть полученные файлы с использованием excel и начать отбор по параметру наличия проектной информации.
- Найденные в списке проекты ввести на странице поиска веб-архива.
- Открыть снимок и получить доступ к информационному потоку.
Рекомендуем отслеживать контент на наличие плагиата , это позволит найти действительно достойные тексты. А на этом все! Теперь каждый знает о возможностях и методах использования веб-архива. Используйте знание с умом и выгодой.



