Backup in Windows. Backup del sistema operativo Windows su Acronis
Da virus e bug del software, guasti hardware o errori umani, ci sono molti potenziali pericoli che infettano i tuoi file.
O potrebbe succedere anche peggio, ad esempio la perdita di fotografie personali, di una libreria musicale, di importanti documenti aziendali, qualcosa che potrebbe essere davvero prezioso. Ecco perché è necessario creare automaticamente una copia di backup del tuo computer.
Farlo da soli è molto difficile, ma con il software giusto sarà molto più semplice di quanto pensi. Senza alcuna spesa monetaria, perché ce ne sono programmi gratuiti di backup e clonazione del disco.
Se lo desidera, copiare il contenuto dei tuoi documenti in qualche luogo , clonare un disco su un altro, O crea un backup dell'intero sistema, ho trovato molti programmi che possono aiutare.
Azione Backup
Action Backup è forse il miglior backup di file pianificato per computer domestici e aziendali. Il programma è molto comodo poiché combina facilità d'uso e ampie funzionalità per l'esecuzione dei backup. Con Action Backup ottieni: supporto per backup completi, differenziali e incrementali, salvataggio automatizzato* dei backup su server FTP, CD/DVD, risorse di rete remote, supporto del formato zip64, supporto per la funzione di copia shadow, lavoro in modalità servizio Windows*, cancellazione automatica degli archivi precedenti (obsoleti)*, invio di un report via e-mail e molto altro (una descrizione dettagliata della funzionalità è disponibile sul sito ufficiale dello sviluppatore).
Action Backup è perfetto sia per i principianti che per gli utenti esperti, rendendolo uno strumento eccellente per il backup di file su computer di casa, workstation e server.
* - disponibile solo nella versione a pagamento. C'è un confronto delle versioni sul sito ufficiale.
Aomei Backupper
Se ti piacciono i programmi di backup, Aomei ha un'interfaccia semplice. Selezionare l'unità o la partizione di cui eseguire il backup, l'unità di destinazione e fare clic Backupper ci sarà una creazione di immagini.

Il programma ha strumenti abbastanza buoni se ne hai bisogno. Ci sono opzioni per crittografare o comprimere i backup. Puoi creare backup incrementali o differenziali per una maggiore velocità. Puoi recuperare singoli file e cartelle o l'intera immagine e ci sono anche strumenti per clonare dischi e partizioni.
Cosa non puoi fare purtroppo Backup pianificati- devono essere lanciati manualmente. Ma altrimenti Aomei Backupperè uno strumento eccellente, con un gran numero di funzioni, ma anche facile da usare.
EASEUS Todo Backup gratuito
Come la maggior parte dei programmi software commerciali gratuiti (per uso personale), EASEUS Todo Backup gratuito ha alcune limitazioni, ma il pacchetto ha comunque funzionalità più che sufficienti per la maggior parte delle persone.
Il programma può funzionare sia su file che su file di backup, ad esempio manualmente o in base a una pianificazione. Sei in grado di lavorare con backup completi o incrementali.

La possibilità di limitare la velocità di scrittura riduce l'impatto dei backup sulle prestazioni del sistema. Ciò è possibile in singoli file o cartelle o nell'intera immagine utilizzando un programma di ripristino del disco. E ci sono anche strumenti per clonare e formattare le unità.
Il lato negativo è che non ottieni alcuna crittografia, nessun backup differenziale e ottieni solo Linux basato su disco (non Windows PE). Ma EASEUS Todo Backup Free ci sembra ancora un ottimo programma.
Ripeti backup e ripristino
Ripeti backup e ripristino —
è uno strumento di backup della visualizzazione con una differenza. Invece di installare il programma, devi scaricare un file ISO di grandi dimensioni (249 MB) e masterizzarlo su un CD o un'unità USB. Quindi avvialo da esso per avviare un semplice strumento in grado di eseguire il backup del tuo disco rigido e ripristinarlo in un secondo momento.
C'è anche uno strumento di ripristino e persino un browser Web se hai bisogno di aiuto per un problema con il PC.

Il programma non è del tutto conveniente. Non è possibile pianificare i backup, devono essere avviati tutti manualmente e ci sono pochissime opzioni.
Ma è anche facile da usare e gratuito per tutti, quindi se vuoi eseguire un backup occasionale da poter utilizzare su qualsiasi computer senza installare software, questo è il prodotto che fa per te.
Backup Cobian
Backup Cobianè un eccellente software di backup con molte funzionalità. Ottieni backup completi, differenziali e incrementali, ad esempio; Compressione ZIP o 7zip; crittografia AES a 256 bit; includere ed escludere filtri; pianificatore, backup o server FTP, E la lista continua. Ogni aspetto del programma è estremamente personalizzabile (ci sono oltre 100 parametri che puoi personalizzare).

PC o backup, i principianti molto probabilmente lo troveranno molto difficile. Se sei più esperto adorerai il numero di strumenti Backup Cobian ti dà il controllo su ogni aspetto del processo di backup.
Macrium riflette liberamente
Uno dei programmi di imaging del disco gratuiti (per uso domestico) più popolari, Macrium riflette liberamente Il set di funzioni di base tramite l'interfaccia è facile da usare.
Il programma non dispone di backup incrementali o differenziali. E non otterrai crittografia o protezione tramite password. Ciò rende tuttavia la creazione di backup molto semplice (seleziona l'unità di origine e imposta il rapporto di compressione, fatto).

C'è un pianificatore; Puoi montare le immagini in Esplora risorse o ripristinarle completamente sia da Linux che Dischi di ripristino di Windows PE. E in generale Macrium riflette liberamente Una scelta eccellente per chi desidera uno strumento di backup delle immagini semplice ma affidabile.
DriveImageXML
Gratuito per uso personale, DriveImageXMè una facile alternativa ai concorrenti più avanzati. Il backup è semplice: basta selezionare un'unità di origine, una destinazione e (opzionale) impostare il livello di compressione.
Il ripristino è altrettanto semplice e l'unico extra significativo è la possibilità di copiare direttamente da un'unità all'altra.

Ci sono alcune complicazioni altrove. Fai clic sul pulsante "Utilità di pianificazione" e riceverai istruzioni su come configurare manualmente Utilità di pianificazione di Windows per avviare il backup. Ma se hai solo bisogno di uno strumento di rendering di base, allora dai DriveImageXML maniglia.
FBackup
FBackupè un buon strumento di backup dei file, gratuito per uso personale e commerciale. L'interfaccia è semplice e chiara e sono presenti numerose funzionalità.
I plugin ti consentono di eseguire il backup di singoli programmi con un clic; è disponibile il supporto per includere ed escludere filtri; ed è possibile eseguire backup "Mirror", che copiano semplicemente tutto senza comprimerlo (il che rende molto semplice il ripristino dei file).

La compressione, però, non è altrettanto buona (è il debole Zip2) e anche lo scheduler è più semplice di quello che vedrai in altri programmi. Ma se le tue esigenze sono semplici allora FBackup dovrebbe andarti bene.
Creatore di backup
Inizialmente gratuito per uso personale BackupMaker Sembra come qualsiasi altro strumento di backup di file, con backup opzionali o completi disponibili, pianificazione, compressione, crittografia, filtri di inclusione ed esclusione e così via.
Ma servizi aggiuntivi interessanti includono il supporto per il backup online su server FTP e durante l'esecuzione eseguire il backup automaticamente quando è collegato un dispositivo USB.

Anche i dati del programma sono archiviati in file Zip, il che ne facilita l'accesso. E Creatore di backup viene fornito in un piccolo pacchetto di installazione da 6,5 Mb, molto più gestibile rispetto ad alcuni dei concorrenti più ingombranti.
Se sei un utente domestico che cerca modo per eseguire il backup dei file, quindi eseguire il backup Creatore potrebbe essere perfetto.
Clonezilla
Proprio come ripetere il backup e il ripristino, Clonezilla non l'installatore: lo è dos ambiente di avvio, che può essere eseguito da un CD o da un'unità flash USB.
Ed è anche un programma davvero potente: sarai in grado di creare un'immagine del disco; ripristinare un'immagine (su un disco o su più contemporaneamente); clonare un disco (copiare un disco su un altro), con maggiore controllo.

Sebbene Ripetizione backup e ripristino si concentri sulla facilità d'uso, tuttavia, Clonezilla ulteriori informazioni sulla fornitura di opzioni aggiuntive come "automatico" Clonezilla tramite avvio PXE." Non è difficile, probabilmente il miglior programma gratuito per clonare dischi, ma il programma è rivolto a utenti esperti di backup, per i principianti è meglio trovare un'opzione più adatta.
Paragon Backup e ripristino 2014 gratuito
Un altro programma gratuito per uso personale, Paragon Backup e ripristino 2014 gratuito
è un buon strumento, con alcune limitazioni.
Forte sostegno alla fondazione: si può creare un backup dell'immagine(completo o differenziale), comprimere e crittografare il loro utilizzo filtri di esclusione per aiutare a determinare cosa è incluso, farlo backup pianificati, quindi ripristinare singoli file e cartelle o tutti.

Include inoltre una sezione separata per mantenere i backup al sicuro. È inclusa una buona serie di sezioni di strumenti di base.
I problemi? Non otterrai backup incrementali; Non puoi clonare dischi o partizioni e l'interfaccia a volte non sembra molto buona. Tuttavia Paragon Backup e ripristino 20134 gratuito Uno strumento di qualità e merita la tua attenzione.
Duplicare
Se hai bisogno di backup online allora Duplicareè uno degli strumenti più versatili, con supporto per il salvataggio dei file SkyDrive, Google Docs, server FTP, Amazon S3, Rackspace Cloudfiles e WebDAV.

Il programma può anche salvare su unità locali e di rete, sebbene includa molte opzioni utili (crittografia AES-256, protezione tramite password, pianificazione, backup completi e incrementali, supporto delle espressioni regolari per includere/escludere filtri, persino limiti di velocità di caricamento e download per ridurre l'impatto sul sistema).
Sia che salvi file online o localmente, questo programma fa per te.
ALEXEY BEREZHNOY, Amministratore di sistema. Principali aree di attività: virtualizzazione e reti eterogenee. Un altro hobby oltre alla scrittura di articoli è la divulgazione del software libero
Backup
Teoria e pratica. Riepilogo
Per organizzare un sistema di backup nel modo più efficace è necessario costruire una vera e propria strategia di salvataggio e ripristino delle informazioni
Il backup (o, come viene anche chiamato, backup - dalla parola inglese "backup") è un processo importante nella vita di qualsiasi struttura IT. È un paracadute per il salvataggio in caso di disastro imprevisto. Allo stesso tempo, il backup viene utilizzato per creare una sorta di archivio storico delle attività aziendali di un'azienda durante un determinato periodo della sua vita. Lavorare senza un backup è come vivere a cielo aperto: il tempo può peggiorare in qualsiasi momento e non c'è nessun posto dove nascondersi. Ma come organizzarlo correttamente per non perdere dati importanti e non spendere cifre esorbitanti?
In genere, gli articoli sul tema dell'organizzazione dei backup discutono principalmente soluzioni tecniche e solo occasionalmente prestano attenzione alla teoria e alla metodologia di organizzazione dell'archiviazione dei dati.
In questo articolo parleremo esattamente del contrario: l'attenzione principale è rivolta ai concetti generali e i mezzi tecnici saranno toccati solo come esempi. Ciò ci consentirà di astrarre dall’hardware e dal software e rispondere a due domande principali: “Perché lo stiamo facendo?”, “Possiamo farlo più velocemente, in modo più economico e in modo più affidabile?”
Scopi e obiettivi del backup
Nel processo di organizzazione di un backup vengono fissati due compiti principali: ripristinare l'infrastruttura in caso di guasti (Disaster Recovery) e mantenere un archivio dati per poter successivamente fornire accesso alle informazioni per i periodi passati.
Un classico esempio di copia di backup per Disaster Recovery è un'immagine della partizione di sistema del server creata da Acronis True Image.
Un esempio di archivio potrebbe essere il download mensile dei database da 1C, registrati su cassette e la successiva archiviazione in un luogo appositamente designato.
Esistono diversi fattori che differenziano un backup di ripristino rapido da un archivio:
- Periodo di conservazione dei dati. Per le copie d'archivio ci vuole molto tempo. In alcuni casi, è regolato non solo dai requisiti aziendali, ma anche dalla legge. Per le copie di ripristino di emergenza è relativamente piccolo. Di solito creano una o due copie di backup (con requisiti di affidabilità maggiori) per il Disaster Recovery con un intervallo massimo di uno o due giorni, dopodiché vengono sovrascritte con quelle nuove. In casi particolarmente critici è possibile aggiornare la copia di backup più frequentemente per il disaster recovery, ad esempio una volta ogni poche ore.
- Accesso rapido ai dati. Nella maggior parte dei casi la velocità di accesso a un archivio a lungo termine non è fondamentale. In genere, la necessità di "aggiornare i dati per un periodo" nasce al momento della riconciliazione dei documenti, del ritorno a una versione precedente, ecc., Cioè non in modalità di emergenza. Un'altra cosa è il disaster recovery, quando i dati necessari e le prestazioni del servizio devono essere restituiti il prima possibile. In questo caso, la velocità di accesso al backup è un indicatore estremamente importante.
- Composizione delle informazioni copiate. La copia di backup contiene in genere solo dati utente e aziendali per un periodo specificato. Oltre a questi dati, la copia destinata al ripristino di emergenza contiene immagini di sistema o copie delle impostazioni del sistema operativo e del software applicativo, nonché altre informazioni necessarie per il ripristino.
A volte è possibile combinare questi compiti. Ad esempio, un anno di snapshot completi mensili di un file server, oltre alle modifiche apportate durante la settimana. True Image è uno strumento adatto per creare tale backup.
La cosa più importante è capire chiaramente il motivo per cui viene effettuata la prenotazione. Lasciatemi fare un esempio: un server SQL critico si è guastato a causa di un guasto dell'array di dischi. Abbiamo in magazzino l'hardware corretto, quindi l'unica soluzione era recuperare il software e i dati. La direzione dell'azienda pone una domanda comprensibile: "Quando inizierà a funzionare?" – ed è spiacevolmente sorpreso di apprendere che ci vorranno quattro ore intere per riprendersi. Il fatto è che durante l'intera vita utile del server, è stato eseguito regolarmente il backup solo dei database, senza tener conto della necessità di ripristinare il server stesso con tutte le impostazioni, incluso il software DBMS stesso. In poche parole, i nostri eroi hanno solo salvato i database e si sono dimenticati del sistema.
Lascia che ti faccia un altro esempio. Durante l'intero periodo del suo lavoro, il giovane specialista ha creato, utilizzando il programma ntbackup, un'unica copia del file server con Windows Server 2003, inclusi i dati e lo stato del sistema in una cartella condivisa su un altro computer. A causa dello spazio su disco limitato, questa copia veniva costantemente sovrascritta. Dopo qualche tempo, gli è stato chiesto di ripristinare una versione precedente di un rapporto di più pagine che era stato danneggiato durante il salvataggio. È evidente che, non avendo la cronologia archiviata con la Copia Shadow disattivata, non è stato in grado di portare a termine tale richiesta.
|
In una nota Copia ombra, letteralmente – “copia ombra”. Garantisce che vengano create copie istantanee del file system in modo tale che ulteriori modifiche all'originale non abbiano alcun effetto su di esse. Utilizzando questa funzionalità, è possibile creare più copie nascoste di un file per un certo periodo di tempo, nonché copie di backup al volo di file aperti per la scrittura. Il servizio Shadow Copy del volume è responsabile del funzionamento della copia shadow. Stato del sistema, letteralmente – “stato del sistema”. System State Copy crea copie di backup di componenti critici dei sistemi operativi Windows. Ciò consente di ripristinare un sistema precedentemente installato dopo la distruzione. Quando si copia lo stato del sistema, vengono salvati il registro, l'avvio e altri file importanti per il sistema, inclusi per il ripristino Active Directory, il database del Servizio certificati, il database di registrazione COM+Class e la directory SYSVOL. Nei sistemi operativi UNIX, un'analogia indiretta della copia dello stato del sistema è il salvataggio del contenuto delle directory /etc, /usr/local/etc e di altri file necessari per ripristinare lo stato del sistema. |
Ciò ne consegue: è necessario utilizzare entrambi i tipi di backup: sia per il ripristino di emergenza che per l'archiviazione. In questo caso è necessario determinare l'elenco delle risorse copiate, il tempo di esecuzione delle attività, nonché dove, come e per quanto tempo verranno archiviate le copie di backup.
Con piccole quantità di dati e un'infrastruttura IT non molto complessa, puoi provare a combinare entrambe queste attività in una, ad esempio, creando una copia completa giornaliera di tutte le partizioni del disco e dei database. Ma è ancora meglio distinguere tra due obiettivi e scegliere i mezzi giusti per ciascuno di essi. Di conseguenza, per ogni attività viene utilizzato uno strumento diverso, sebbene esistano anche soluzioni universali, come il pacchetto Acronis True Image o il programma ntbackup
È chiaro che quando si definiscono gli scopi e gli obiettivi del backup, nonché le soluzioni per l'implementazione, è necessario procedere dai requisiti aziendali.
Quando si implementa un'attività di ripristino di emergenza, è possibile utilizzare strategie diverse.
In alcuni casi, è necessario ripristinare direttamente il sistema allo stato bare metal. Ciò può essere fatto, ad esempio, utilizzando il programma Acronis True Image completo del modulo Universal Restore. In questo caso la configurazione del server può essere rimessa in funzione in brevissimo tempo. Ad esempio, è possibile ripristinare una partizione con un sistema operativo da 20 GB da un backup in otto minuti (a condizione che la copia di backup sia accessibile tramite una rete da 1 Gb/s).
In un'altra opzione è più opportuno semplicemente "restituire" le impostazioni al sistema appena installato, come ad esempio copiare i file di configurazione dalla cartella /etc e altri nei sistemi simili a UNIX (in Windows ciò corrisponde grosso modo alla copia e ripristino dello stato del sistema). Naturalmente, con questo approccio, il server verrà messo in funzione non prima dell'installazione del sistema operativo e del ripristino delle impostazioni necessarie, il che richiederà molto più tempo. In ogni caso, la decisione sul tipo di Disaster Recovery da adottare dipende dalle esigenze aziendali e dai limiti delle risorse.
La differenza fondamentale tra sistemi di backup e ridondanti
Questa è un’altra questione interessante che vorrei sollevare. I sistemi di ridondanza delle apparecchiature ridondanti implicano l'introduzione di una certa ridondanza nell'hardware al fine di mantenere la funzionalità in caso di guasto improvviso di uno dei componenti. Un ottimo esempio in questo caso è un array RAID (Redundant Array of Independent Disks). In caso di guasto di un disco, è possibile evitare la perdita di informazioni e sostituirlo in sicurezza, salvando i dati grazie all'organizzazione specifica dell'array di dischi stesso (maggiori informazioni su RAID in).
Ho sentito la frase: "Abbiamo apparecchiature molto affidabili, abbiamo array RAID ovunque, quindi non abbiamo bisogno di backup". Sì, certo, lo stesso array RAID proteggerà i dati dalla distruzione in caso di guasto di un disco rigido. Ma questo non ti salverà dal danneggiamento dei dati causato da un virus informatico o da azioni inette dell'utente. RAID non ti salverà se il file system collassa a causa di un riavvio non autorizzato.
|
A proposito L'importanza di distinguere il backup dai sistemi ridondanti dovrebbe essere valutata quando si elabora un piano per la copia dei dati, sia che si tratti di un'organizzazione che di computer domestici. Chiediti perché stai facendo delle copie. Se parliamo di backup, significa salvare i dati durante un'azione accidentale (intenzionale). La ridondanza ridondante consente di salvare i dati, comprese le copie di backup, in caso di guasto dell'apparecchiatura. Ora sul mercato sono disponibili molti dispositivi economici che forniscono un backup affidabile utilizzando array RAID o tecnologie cloud (ad esempio Amazon S3). Si consiglia di utilizzare entrambi i tipi di backup delle informazioni contemporaneamente. Andrey Vasiliev, CEO di Qnap Russia |
Lascia che ti faccia un esempio. Ci sono casi in cui gli eventi si sviluppano secondo il seguente scenario: quando un disco si guasta, i dati vengono ripristinati attraverso un meccanismo di ridondanza, in particolare utilizzando i checksum salvati. In questo caso, si verifica un calo significativo delle prestazioni, il server si blocca e il controllo viene quasi perso. L'amministratore di sistema, non vedendo altra via d'uscita, riavvia il server con un riavvio a freddo (in altre parole, fa clic su "RESET"). Come risultato di tale sovraccarico, si verificano errori del file system. La cosa migliore che ci si può aspettare in questo caso è che il programma di controllo del disco verrà eseguito a lungo per ripristinare l'integrità del file system. Nel peggiore dei casi, dovrai dire addio al file system e chiederti dove, come e in quale lasso di tempo ripristinare i dati e le prestazioni del server.
Non potrai evitare i backup anche se disponi di un'architettura cluster. Un cluster di failover, in sostanza, mantiene la funzionalità dei servizi affidatigli nel caso in cui uno dei server si guasti. In caso dei problemi di cui sopra, come un attacco di virus o il danneggiamento dei dati a causa del famigerato "fattore umano", nessun cluster ti salverà.
L'unica cosa che può fungere da sostituto inferiore del backup per il Disaster Recovery è la presenza di un server di backup mirror con replica costante dei dati dal server principale a quello di backup (secondo il principio Primario Standby). In questo caso, se il server principale si guasta, i suoi compiti verranno assunti da quello di backup e non dovrai nemmeno trasferire i dati. Ma organizzare un sistema del genere è piuttosto costoso e richiede molto lavoro. Non dimentichiamoci della necessità di una replica costante.
Diventa chiaro che una tale soluzione è economicamente vantaggiosa solo nel caso di servizi critici con elevati requisiti di tolleranza agli errori e tempi di ripristino minimi. Di norma, tali schemi vengono utilizzati in organizzazioni molto grandi con un elevato turnover di materie prime e contanti. E questo schema è un sostituto scadente del backup perché, in ogni caso, se i dati vengono danneggiati da un virus informatico, da azioni inadeguate dell'utente o da un funzionamento errato dell'applicazione, i dati e il software su entrambi i server potrebbero risentirne.
E, naturalmente, nessun sistema di backup ridondante risolverà il problema della conservazione dell'archivio dati per un certo periodo.
Il concetto di “finestra di backup”
L'esecuzione di un backup comporta un carico pesante sul server sottoposto a backup. Ciò è particolarmente vero per il sottosistema del disco e le connessioni di rete. In alcuni casi, quando il processo di copia ha una priorità piuttosto alta, ciò può portare all'indisponibilità di alcuni servizi. Inoltre, la copia dei dati al momento di apportare modifiche è associata a notevoli difficoltà. Naturalmente, in questo caso esistono mezzi tecnici per evitare problemi mantenendo l'integrità dei dati, ma se possibile è meglio evitare tale copia al volo.
La soluzione per risolvere questi problemi sopra descritti suggerisce se stessa: posticipare l'inizio del processo di creazione della copia a un periodo di tempo inattivo, quando l'influenza reciproca del backup e degli altri sistemi in esecuzione sarà minima. Questo periodo di tempo è chiamato “finestra di backup”. Ad esempio, per un'organizzazione che opera con la formula 8x5 (cinque giorni lavorativi di otto ore a settimana), tale "finestra" corrisponde solitamente ai fine settimana e alle ore notturne.
Per i sistemi che funzionano secondo la formula 24x7 (tutta la settimana 24 ore su 24), il periodo di attività minima viene utilizzato come periodo in cui non c'è carico elevato sui server.
Tipi di backup
Per evitare inutili costi materiali durante l'organizzazione dei backup e, se possibile, anche per non andare oltre la finestra di backup, sono state sviluppate diverse tecnologie di backup, che vengono utilizzate a seconda della situazione specifica.
Backup completo (o Backup completo)
È il metodo principale e fondamentale per creare copie di backup, in cui l'array di dati selezionato viene copiato interamente. Questo è il tipo di backup più completo e affidabile, sebbene sia il più costoso. Se è necessario salvare più copie di dati, il volume totale memorizzato aumenterà in proporzione al loro numero. Per evitare tali sprechi vengono utilizzati algoritmi di compressione e una combinazione di questo metodo con altri tipi di backup: incrementale o differenziale. E, naturalmente, un backup completo è indispensabile quando è necessario preparare una copia di backup per ripristinare rapidamente il sistema da zero.
Copia incrementale
A differenza di un backup completo, in questo caso non vengono copiati tutti i dati (file, settori, ecc.), ma solo quelli che sono cambiati rispetto all'ultima copia. È possibile utilizzare diversi metodi per determinare l'ora del backup, ad esempio, sui sistemi che eseguono sistemi operativi Windows viene utilizzato un attributo di file corrispondente (bit di archivio), che viene impostato quando il file viene modificato e ripristinato dal programma di backup. Altri sistemi potrebbero utilizzare la data in cui il file è stato modificato. È chiaro che uno schema che utilizza questo tipo di backup risulterà incompleto se di tanto in tanto non viene eseguito un backup completo. Quando si esegue un ripristino completo del sistema, è necessario ripristinare dall'ultima copia creata dal backup completo e quindi alternativamente "rieseguire il rollup" dei dati dalle copie incrementali nell'ordine in cui sono state create.
A cosa serve questo tipo di copia? Nel caso di creazione di copie di archivio, è necessario ridurre i volumi consumati sui dispositivi di archiviazione (ad esempio, ridurre il numero di supporti nastro utilizzati). Ciò ridurrà anche al minimo il tempo necessario per completare le attività di backup, che può essere estremamente importante in condizioni in cui è necessario lavorare con un programma intenso 24 ore su 24, 7 giorni su 7 o pompare grandi volumi di informazioni.
C'è un avvertimento sulla copia incrementale che devi conoscere. Il ripristino passo passo restituisce inoltre i file eliminati necessari durante il periodo di recupero. Lasciate che vi faccia un esempio. Diciamo che viene eseguita una copia completa nei fine settimana e una incrementale nei giorni feriali. L'utente ha creato un file lunedì, lo ha modificato martedì, lo ha rinominato mercoledì e lo ha eliminato giovedì. Quindi, con un recupero dati sequenziale e passo passo per un periodo settimanale, riceveremo due file: con il vecchio nome martedì prima della ridenominazione e con un nuovo nome creato mercoledì. Ciò è accaduto perché diverse copie incrementali memorizzavano versioni diverse dello stesso file e alla fine tutte le versioni sarebbero state ripristinate. Pertanto, quando si ripristinano in sequenza i dati da un archivio “così come sono”, è opportuno riservare più spazio su disco in modo che possano adattarsi anche ai file eliminati.
Backup differenziale
Si differenzia da quello incrementale in quanto i dati vengono copiati dall'ultimo momento del backup completo. I dati vengono conservati nell'archivio su “base cumulativa”. Sui sistemi della famiglia Windows, questo effetto è ottenuto dal fatto che il bit di archivio non viene reimpostato durante la copia differenziale, quindi i dati modificati finiscono nella copia di archivio finché una copia completa non reimposta i bit di archivio.
Dato che ogni nuova copia creata in questo modo contiene i dati della precedente, è più conveniente ripristinare completamente i dati al momento del disastro. Per fare questo, hai solo bisogno di due copie: quella completa e l'ultima di quelle differenziali, così puoi riportare in vita i dati molto più velocemente rispetto all'implementazione graduale di tutti gli incrementi. Inoltre, questo tipo di copia è esente dalle funzionalità sopra menzionate della copia incrementale, quando, con un ripristino completo, i vecchi file, come un uccello fenice, rinascono dalle ceneri. C'è meno confusione.
Ma la copia differenziale è significativamente inferiore alla copia incrementale nel risparmiare lo spazio richiesto. Poiché ogni nuova copia memorizza i dati delle precedenti, il volume totale dei dati riservati può essere paragonabile a una copia completa. E, naturalmente, quando si pianifica la pianificazione (e si calcola se il processo di backup si adatterà alla finestra temporale), è necessario tenere conto del tempo necessario per creare l'ultima copia differenziale, più spessa.
Topologia di backup
Diamo un'occhiata a quali schemi di backup esistono.
Schema decentralizzato
Il nucleo di questo schema è una determinata risorsa di rete condivisa (vedi Fig. 1). Ad esempio, una cartella condivisa o un server FTP. È inoltre necessaria una serie di programmi di backup che di tanto in tanto caricano informazioni da server e workstation, nonché altri oggetti di rete (ad esempio file di configurazione dai router) su questa risorsa. Questi programmi sono installati su ciascun server e funzionano indipendentemente l'uno dall'altro. Un indubbio vantaggio è la facilità di implementazione di questo schema e il suo basso costo. Come programmi di copia sono adatti strumenti standard integrati nel sistema operativo o software come un DBMS. Ad esempio, potrebbe trattarsi del programma ntbackup per la famiglia Windows, del programma tar per sistemi operativi simili a UNIX o di un insieme di script contenenti comandi SQL server incorporati per scaricare i database nei file di backup. Un altro vantaggio è la possibilità di utilizzare vari programmi e sistemi, purché tutti possano accedere alla risorsa di destinazione per archiviare le copie di backup.
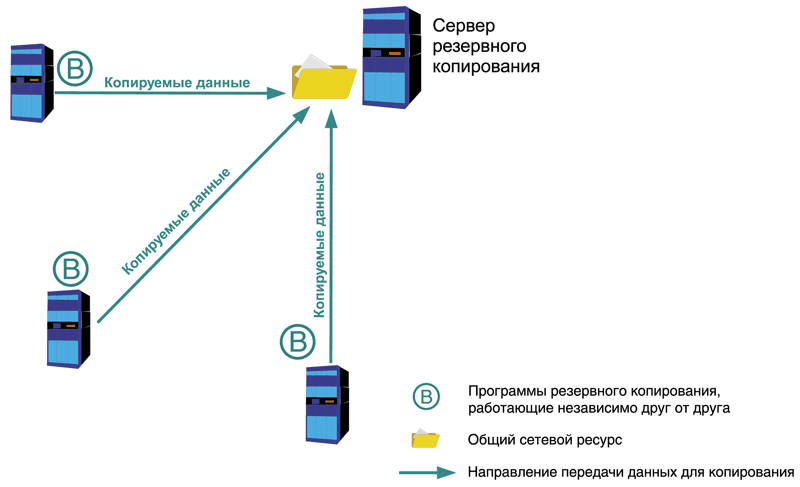
Lo svantaggio è la goffaggine di questo schema. Poiché i programmi vengono installati indipendentemente l'uno dall'altro, ciascuno deve essere configurato separatamente. È abbastanza difficile tenere conto delle peculiarità del programma e distribuire gli intervalli di tempo per evitare concorrenza per la risorsa target. Anche il monitoraggio è difficile; il processo di copia da ciascun server deve essere monitorato separatamente dagli altri, il che a sua volta può comportare elevati costi di manodopera.
Pertanto, questo schema viene utilizzato nelle reti di piccole dimensioni, nonché in situazioni in cui è impossibile organizzare uno schema di backup centralizzato utilizzando i mezzi disponibili. Una descrizione più dettagliata di questo schema e dell'organizzazione pratica può essere trovata in.
Backup centralizzato
A differenza dello schema precedente, in questo caso viene utilizzato un modello gerarchico chiaro, che funziona secondo il principio client-server. Nella versione classica, su ciascun computer vengono installati programmi agente speciali e il modulo server del pacchetto software è installato sul server centrale. Questi sistemi dispongono anche di una console di gestione backend specializzata. Lo schema di controllo è il seguente: dalla console creiamo attività di copia, ripristino, raccolta di informazioni di sistema, diagnostica e così via, e il server fornisce agli agenti le istruzioni necessarie per eseguire queste operazioni.
È su questo principio che funzionano i sistemi di backup più diffusi, come Symantec Backup Exec, CA Bright Store ARCServe Backup, Bacula e altri (vedere Fig. 2).

Oltre a diversi agenti per la maggior parte dei sistemi operativi, esistono sviluppi per il backup dei database più diffusi e dei sistemi aziendali, ad esempio per MS SQL Server, MS Exchange, Oracle Database e così via.
Per le aziende molto piccole, in alcuni casi è possibile provare una versione semplificata di uno schema di backup centralizzato senza l'uso di programmi agente (vedere Fig. 3). Questo schema può essere utilizzato anche se non è implementato un agente speciale per il software di backup utilizzato. Il modulo server utilizzerà invece i servizi già esistenti. Ad esempio, "scrape" dati da cartelle condivise nascoste su server Windows o copia file tramite SSH da server che eseguono sistemi UNIX. Questo schema presenta limitazioni molto significative associate ai problemi di salvataggio dei file aperti per la scrittura. Come risultato di tali azioni, i file aperti verranno ignorati e non inclusi nella copia di backup oppure copiati con errori. Esistono varie soluzioni alternative a questo problema, ad esempio eseguire nuovamente il processo per copiare solo i file aperti in precedenza, ma nessuna è affidabile. Pertanto, questo schema è adatto all'uso solo in determinate situazioni. Ad esempio, nelle piccole organizzazioni che lavorano in modalità 5x8, con dipendenti disciplinati che salvano le modifiche e chiudono i file prima di tornare a casa. ntbackup è una buona scelta per organizzare uno schema centralizzato così troncato che funziona esclusivamente in ambiente Windows. Se hai bisogno di utilizzare uno schema simile in ambienti eterogenei o esclusivamente tra computer UNIX, ti consiglio di orientarti verso Backup PC (vedi).
Figura 4. Schema di backup misto
Cosa è fuori sede?
Nel nostro mondo turbolento e in continua evoluzione possono verificarsi eventi che possono causare conseguenze spiacevoli per l’infrastruttura IT e per l’azienda nel suo complesso. Ad esempio, un incendio in un edificio. Oppure un guasto alla batteria del riscaldamento centrale nella sala server. Oppure il banale furto di attrezzature e componenti. Un metodo per evitare la perdita di informazioni in tali situazioni consiste nell'archiviare i backup in una posizione lontana dalla posizione principale. apparecchiature server. Allo stesso tempo, è necessario fornire un modo rapido per accedere ai dati necessari per il ripristino. Il metodo descritto è chiamato off-site (in altre parole, archiviazione di copie al di fuori del territorio dell'impresa). Fondamentalmente vengono utilizzati due metodi per organizzare questo processo.
Scrittura di dati su supporti rimovibili e spostamento fisico. In questo caso, è necessario considerare un modo per ripristinare rapidamente i media in caso di guasto. Ad esempio, conservali in un edificio vicino. Il vantaggio di questo metodo è la capacità di organizzare questo processo senza alcuna difficoltà. Lo svantaggio è la difficoltà di restituire i supporti e la necessità stessa di trasferire le informazioni per l'archiviazione, nonché il rischio di danneggiare i supporti durante il trasporto.
Copia dei dati in un'altra posizione tramite un collegamento di rete. Ad esempio, utilizzando un tunnel VPN su Internet. Il vantaggio in questo caso è che non è necessario trasportare i media con le informazioni da qualche parte, lo svantaggio è la necessità di utilizzare un canale sufficientemente ampio (di norma è molto costoso) e proteggere i dati trasmessi (ad esempio utilizzando il canale stessa VPN). Le difficoltà incontrate nel trasferimento di grandi volumi di dati possono essere notevolmente ridotte utilizzando algoritmi di compressione o tecnologie di deduplicazione.
Vale la pena menzionare separatamente le misure di sicurezza nell'organizzazione dell'archiviazione dei dati. Innanzitutto occorre garantire che i supporti dati si trovino in un'area sicura e che siano adottate misure per impedire la lettura dei dati da parte di persone non autorizzate. Ad esempio, utilizzare un sistema di crittografia, stipulare accordi di non divulgazione e così via. Se si utilizza un supporto rimovibile, anche i dati su di esso devono essere crittografati. Il sistema di etichettatura utilizzato non dovrebbe aiutare l'aggressore nell'analisi dei dati. È necessario utilizzare uno schema di numerazione senza volto per contrassegnare i supporti dei nomi dei file trasferiti. Quando si trasferiscono dati in rete, è necessario (come già menzionato sopra) utilizzare metodi di trasferimento dati sicuri, ad esempio un tunnel VPN.
Abbiamo discusso i punti principali quando si organizza un backup. La parte successiva discuterà le raccomandazioni metodologiche e fornirà esempi pratici per creare un sistema di backup efficace.
- Descrizione del backup in Windows, incluso System State: http://www.datamills.com/Tutorials/systemstate/tutorial.htm.
- Descrizione della copia shadow - http://ru.wikipedia.org/wiki/Shadow_Copy.
- Sito Web ufficiale Acronis: http://www.acronis.ru/enterprise/products.
- Descrizione di ntbackup - http://en.wikipedia.org/wiki/NTBackup.
- Berezhnoy A. Ottimizzazione del funzionamento di MS SQL Server. //Amministratore di sistema, n. 1, 2008 – pp. 14-22 ().
- Berezhnoy A. Organizziamo un sistema di backup per uffici di piccole e medie dimensioni. //Amministratore di sistema, n. 6, 2009 – pp. 14-23 ().
- Markelov A. Linux a guardia di Windows. Revisione e installazione del sistema di backup BackupPC. //Amministratore di sistema, N. 9, 2004 – P. 2-6 ().
- Descrizione della VPN – http://ru.wikipedia.org/wiki/VPN.
- Deduplicazione dei dati - http://en.wikipedia.org/wiki/Data_deduplication.
In contatto con
La preparazione di un nuovo server per il funzionamento dovrebbe iniziare con la configurazione del backup. Sembra che tutti lo sappiano, ma a volte anche gli amministratori di sistema esperti commettono errori imperdonabili. E il punto qui non è solo che il compito di creare un nuovo server deve essere risolto molto rapidamente, ma anche che non è sempre chiaro quale metodo di backup utilizzare.
Certo, è impossibile creare un metodo ideale che vada bene per tutti: ogni cosa ha i suoi pro e i suoi contro. Ma allo stesso tempo sembra abbastanza realistico scegliere il metodo che meglio si adatta alle specificità di un particolare progetto.
Quando si sceglie un metodo di backup, è necessario innanzitutto prestare attenzione ai seguenti criteri:
- Velocità (tempo) del backup nello spazio di archiviazione;
- Velocità (tempo) di ripristino da una copia di backup;
- Quante copie possono essere conservate con una dimensione di archiviazione limitata (server di archiviazione di backup);
- Il volume dei rischi dovuti all'incoerenza delle copie di backup, al metodo non sviluppato di eseguire i backup, alla perdita completa o parziale dei backup;
- Costi generali: livello di carico creato sul server durante l'esecuzione di una copia, diminuzione della velocità di risposta del servizio, ecc.
- Costo del noleggio di tutti i servizi utilizzati.
In questo articolo parleremo dei principali metodi per eseguire il backup dei server che eseguono sistemi Linux e dei problemi più comuni che i principianti potrebbero incontrare in questa importantissima area dell'amministrazione di sistema.
Schema per l'organizzazione dell'archiviazione e del ripristino dalle copie di backup
Quando si sceglie uno schema organizzativo per il metodo di backup, è necessario prestare attenzione ai seguenti punti fondamentali:- I backup non possono essere archiviati nella stessa posizione dei dati di cui viene eseguito il backup. Se archivi un backup sullo stesso array di dischi dei tuoi dati, lo perderai se l'array di dischi principale è danneggiato.
- Il mirroring (RAID1) non può essere paragonato al backup. Il raid ti protegge solo da un problema hardware con uno dei dischi (e prima o poi si verificherà un problema del genere, poiché il sottosistema del disco è quasi sempre il collo di bottiglia sul server). Inoltre, quando si utilizzano raid hardware esiste il rischio di guasto del controller, ad es. è necessario conservarne un modello di riserva.
- Se archivi i backup all'interno di un rack in un DC o semplicemente all'interno di un DC, in questa situazione ci sono anche alcuni rischi (puoi leggere a riguardo, ad esempio,.
- Se si archiviano copie di backup in controller di dominio diversi, i costi di rete e la velocità di ripristino da una copia remota aumentano notevolmente.
Spesso il motivo del ripristino dei dati è il danneggiamento del file system o dei dischi. Quelli. i backup devono essere archiviati da qualche parte su un server di archiviazione separato. In questo caso il problema potrebbe essere la “larghezza” del canale di trasmissione dati. Se disponi di un server dedicato, è altamente consigliabile eseguire i backup su un'interfaccia di rete separata e non sulla stessa che scambia dati con i client. Altrimenti, le richieste del tuo cliente potrebbero non “entrare” nel canale di comunicazione limitato. Oppure, a causa del traffico dei clienti, i backup non verranno eseguiti in tempo.
Successivamente, è necessario pensare allo schema e ai tempi di recupero dei dati in termini di archiviazione dei backup. Potresti essere abbastanza soddisfatto del completamento di un backup in 6 ore di notte su una struttura di archiviazione con una velocità di accesso limitata, ma è improbabile che un ripristino in 6 ore sia adatto a te. Ciò significa che l’accesso alle copie di backup dovrebbe essere comodo e che i dati dovrebbero essere copiati abbastanza velocemente. Quindi, ad esempio, il ripristino di 1 TB di dati con una larghezza di banda di 1 Gb/s richiederà quasi 3 ore, e questo se non si è limitati dalle prestazioni del sottosistema del disco nello storage e nel server. E non dimenticare di aggiungere a questo il tempo necessario per rilevare il problema, il tempo necessario per decidere di eseguire il rollback, il tempo necessario per verificare l'integrità dei dati recuperati e la quantità di successiva insoddisfazione tra clienti/colleghi .
Backup incrementale
A incrementale il backup copia solo i file che sono cambiati rispetto al backup precedente. I successivi backup incrementali aggiungono solo i file che sono cambiati rispetto a quello precedente. In media, i backup incrementali richiedono meno tempo perché vengono copiati meno file. Tuttavia, il processo di ripristino dei dati richiede più tempo poiché è necessario ripristinare i dati dell'ultimo backup completo, oltre ai dati di tutti i successivi backup incrementali. In questo caso, a differenza della copia differenziale, i file modificati o nuovi non sostituiscono quelli vecchi, ma vengono aggiunti al supporto in modo indipendente.
La copia incrementale viene spesso eseguita utilizzando l'utilità rsync. Con il suo aiuto, puoi risparmiare spazio di archiviazione se il numero di modifiche al giorno non è molto elevato. Se i file modificati sono di grandi dimensioni, verranno copiati completamente senza sostituire le versioni precedenti.
Il processo di backup tramite rsync può essere suddiviso nei seguenti passaggi:
- Viene compilato un elenco di file sul server ridondante e nell'archivio, per ciascun file vengono letti i metadati (autorizzazioni, ora di modifica, ecc.) o un checksum (quando si utilizza la chiave —checksum).
- Se i metadati dei file differiscono, il file viene diviso in blocchi e per ciascun blocco viene calcolato un checksum. I blocchi che differiscono vengono caricati nell'archivio.
- Se viene apportata una modifica al file durante il calcolo del checksum o il trasferimento del file, il backup verrà ripetuto dall'inizio.
- Per impostazione predefinita, rsync trasferisce i dati tramite SSH, il che significa che ogni blocco di dati viene ulteriormente crittografato. Rsync può anche essere eseguito come demone e trasferire dati senza crittografia utilizzando il suo protocollo.
Informazioni più dettagliate su come funziona rsync possono essere trovate sul sito ufficiale.
Per ogni file, rsync esegue un numero molto elevato di operazioni. Se sul server sono presenti molti file o se il processore è molto caricato, la velocità di backup sarà notevolmente ridotta.
Per esperienza possiamo dire che i problemi sui dischi SATA (RAID1) iniziano dopo circa 200G di dati sul server. In effetti, tutto, ovviamente, dipende dal numero di inode. E in ogni caso, questo valore può spostarsi nell'una o nell'altra direzione.
Dopo un certo punto, il tempo di esecuzione del backup sarà molto lungo o semplicemente non verrà completato in un giorno.
Per non confrontare tutti i file, c'è lsyncd. Questo demone raccoglie informazioni sui file modificati, ad es. ne avremo già un elenco pronto per la sincronizzazione in anticipo. Tuttavia, è necessario tenere presente che ciò comporta un carico aggiuntivo sul sottosistema del disco.
Backup differenziale
A differenziale In un backup, viene eseguito ogni volta il backup di ogni file modificato dall'ultimo backup completo. La copia differenziale accelera il processo di ripristino. Tutto ciò di cui hai bisogno è l'ultimo backup completo e differenziale più recente. I backup differenziali stanno diventando sempre più popolari poiché tutte le copie dei file vengono eseguite in determinati momenti, il che è molto importante, ad esempio, in caso di infezione da virus.
Il backup differenziale viene eseguito, ad esempio, utilizzando un'utilità come rdiff-backup. Quando si lavora con questa utility, si presentano gli stessi problemi dei backup incrementali.
In generale, se si esegue una ricerca completa del file cercando differenze nei dati, i problemi di questo tipo di backup sono simili ai problemi con rsync.
Vorremmo notare separatamente che se nello schema di backup ogni file viene copiato separatamente, vale la pena eliminare/escludere i file che non ti servono. Ad esempio, potrebbero trattarsi di cache CMS. Tali cache contengono solitamente molti file di piccole dimensioni, la cui perdita non influirà sul corretto funzionamento del server.
Backup completo
Un backup completo di solito influisce sull'intero sistema e su tutti i file. I backup settimanali, mensili e trimestrali comportano la creazione di una copia completa di tutti i dati. Di solito viene eseguito il venerdì o durante il fine settimana, quando la copia di una grande quantità di dati non influisce sul lavoro dell'organizzazione. I backup successivi, eseguiti dal lunedì al giovedì fino al successivo backup completo, possono essere differenziali o incrementali, principalmente per risparmiare tempo e spazio di archiviazione. I backup completi dovrebbero essere eseguiti almeno settimanalmente.
La maggior parte delle pubblicazioni correlate consiglia di eseguire un backup completo una o due volte alla settimana e di utilizzare backup incrementali e differenziali per il resto del tempo. C'è una ragione per questo consiglio. Nella maggior parte dei casi è sufficiente un backup completo una volta alla settimana. Ha senso eseguirlo nuovamente se non si ha la possibilità di aggiornare un backup completo lato storage e di garantire la correttezza della copia di backup (questo potrebbe essere necessario, ad esempio, nei casi in cui per un motivo o per l'altro si non fidarti degli script che hai o del software di backup.
Infatti, un backup completo può essere diviso in 2 parti:
- Backup completo a livello di file system;
- Backup completo a livello di dispositivo.
Diamo un'occhiata alle loro caratteristiche usando un esempio:
root@komarov:~# df -h Dimensione file system utilizzata Divail Usa% Montato su /dev/mapper/komarov_system-root 3.4G 808M 2.4G 25% / /dev/mapper/komarov_system-home 931G 439G 493G 48% /home udev 383M 4.0K 383M 1% /dev tmpfs 107M 104K 107M 1% /run tmpfs 531M 0 531M 0% /tmp nessuno 5.0M 0 5.0M 0% /run/lock nessuno 531M 0 531M 0% /run/shm /dev/xvda1 138M 22M 109M 17% /avvio
Prenoteremo solo /casa. Tutto il resto può essere rapidamente ripristinato manualmente. Puoi anche distribuire un server con un sistema di gestione della configurazione e connettere la nostra /home ad esso.
Backup completo a livello di file system
Rappresentante tipico: discarica.L'utilità crea un "dump" del file system. È possibile creare non solo un backup completo, ma anche incrementale. dump funziona con la tabella degli inode e "comprende" la struttura dei file (quindi i file sparsi vengono compressi).
Il dump di un file system in esecuzione è "stupido e pericoloso" perché il file system potrebbe cambiare durante la creazione del dump. Deve essere creato da un'istantanea (poco dopo discuteremo più in dettaglio delle caratteristiche di lavorare con le istantanee), un file system montato o congelato.
Questo schema dipende anche dal numero di file e il suo tempo di esecuzione aumenterà con la quantità di dati sul disco. Allo stesso tempo, il dump ha una velocità operativa maggiore rispetto a rsync.
Se è necessario ripristinare non l'intera copia di backup, ma, ad esempio, solo un paio di file danneggiati accidentalmente), il recupero di tali file con l'utilità di ripristino potrebbe richiedere troppo tempo
Backup completo a livello di dispositivo
- mdraid e DRBD
Infatti il RAID1 viene configurato con un disco/raid sul server e un drive di rete, e di volta in volta (a seconda della frequenza dei backup) il disco aggiuntivo viene sincronizzato con il disco/raid principale sul server.Il vantaggio più grande è la velocità. La durata della sincronizzazione dipende solo dal numero di modifiche apportate nell'ultimo giorno.
Questo sistema di backup viene utilizzato abbastanza spesso, ma poche persone si rendono conto che le copie di backup ottenute con il suo aiuto potrebbero essere inefficaci, ed ecco perché. Una volta completata la sincronizzazione del disco, il disco contenente la copia di backup viene disconnesso. Se, ad esempio, stiamo eseguendo un DBMS che scrive i dati su un disco locale in porzioni, archiviando i dati intermedi in una cache, non vi è alcuna garanzia che finiscano anche sul disco di backup. Nella migliore delle ipotesi, perderemo alcuni dei dati modificati. Pertanto, tali backup difficilmente possono essere considerati affidabili. - LVM+gg
Le istantanee sono uno strumento meraviglioso per creare backup coerenti. Prima di creare uno snapshot, è necessario reimpostare la cache dell'FS e del software nel sottosistema del disco.
Ad esempio, con MySQL da solo sarebbe simile a questo:
$ sudo mysql -e "TABELLE FLUSH CON BLOCCO DI LETTURA;" $ sudo mysql -e "LOGS FLUSH;" $ sudo sync $ sudo lvcreate -s -p r -l100%free -n %s_backup /dev/vg/%s $ sudo mysql -e "SBLOCCA TABELLE;"
* I colleghi raccontano storie su come il "blocco di lettura" di qualcuno a volte portasse a situazioni di stallo, ma a mia memoria ciò non è mai accaduto.
I backup DBMS possono essere creati separatamente (ad esempio, utilizzando i log binari), eliminando così i tempi di inattività durante il ripristino della cache. Puoi anche creare dump nello spazio di archiviazione avviando lì un'istanza DBMS. Il backup di diversi DBMS è un argomento per pubblicazioni separate.
Puoi copiare un'istantanea utilizzando la ripresa (ad esempio, rsync con una patch per copiare i dispositivi a blocchi bugzilla.redhat.com/show_bug.cgi?id=494313), puoi bloccare per blocco e senza crittografia (netcat, ftp). È possibile trasferire i blocchi in forma compressa e montarli nell'archivio utilizzando AVFS e montare una partizione con backup tramite SMB sul server.
La compressione elimina i problemi di velocità di trasmissione, congestione del canale e spazio di archiviazione. Tuttavia, se non utilizzi AVFS nell'archivio, ci vorrà molto tempo per ripristinare solo una parte dei dati. Se usi AVFS, incontrerai la sua "umidità".
Un'alternativa alla compressione a blocchi è squashfs: puoi montare, ad esempio, una partizione Samba sul server ed eseguire mksquashfs, ma questa utility funziona anche con i file, ad es. dipende dalla loro quantità.
Inoltre, quando si crea squashfs, viene sprecata molta RAM, il che può facilmente portare a chiamare oom-killer.
Sicurezza
È necessario proteggersi da una situazione in cui l'archivio o il server vengono violati. Se il server viene violato, è meglio che l'utente che scrive i dati non abbia i diritti per eliminare/modificare i file nell'archivio.Se l'archivio viene violato, è consigliabile limitare al massimo i diritti dell'utente di backup sul server.
Se il canale di backup può essere intercettato, è necessaria la crittografia.
Conclusione
Ogni sistema di backup ha i suoi pro e contro. In questo articolo, abbiamo cercato di evidenziare alcune sfumature nella scelta di un sistema di backup. Speriamo che possano aiutare i nostri lettori.Di conseguenza, quando si sceglie un sistema di backup per il proprio progetto, è necessario condurre test sul tipo di backup selezionato e prestare attenzione a:
- tempo di backup nella fase corrente del progetto;
- tempo di backup nel caso in cui siano presenti molti più dati;
- carico del canale;
- caricare sul sottosistema del disco sul server e nello spazio di archiviazione;
- tempo per ripristinare tutti i dati;
- tempo di recupero per una coppia di file;
- la necessità di coerenza dei dati, in particolare dei database;
- consumo di memoria e presenza di chiamate oom-killer;
Come soluzioni di backup, puoi utilizzare supload e il nostro cloud storage.
I lettori che non possono lasciare commenti qui sono invitati a unirsi a noi sul blog.
Tag: aggiungi tag
29/10/2012 Michel Pollo
Il backup del database è il mezzo più semplice ed economico per garantire la sicurezza dei dati aziendali. Non lasciarti cullare dal falso senso di sicurezza che deriva dall'implementazione del più recente sistema ad alta disponibilità. Se tutti i dati vengono virtualizzati e consolidati, i rischi aumentano addirittura
Michel Poulet ( [e-mail protetta])-editore della rivista SQL Server Pro, co-fondatore di Mount Vernon Data Systems e Six Sigma Uptime.
La maggior parte delle aziende attive da molto tempo hanno vissuto eventi catastrofici che avrebbero potuto farle fallire, come un guasto del database. Un backup del database è una copia dei dati, delle strutture e degli oggetti di sicurezza contenuti nel database. È necessario eseguire il backup di ogni database in base a una pianificazione diversa in base al numero di transazioni di scrittura eseguite ogni giorno. Per ridurre al minimo le perdite in caso di guasto del database, è necessario eseguire il backup di tutti i database utilizzati nell'azienda. E per assicurarti che i backup funzionino, dovresti controllarne il funzionamento dopo le operazioni di ripristino. Come minimo, è necessario disporre di copie dei database adatte per un ripristino rapido e l'operazione di ripristino stessa deve essere elaborata e non causare alcuna difficoltà.
Dopo dipendenti e clienti, la risorsa più preziosa delle aziende sono i dati. È responsabilità dell'amministratore del database garantire l'integrità dei dati in modo che i database possano essere ripristinati anche se il data center viene completamente distrutto. Il backup del database è il mezzo più semplice ed economico per garantire la sicurezza dei dati aziendali.
Non lasciarti cullare dal falso senso di sicurezza che deriva dall'implementazione del più recente sistema ad alta disponibilità. Se tutti i dati vengono virtualizzati e consolidati, i rischi aumentano addirittura. Com'era semplice la vita quando un computer eseguiva una singola istanza di un database. Al giorno d'oggi, ci sono solitamente dozzine di istanze di SQL Server in esecuzione su un server in macchine virtuali che, se il server fisico si guasta, si guastano tutte contemporaneamente. Se i fondi lo consentono, puoi creare un cluster di failover di host di macchine virtuali su diversi server fisici. Se è necessaria un'elevata disponibilità, in genere ciò avviene. Ma anche un sistema così tollerante ai guasti può essere vulnerabile in caso, ad esempio, di un incendio, di un’alluvione o di un terremoto. I backup sono ancora necessari. Allo stesso tempo, la creazione di copie di backup è affidata a un numero limitato di persone. Per ulteriori informazioni su chi può creare backup, vedere la barra laterale "Chi può eseguire il backup?"
La frequenza del backup di un database dipende dal tempo necessario per ripristinarlo da un backup. Quanto più frequentemente viene eseguito il backup del database, tanto minore sarà il tempo necessario per il ripristino. La pianificazione del backup e del ripristino può essere configurata individualmente per ciascun database. Il tipo di prenotazione dipende anche dalla dimensione del database e dal numero di transazioni eseguite per unità di tempo. I principali tipi di backup sono completo, journal e incrementale. Per ulteriori informazioni sulle modalità di ripristino, vedere la barra laterale "Modelli di ripristino del database" I comandi di backup di SQL Server sono descritti nella barra laterale "Comandi di backup standard".
Prenotazione completa
La strategia di ridondanza completa è la più semplice da comprendere e implementare. Al termine di ogni giornata lavorativa (o in qualsiasi altro intervallo di tempo da voi indicato), viene semplicemente avviata una procedura di backup completo del database (Figura 1). Ciò non richiede un backup del registro separato e non richiede alcuna impostazione aggiuntiva. Anche la gestione dei file in questa modalità di backup non richiede particolare attenzione, poiché si tratta di un unico file di backup completo. Anche il ripristino da un backup completo è molto semplice: è sufficiente ripristinare da un singolo file. L'utilizzo dei backup completi è una buona scelta per le organizzazioni con personale IT non sufficientemente esperto.
Un backup completo è più adatto per i database "piccoli": chiamiamo quei database di cui è possibile eseguire il backup entro il tempo assegnato. Quando SQL Server esegue un backup completo del database, salva prima tutte le estensioni su disco (un'estensione è composta da otto pagine consecutive, ciascuna di 8 KB). SQL Server esegue quindi il backup del log delle transazioni in modo che eventuali modifiche al database apportate durante il backup vengano archiviate anche nel file di backup completo.
Se esegui solo un backup completo, in caso di arresto anomalo del sistema, alcuni dati potrebbero andare persi, principalmente le modifiche apportate dall'ultimo backup. Se la frequenza degli aggiornamenti del database è bassa, ad esempio, vengono eseguite solo operazioni di massa ad alta velocità, è possibile pianificare un backup completo immediatamente dopo gli aggiornamenti di massa dei dati, nel qual caso i dati possono essere considerati abbastanza sicuri.
La ridondanza completa non è adatta per i sistemi di produzione che vengono aggiornati in modo piuttosto intenso. Quando si utilizza un backup completo, se è necessario eseguire il ripristino, sarà necessario eseguire nuovamente tutte le transazioni e i caricamenti di dati in blocco effettuati dopo il punto di backup. Se l'ultimo backup completo è danneggiato, sarà necessario ripristinare il backup precedente e verificare nuovamente manualmente che tutte le transazioni avvenute dopo il backup siano state applicate.
Per eseguire un backup completo del database, eseguire il codice seguente:
BACKUP DATABASE AdventureWorks SU DISCO = 'E:\SQLdata\BACKUPS\AdventureWorks_FullDbBkup.bak'CON INIT, NOME = 'AdventureWorks Full Db backup', DESCRIZIONE = 'AdventureWorks Full Database Backup
Il parametro DISK specifica il file di backup di destinazione. È possibile eseguire il backup su disco o su nastro (in questo caso, disco). Prima di avviare un backup, assicurarsi che la cartella in cui archiviare il backup esista. Nella maggior parte dei casi, il backup su disco è molto più veloce del backup su nastro, ma il costo dell'archiviazione su disco è notevolmente più elevato. Per un ulteriore livello di protezione, è possibile eseguire il backup su disco e quindi salvare il backup su nastro. L'opzione WITH INIT specifica che il file di backup deve essere sovrascritto. Questo metodo è adatto se viene eseguito un backup di Windows dopo ogni backup del database. NOME – nome del backup, fino a 128 caratteri. Se non specifichi un nome, il campo del nome verrà lasciato vuoto. DESCRIZIONE è una descrizione più completa e dettagliata che può aiutare, ad esempio, dopo un lungo periodo di tempo, a scoprire di che tipo di backup si tratta e perché è stato creato.
Per ripristinare completamente il database, eseguire il comando seguente:
RIPRISTINA DATABASE AdventureWorks DA DISCO = 'E:\SQLdata\BACKUPS\AdventureWorks_FullDbBkup.BAK' CON RECUPERO, SOSTITUISCI
WITH RECOVERY indica a SQL Server di interrompere qualsiasi transazione in sospeso che potrebbe trovarsi nel log delle transazioni e di lasciare il database in esecuzione. SOSTITUISCI significa sovrascrivere qualsiasi file esistente con lo stesso nome. Questo è discusso in maggior dettaglio nella barra laterale “Sostituzione del database”.
Quando si utilizza una strategia di backup completo, è necessario monitorare la dimensione del file di registro delle transazioni. Un backup completo non cancella il registro delle transazioni dalle voci inattive. Se si esegue solo un backup completo del database, è necessario far seguire a questa operazione un backup e una pulizia del file di registro. Questo viene fatto impostando TRUNCATE_ONLY, come nel comando seguente:
REGISTRO DI BACKUP AdventureWorks CON TRUNCATE_ONLY
Se viene specificata l'impostazione TRUNCATE_ONLY, non viene effettivamente eseguito alcun backup del log; indica a SQL Server di creare un checkpoint, eliminare gli elementi inattivi e ridurre la dimensione del file di log. Le versioni successive di SQL Server hanno eliminato questa impostazione, ma è possibile utilizzare invece la modalità di ripristino semplice per consentire a SQL Server di cancellare automaticamente il log delle transazioni dagli elementi inattivi.
Backup completo con conservazione dei registri
Se non riesci a tollerare alcuna perdita di dati durante il ripristino, puoi utilizzare una strategia di backup completo con registro aggiunto. Questo metodo impedirà la perdita di dati; è adatto per database aggiornati frequentemente. Sebbene questa strategia aumenti la complessità operativa e di manutenzione, il tempo complessivo dedicato al backup del database viene ridotto.
La Figura 2 mostra un esempio di pianificazione per un backup completo con conservazione del log: un backup completo settimanale la domenica e il salvataggio del log delle transazioni ogni giorno successivo fino alla domenica successiva, quando viene eseguito nuovamente il backup completo. Un backup del registro salva tutte le modifiche apportate dal backup del registro precedente. Nello schema di pianificazione in esame vengono salvate le modifiche giornaliere.
Se non diversamente specificato, una volta completato il backup del registro, le voci inattive nel registro vengono “rimosse” (in effetti, vengono contrassegnate per la sovrascrittura). Quando si esegue il comando BACKUP LOG, è possibile aggiungere i parametri NO_TRUNCATE o COPY_ONLY in modo che le voci del registro non vengano modificate quando viene eseguito il backup. Ma non consigliamo di utilizzare queste opzioni a meno che tu non sappia con certezza per cosa potresti averne bisogno.
SQL Server 2005 dispone di una modalità di backup della parte finale del log, ovvero il backup dopo un arresto anomalo del database se il log delle transazioni non è stato danneggiato. Questa modalità esegue il backup delle ultime transazioni eseguite dall'ultimo backup del registro. Questa modalità è descritta più dettagliatamente nella barra laterale “Cosa sono i backup della parte finale del log”.
L'utilizzo del modello di ripristino completo fornisce un'esperienza di ripristino relativamente semplice ed è l'opzione preferita quando si esegue un backup completo del journal. Ciò ripristina l'ultimo backup completo, quindi ripristina i registri esistenti in sequenza in ordine cronologico (nell'ordine in cui sono stati creati) e infine ripristina la parte finale del registro. Questa strategia è adatta ai sistemi di produzione, soprattutto se sono transazionali e prevedono poche operazioni di massa.
Se il tuo database subisce aggiornamenti in blocco regolari, potrebbe essere opportuno utilizzare un modello di recupero con registrazione collettiva. Poiché in questo caso i singoli record inclusi nell'operazione di massa non vengono registrati, questo approccio riduce il sovraccarico della registrazione di SQL Server. Anche se potresti riscontrare notevoli miglioramenti delle prestazioni durante l'esecuzione di operazioni in blocco, rischi di perdere dati durante il ripristino se i dati di origine per ripetere le operazioni in blocco non sono più disponibili al momento del ripristino. Quando si utilizza il modello di ripristino semplice, anche il backup del log non è possibile perché tronca il log in un checkpoint.
Per eseguire un backup completo del registro, è necessario prima eseguire il backup dell'intero database, come nell'esempio seguente:
BACKUP DATABASE AdventureWorks SU DISCO = 'E:\SQLdata\BACKUPS\AdventureWorks_FullDbBkup.bak' CON INIT, NOME = 'Backup completo del database AdventureWorks', DESCRIZIONE = 'Backup completo del database AdventureWorks'
E poi dovresti eseguire un backup del log usando il comando:
BACKUP DEL REGISTRO AdventureWorks SU DISCO = "E:\SQLdata\BACKUPS\AdventureWorks_TlogBkup.bak" CON NOINIT, NOME = "Backup AdventureWorks Translog", DESCRIZIONE = "Backup del registro transazioni AdventureWorks", NOFORMAT
L'opzione WITH NOINIT nell'ultimo comando specifica che il file di backup deve essere scritto in modalità di aggiunta sul supporto, disco o nastro esistente. In questo caso, tutti i backup del log delle transazioni verranno scritti nello stesso file uno dopo l'altro. NOFORMAT indica al processo di backup di conservare nelle intestazioni tutte le informazioni di intestazione che potrebbero essere contenute sui dischi di backup. Questa è l'impostazione predefinita e la specifica esplicita di questa impostazione è facoltativa, ma è utile come operazione di autodocumentazione.
Per eseguire il ripristino da un backup completo o da un backup completo con conservazione del registro, attenersi alla seguente procedura.
- Se il database è online, limitarne l'accesso modificando la modalità di accesso (nella finestra delle proprietà) su RESTRICTED_USER. Ciò consentirà solo ai membri del gruppo di database db_owner e ai membri dei gruppi di server dbcreator e sysadmin di accedere al database.
- Correggi l'errore che ha causato l'arresto anomalo del database.
- Se possibile, applica tutti i log delle transazioni di cui è stato eseguito il backup con l'opzione NORECOVERY.
Per eseguire un backup del registro finale, eseguire il comando:
REGISTRO BACKUP AdventureWorks SU DISCO = 'E:\SQLdata\BACKUPS\AdventureWorks_TaillogBkup.bak' CON NORECOVER
Per ripristinare completamente da un backup completo, è necessario prima ripristinare i file del database utilizzando il comando:
RIPRISTINA DATABASE AdventureWorks DAL DISCO = 'E:\SQLdata\BACKUPS\AdventureWorks_FullDbBkup.bak' CON NORECOVERY
Il parametro NORECOVERY indica a SQL Server che le transazioni parziali devono essere lasciate così come sono, senza tentare di eseguirne il rollback. Un successivo ripristino dei registri delle transazioni ripristinerà i dati per consentire il completamento di queste transazioni parziali. L'utilizzo dell'opzione NORECOVERY lascia il database in uno stato inutilizzabile. Immediatamente dopo un ripristino completo, tutti i backup del log delle transazioni devono essere ripristinati con l'opzione NORECOVERY, come mostrato di seguito:
RIPRISTINA LOG AdventureWorks DAL DISCO = 'E:\SQLdata\BACKUPS\AdventureWorks_TlogBkup.bak' CON NORECOVERY
Infine, ripristina il frammento finale con il parametro RECOVERY:
RIPRISTINA LOG AdventureWorks DAL DISCO = 'E:\SQLdata\BACKUPS\AdventureWorks_TaillogBkup.bak' CON RECUPERO
Una strategia di ripristino completo con ripristino dei log non rappresenta una protezione assoluta. Se uno dei backup del registro viene danneggiato, il ripristino sarà possibile solo fino al punto precedente al registro danneggiato. Si supponga, ad esempio, che un backup completo settimanale venga eseguito la domenica e che i backup del log vengano eseguiti dal lunedì al sabato. Se il backup di martedì è danneggiato, solo i dati di lunedì possono essere ripristinati: è improbabile che valga la pena correre il rischio di danneggiare l'integrità dei dati applicando le transazioni di mercoledì ai dati di lunedì. E anche il ripristino del frammento finale non porterà a nulla.
Ridondanza completa e differenziale
Nei casi in cui è richiesto un ulteriore livello di garanzia, è possibile aggiungere al progetto un backup differenziale oltre al backup del registro. Questa strategia è adatta per i database transazionali in cui i record vengono aggiunti frequentemente, la perdita di dati durante il ripristino non può essere tollerata e gli amministratori danno priorità al ripristino rapido.
Un backup differenziale è di natura cumulativa: include tutti i dati e le strutture che sono cambiati dall'ultimo backup completo, indipendentemente da quando è stato eseguito l'ultimo backup completo o da quante volte il backup differenziale è stato eseguito da allora. Supponiamo che sia stato eseguito un backup completo di domenica e che sia stato eseguito un backup differenziale ogni giorno, come mostrato nella Figura 3. La copia differenziale di lunedì conterrà tutte le modifiche apportate lunedì, la copia differenziale di martedì conterrà le modifiche apportate lunedì e martedì e la copia differenziale di mercoledì conterrà le modifiche di lunedì, martedì e mercoledì, ecc.
| Figura 3. Pianificazione dei processi di backup differenziale |
Il ripristino di un backup differenziale in genere richiede meno tempo rispetto al ripristino di un backup completo più registri perché è più veloce ripristinare una singola copia differenziale rispetto a una catena di registri. Il salvataggio di un backup differenziale si esegue con il comando:
BACKUP DATABASE AdventureWorks SU DISCO = 'E:\SQLdata\BACKUPS\AdventureWorks_DiffDbBkup.bak' CON INIT, DIFFERENZIALE, NOME = 'Backup AdventureWorks Diff Db', DESCRIZIONE = 'Backup differenziale del database AdventureWorks'
Per ripristinare un database da un backup differenziale, attenersi alla seguente procedura.
- Se il database è online, limitarne l'accesso modificando la modalità di accesso (nella finestra delle proprietà) su RESTRICTED_USER. Ciò consentirà l'accesso al database solo ai membri del gruppo database db_owner e ai membri dei gruppi server dbcreator e sysadmin.
- Eseguire un backup del registro finale.
- Risolvi il problema che ha causato l'arresto anomalo del database.
- Ripristina un backup completo con l'opzione NORECOVERY.
- Ripristina l'ultimo backup differenziale disponibile con l'opzione NORECOVERY.
- Ripristina un backup della parte finale del log con l'opzione RECOVERY.
Per ripristinare un backup differenziale (eseguito dopo il ripristino di un backup completo), immettere il comando:
RIPRISTINA DATABASE AdventureWorks DA DISCO = 'E:\SQLdata\BACKUPS\AdventureWorks_DiffDbBkup.bak'CON NORECOVERY
Ripristina quindi la coda del log con l'opzione RECOVERY utilizzando il comando mostrato in precedenza.
Il backup differenziale fornisce un livello più elevato di integrità dei dati rispetto al solo backup del log. Se l'ultimo backup differenziale è danneggiato, è possibile ripristinare il backup differenziale precedente mantenendo comunque l'integrità dei dati.
Combinazione di strategie
Se non è pratico rieseguire le transazioni per recuperare quelle dell'ultimo giorno, è possibile eseguire un backup completo la domenica, un backup differenziale ogni notte successiva e un backup del registro delle transazioni la mattina e la sera dal lunedì al sabato, come mostrato nella Figura 4. Se venerdì sera con il database Se si verifica un problema con i dati e il backup differenziale di giovedì è danneggiato, è possibile eseguire il ripristino dal backup differenziale di mercoledì e quindi applicare i registri di giovedì e venerdì. In questo modo il database verrà ripristinato fino al momento del guasto. Questo problema è discusso in maggior dettaglio nella barra laterale “Come ripristinare un database a un determinato momento”.
Per ridurre il rischio di perdita di dati, è necessario adottare una strategia mista che includa backup completo, backup del registro e backup differenziale, sebbene questa combinazione aggiunga una certa complessità alla strategia di backup e alla gestione del backup. È inoltre necessario valutare la quantità di dati che possono andare persi dopo un errore e un ripristino del database. L'utilizzo di una strategia di ripristino completo o di un modello di registro di massa invece di un ripristino semplice comporta un maggiore sovraccarico del file di registro delle transazioni e comporta file di backup più grandi, ma fornisce una maggiore integrità dei dati.
Strategie di prenotazione alternative
Il backup in SQL Server non è limitato al registro completo, differenziale e delle transazioni. Strategie più complesse includono il backup di file o gruppi di file, la strategia di backup parziale e il backup di sola copia.
Accesso al database durante il backup e il ripristino
Il backup di un database SQL Server è un processo online; tutti i dati archiviati in SQL Server sono accessibili durante l'operazione di backup. Le operazioni di modifica del database e le istruzioni INSERT, UPDATE e DELETE sono disponibili allo stesso modo della selezione dei dati (SELECT). La struttura del database o la struttura dei file non può essere modificata durante un backup: le istruzioni ALTER DATABASE, ADD FILE o SHRINKFILE non possono essere eseguite durante un backup. Se il database è impostato per la riduzione automatica, potrebbe verificarsi un conflitto durante l'esecuzione del backup. Pertanto, se durante il processo di backup viene avviata una riduzione automatica del file di database, entrambe le operazioni potrebbero fallire. L'operazione avviata per prima bloccherà il file e l'operazione successiva dovrà attendere il rilascio del blocco. Se la prima operazione rilascia il blocco, inizierà la seconda operazione. Se il blocco della prima operazione scade, la seconda operazione fallirà. Questo approccio può sembrare errato dal punto di vista dell'esecuzione della seconda operazione, che è costretta ad attendere un fallimento e solo dopo emetterà un fallimento. Ma se consideriamo che il lavoro della seconda operazione dipende dal successo della prima, se durante la prima operazione si verifica un fallimento, eseguire la seconda non ha senso. Per evitare questo problema, è necessario disattivare la riduzione automatica del file di database prima di eseguire un backup.
Nella maggior parte dei casi, il ripristino di un database SQL Server è un'operazione offline durante la quale non è possibile l'accesso dell'utente al database. Quando si utilizza SQL Server 2005 Enterprise Edition con il modello di recupero completo, il ripristino parziale e il ripristino di gruppi di file minori sono operazioni in linea per impostazione predefinita. Le parti del database che non devono essere ripristinate, ad esempio gruppi di file con accesso di sola scrittura, possono essere accessibili agli utenti per la durata dell'operazione di ripristino. I gruppi di file sono leggibili/scrivibili a meno che non siano stati portati offline per il ripristino. Questa funzionalità è molto utile per database di grandi dimensioni in esecuzione 24 ore su 24, 7 giorni su 7, 365 giorni all'anno. Per ulteriori informazioni, consultare la documentazione BOL di SQL Server 2005, "Esecuzione di ripristini in linea" (http://msdn.microsoft.com/en-us/library/ms188671.aspx) e la barra laterale "Perché i ripristini del database non riescono". ."
Riassumiamo
I dati sono di grande importanza per le aziende, quindi garantirne la sicurezza è uno dei compiti più importanti. Il backup dei dati gioca un ruolo importante in questo processo. Il primo passo per garantire un accesso costante ai dati è creare un sistema di backup regolare e ripristino di prova dei database. Quando crei un nuovo database, dovresti creare immediatamente script di backup e ripristino. SQL Server offre una varietà di funzionalità di backup e ripristino che possono essere personalizzate in base alle esigenze specifiche del database.
Chi può effettuare una prenotazione?
Il backup del database è disponibile per un numero limitato di persone. Per impostazione predefinita, l'autorizzazione viene concessa ai membri di determinati gruppi sysadmin del server e ai ruoli del database db_owner e db_backupoperator. Quando si utilizzano dispositivi, dischi o nastri di backup, è necessario prestare attenzione a chi è il proprietario e quali autorizzazioni sono impostate. SQL Server deve essere in grado di leggere e scrivere sul dispositivo. Se l'account con cui è in esecuzione SQL Server non dispone delle autorizzazioni per accedere al dispositivo, lo saprai solo se l'operazione di backup o ripristino non riesce. La procedura memorizzata sp_addumpdevice, che aggiunge una voce del dispositivo di backup alle tabelle di sistema, non esegue controlli delle autorizzazioni a livello di file.
È possibile specificare una password per creare una copia di backup. In questo caso è necessario inserire una password anche durante il ripristino del database. La protezione tramite password è una misura opzionale che, tra l'altro, è considerata inaffidabile. La protezione tramite password viene utilizzata per impedire il recupero dei dati da parte di persone non autorizzate che non sono a conoscenza delle politiche di backup/ripristino dell'azienda. Poiché i dati non vengono crittografati quando si specifica una password, questa misura non impedirà la lettura dei dati di backup tramite strumenti speciali. Inoltre, la password non impedisce che il file di backup venga sovrascritto o eliminato.
Modelli di ripristino dei database
L'impostazione del modello di ripristino determina la quantità di dati che può essere recuperata in caso di arresto anomalo del database. Ogni database può avere il proprio modello di ripristino, a seconda della quantità di perdita di dati che si è disposti a tollerare. Per impostare un modello di ripristino del database utilizzando SQL Server Management Studio (SSMS), fare clic con il pulsante destro del mouse sul database desiderato, aprire la finestra Proprietà, andare alla pagina Opzioni e selezionare il modello di backup desiderato dall'elenco a discesa.
Esistono tre tipi di modelli di ripristino: completo, semplice e con registrazione collettiva. Il modello di recupero completo sfrutta appieno tutte le funzionalità del registro delle transazioni e consente di ripristinare il database con un elevato grado di precisione a un determinato momento. Tutte le operazioni come transazioni di dati, modifiche strutturali del database, istruzioni operative come il completamento o l'annullamento delle transazioni, oggetti di grandi dimensioni e operazioni di massa vengono archiviate in un registro. Il registro delle transazioni viene aggiornato fino al completamento del backup del registro delle transazioni.
Il modello di ripristino semplice utilizza in modo minimo il log delle transazioni e consente di ripristinare l'ultimo backup completo del database. Come con il modello di recupero completo, tutte le transazioni (ad eccezione di alcune transazioni batch) vengono conservate in un giornale. A differenza del modello di recupero completo, SQL Server cancella automaticamente il registro degli elementi inutilizzati. Per questo motivo, non è possibile eseguire backup del log delle transazioni quando si utilizza il modello di ripristino semplice.
Il modello di recupero con registrazione collettiva si colloca tra gli estremi dei modelli di recupero completo e semplice. Sebbene il nome bulk-logged possa farti pensare alla registrazione di transazioni in blocco, in realtà vengono registrate solo parzialmente. Durante le operazioni di massa, che spesso implicano l'aggiunta di un numero elevato di record in un breve periodo di tempo, SQL Server imposta un flag su ogni estensione del database interessata dall'aggiornamento, ma i record inseriti non vengono effettivamente aggiunti al file di registro. Durante un successivo backup del log delle transazioni, SQL Server seleziona questo flag e scrive nel backup del log delle transazioni le effettive estensioni del database modificate dall'operazione di massa, oltre ai normali record di inserimento ed eliminazione. Pertanto, il backup del log nel modello di recupero con registrazione minima delle operazioni di massa contiene i risultati delle operazioni di massa anziché le singole transazioni effettivamente completate.
L'utilizzo di un modello di recupero con registrazione minima delle operazioni di massa fornisce la stessa completezza di un modello di recupero completo, ma senza il sovraccarico aggiuntivo derivante dal backup di tutti gli inserimenti di dati di massa. Tuttavia, esistono dei rischi associati all'utilizzo di un modello di recupero con registrazione collettiva. Se si perdono i dati di origine di un'operazione di massa tra le operazioni di backup, non sarà possibile un ripristino completo del database. Inoltre, non è possibile ripristinare un database a un determinato momento da un backup della parte finale del log: il tentativo di ripristino fallirà.
Sebbene i modelli di ripristino completo e di massa comportino una maggiore attività del registro delle transazioni e una maggiore dimensione del file di backup, ciò è compensato da un ripristino dei dati più completo in caso di errore del database.
Comandi standard per la prenotazione
SQL Server 2005 e SQL Server 2000 dispongono di due comandi che eseguono essenzialmente la stessa operazione: DUMP e BACKUP (ovvero DUMP DATABASE o BACKUP DATABASE e DUMP LOG o BACKUP LOG). Il comando DUMP esiste da SQL Server 6.5, quando eseguire il backup di un database significava semplicemente copiare il database nello stato in cui si trovava prima dell'inizio dell'operazione di backup. Allo stesso tempo, le modifiche nella banca dati che potrebbero essersi verificate dopo l'avvio del backup non sono state incluse nella copia di backup.
A partire dalla versione 7, SQL Server può eseguire veri backup "dinamici", ovvero le modifiche apportate dopo l'inizio del processo di backup vengono scritte nel registro delle transazioni e archiviate nel file di backup. Pertanto, un backup è una “istantanea” del database nel momento in cui è stata completata l'operazione di backup. Il comando DUMP viene mantenuto per compatibilità con le versioni precedenti, ma Microsoft non ne consiglia l'utilizzo su nuovi sistemi in fase di sviluppo. Un giorno questo comando verrà eliminato e gli sviluppatori dovranno sbarazzarsene in quei frammenti di codice in cui è ancora utilizzato.
Coloro che sono sempre stati attenti al backup dei database SQL Server e desiderosi di apprendere le novità di SQL Server 2005 dovrebbero continuare a prestare molta attenzione ai propri backup: SQL Server 2005 non dispone del familiare comando DBCC REPAIR. Il "sostituto" di questo comando è DROP DATABASE.
Sostituzione della banca dati
Quando si ripristina un database su un nuovo server, utilizzare l'opzione REPLACE, che disabilita i normali controlli di sicurezza e consente di sovrascrivere i database esistenti, anche se il loro nome è diverso dal nome del database da ripristinare. Ad esempio, si supponga che sia stato eseguito un backup del database D, situato sul server A. Questo backup deve essere ripristinato sul server B. Innanzitutto, è necessario creare un database di staging vuoto sul server B e il nome e la dimensione del database non questione. Successivamente, è necessario ripristinare il database D con il parametro REPLACE sul server B sopra il database intermedio appena creato. Se il ripristino deve essere eseguito nuovamente sul server A, nella sua posizione originale, il parametro REPLACE non è richiesto. Per impostazione predefinita, un'operazione di ripristino del database esegue controlli di sicurezza integrati, ad esempio quando un ripristino del database non può normalmente essere eseguito su un altro database esistente. Allo stesso modo, è vietato ripristinare un database di cui è stato eseguito il backup utilizzando una modalità di backup con registrazione completa o di massa se non è disponibile un backup della parte finale del log.
Se è necessario ripristinare un database che, per un motivo o per un altro, non disponeva di un backup della parte finale del registro (ad esempio perché il file di backup del registro delle transazioni era danneggiato), l'utilizzo della modalità REPLACE potrebbe essere l'unico modo per ripristinare correttamente. Un altro esempio in cui è necessario il parametro REPLACE è se è necessario ripristinare il backup di un database di produzione in un ambiente di test e sviluppo. Anche quando i nomi dei database nell'ambiente di produzione e nell'ambiente di sviluppo sono gli stessi, dal punto di vista di SQL Server si tratta di database diversi.
Cosa sono i backup del registro finale?
Il backup della parte finale del log è una nuova modalità di backup di SQL Server 2005. Questa modalità aggiunge i record del log delle transazioni aggiunti al backup dopo l'ultimo backup del file di log. Quando si tenta di ripristinare un database dal punto in cui si è verificato l'errore, eseguire un backup del segmento di coda prima di avviare il ripristino. Non è necessario eseguire quest'ultimo backup se si intende ripristinare il database al punto precedente all'ultimo backup del log delle transazioni o se si sposta il database da un'istanza del server a un'altra o se si sovrascrive il database. È possibile che il registro delle transazioni sia danneggiato, nel qual caso non è possibile eseguire il backup del frammento di coda e il ripristino dovrà essere eseguito senza di esso.
Come ripristinare un database a un determinato momento
Potrebbe verificarsi una situazione in cui è necessario eseguire un ripristino del database a causa di un'esecuzione errata del codice, ad esempio qualcuno ha erroneamente eliminato una tabella in un database di produzione o ha dimenticato di includere una clausola WHERE in una clausola DELETE. In questi casi, è necessario ripristinare il database allo stato precedente al momento in cui è stato eseguito il codice errato.
Il ripristino è un insieme di operazioni che riportano il database in uno stato coerente. Per ripristinare un database a un momento specifico, è necessario eseguire un ripristino con journaling completo o parziale. Il modello di ripristino semplice comporta l'interruzione del registro delle transazioni su un punto di controllo senza la possibilità di ripetere l'annullamento e senza la possibilità di ripristinare un determinato punto nel tempo.
L'esecuzione di operazioni di ripristino seguite da "ripeti/annulla modifiche" implica il ripristino dei dati al loro stato originale in un momento specifico specificato dall'utente, in base al nome della transazione completata o al numero di sequenza nel registro. Il modello di recupero con registrazione minima di massa presenta l'ulteriore limitazione che il ripristino temporizzato è possibile solo se non sono state eseguite operazioni di massa dal backup del log precedente. In altre parole, un ripristino temporizzato corretto richiede che la sequenza dei file di backup del log sia continua.
I dati temporizzati da ripristinare devono essere contenuti in un backup del log delle transazioni. Quando si ripristina un registro, è possibile ripristinare le transazioni avvenute fino a un momento specifico specificando tale momento utilizzando l'istruzione STOPAT, STOPATMARK o STOPBEFOREMARK.
Quando si ripristina un database a un determinato momento, eseguire un backup completo con l'impostazione NORECOVERY, come mostrato di seguito:
RIPRISTINA DATABASE AdventureWorks DAL DISCO = "E:\SQLdata\BACKUPS\AdventureWorks_FullDbBkup.bak" CON NORECOVERY
Quindi applica tutti i backup del log con l'impostazione RECOVERY e specificando la data e l'ora del momento desiderato in ciascuna clausola RESTORE LOG:
RIPRISTINA REGISTRO AdventureWorks DA DISCO = "E:\SQLdata\BACKUPS\AdventureWorks_TlogBkup.bak" CON RECUPERO, STOPAT = "10 dicembre 2007 20:10"
Backup di file/gruppi di file
Questa strategia di backup è adatta solo se il database è costituito da più file o gruppi di file. Se le dimensioni del database o i requisiti di prestazioni rendono impossibile un backup completo del database e se è necessario un ripristino rapido in caso di guasto, è opportuno prendere in considerazione strategie di backup di file/filegroup.
Questa strategia può essere utilizzata per SQL Server 2005 o SQL Server 2000, richiedendo che ogni operazione specifichi di quali file, gruppi di file o combinazioni verrà eseguito il backup. Tuttavia, è necessario eseguire un backup completo del database subito dopo la creazione, seguito da backup regolari di file o gruppi di file. Se si desidera utilizzare il modello di ripristino semplice per un database particolare, è necessario eseguire il backup di tutti i file di lettura/scrittura e dei gruppi di file contemporaneamente. Per ridurre al minimo la perdita di dati durante il ripristino, scegli un modello di ripristino completo o con registrazione minima e includi il backup del log delle transazioni nella tua strategia.
Ripristinare il database significa comunque limitare l'accesso al database, ma per un tempo inferiore rispetto a un ripristino completo del database. Durante il ripristino, l'accesso è limitato solo ai gruppi di file attualmente in fase di ripristino.
Nel peggiore dei casi, se è necessario ripristinare l'intero database e si utilizza il modello di recupero completo, saranno necessari tutti i backup del log delle transazioni a partire dalla creazione del database. Inoltre, se è necessario ripristinare il database a un momento specifico, sarà necessario un set completo di backup del log delle transazioni.
Restauro parziale
Questa strategia, introdotta in SQL Server 2005, è destinata ai database che dispongono di più gruppi di file di sola lettura e utilizzano un modello di ripristino semplice. Poiché questo tipo di database è principalmente di sola lettura, le strategie di backup e ripristino completo sono ridondanti. Tuttavia, il modello di ridondanza frazionaria può essere applicato a qualsiasi tipo di database.
Quando si esegue un backup parziale, viene innanzitutto eseguito il backup del gruppo di file principale, di tutti i gruppi di file di lettura/scrittura e di eventuali gruppi di file di sola lettura specificati. Poiché le tabelle di sola lettura non sono soggette a modifiche frequenti, in teoria non è necessario eseguire il backup con la stessa frequenza delle tabelle soggette a modifiche.
È necessaria un'attenta pianificazione prima di impostare la ridondanza frazionata. Quando crei un database, dovresti creare vari gruppi di file e quando crei tabelle, dovresti inserirli esplicitamente nei gruppi di file appropriati. Pertanto, le tabelle delle directory del database si trovano nel gruppo di file primario, le tabelle di sola lettura si trovano in gruppi di file di sola lettura e le tabelle di lettura/scrittura si trovano in gruppi di file di lettura/scrittura.
I backup parziali riducono il tempo necessario per ripristinare completamente un database. Se l'intero database è di sola lettura, solo il gruppo principale di file verrà incluso nel backup parziale, a meno che non venga specificato diversamente. Inoltre, è possibile utilizzare una copia parziale anziché una copia completa come base per un backup differenziale. La ridondanza frazionata fornisce opzioni aggiuntive e flessibilità nella strategia di ridondanza.
Il ripristino da un backup parziale comporta comunque la limitazione dell'accesso al database, ma per un periodo di tempo più breve rispetto a un ripristino completo del database e solo per il gruppo di file primario, i gruppi di lettura/scrittura e i gruppi di sola lettura che facevano parte del backup . Per ulteriori informazioni, consultare la documentazione in linea di SQL Server 2005 "Backup parziali" http://msdn.microsoft.com/ru-ru/library/ms191539.aspx.
Backup dello Stato
A volte è necessario effettuare una prenotazione per compiti speciali, ad esempio per creare una presentazione da mostrare a un cliente. Tuttavia, non si desidera interrompere il normale ordine dei file necessari per ripristinare il database. In questo caso puoi sfruttare la possibilità di creare una copia di backup dello stato del database. Tale copia può essere creata indipendentemente dalla strategia di ripristino del database utilizzata: copia completa, copia di massa o semplice (copia di massa o semplice).
Ma i backup statali non dovrebbero far parte di una strategia di ripristino. È possibile creare una copia dello stato, ripristinare il database da essa sul portatile demo e quindi eliminare in modo sicuro il file di backup. Altri backup "normali" non dipendono in alcun modo dalle copie dello stato, pertanto le copie dello stato non saranno necessarie durante l'esecuzione di un ripristino.
La strategia di prenotazione dello stato non può essere utilizzata come base per le prenotazioni differenziali perché la creazione di una copia dello stato non aggiorna la bitmap differenziale utilizzata per determinare quali estensioni copiare e quali mantenere. In realtà la procedura di copia differenziale non tiene conto delle copie dello Stato che sono state effettuate, per cui tali copie non possono partecipare al processo di recupero differenziale.
Quando si esegue il backup del registro delle transazioni dello stato del database, il registro delle transazioni non viene troncato, a differenza di un normale backup. Inoltre, un backup dello stato non ha alcun effetto sulla catena di log utilizzata per un backup completo con un log di ripristino. I backup dello stato non sono affatto inclusi nell'elenco dei backup del log una volta ripristinati. Per ulteriori informazioni, vedere la documentazione "Backup dello stato" di SQL Server 2005 BOL all'indirizzo http://msdn.microsoft.com/en-us/library/ms191495.aspx.
Perché il ripristino del database non può essere eseguito online
Agli amministratori di backup viene spesso chiesto perché l'accesso a un database è disabilitato durante un ripristino del database. È infatti possibile un accesso parziale ai dati a seconda del tipo di ripristino effettuato. La regola generale prevede che i file, i gruppi di file o le pagine soggetti a ripristino automatico vengano portati offline perché ciò è necessario affinché le operazioni di ripristino vengano completate correttamente.
Il processo di ripristino in genere inizia copiando i dati, i registri e le pagine di indice dal supporto di backup ai file del database. Poi arriva la fase di riesecuzione, che applica le transazioni salvate nel registro ai dati salvati al momento del backup del database; questo processo è spesso chiamato “iterazione del cambiamento”. Queste transazioni registrate rappresentano le modifiche al database che si sono verificate dall'ultimo backup del database prima dell'errore. SQL Server copia innanzitutto i dati e le modifiche strutturali nel log delle transazioni e quindi esegue tali modifiche nel database vero e proprio. La riproduzione delle modifiche garantisce che le modifiche apportate nel registro vengano applicate al database.
In questa fase, il database solitamente contiene transazioni in sospeso e non è possibile accedervi. Successivamente, SQL Server 2005 Standard Edition entra nella fase finale di rollback, che ripristina tutte le transazioni in sospeso. Una volta completata questa fase, il database è completamente ripristinato e pronto per l'uso. L'edizione Enterprise funziona in modo leggermente diverso: il database è pronto per l'uso immediatamente dopo la ripetizione delle modifiche, senza attendere la fase di cancellazione delle transazioni in sospeso.
L'accesso a file, gruppi di file e pagine viene negato durante il ripristino del database e le fasi di rollback/rollback perché i dati che potrebbero essere recuperati non sono validi. Il tentativo di elaborare dati sporchi può causare problemi con transazioni mancate e incomplete.
La preparazione di un nuovo server per il funzionamento dovrebbe iniziare con la configurazione del backup. Sembra che tutti lo sappiano, ma a volte anche gli amministratori di sistema esperti commettono errori imperdonabili. E il punto qui non è solo che il compito di creare un nuovo server deve essere risolto molto rapidamente, ma anche che non è sempre chiaro quale metodo di backup utilizzare.
Certo, è impossibile creare un metodo ideale che vada bene per tutti: ogni cosa ha i suoi pro e i suoi contro. Ma allo stesso tempo sembra abbastanza realistico scegliere il metodo che meglio si adatta alle specificità di un particolare progetto.
Quando si sceglie un metodo di backup, è necessario innanzitutto prestare attenzione ai seguenti criteri:
- Velocità (tempo) del backup nello spazio di archiviazione;
- Velocità (tempo) di ripristino da una copia di backup;
- Quante copie possono essere conservate con una dimensione di archiviazione limitata (server di archiviazione di backup);
- Il volume dei rischi dovuti all'incoerenza delle copie di backup, al metodo non sviluppato di eseguire i backup, alla perdita completa o parziale dei backup;
- Costi generali: livello di carico creato sul server durante l'esecuzione di una copia, diminuzione della velocità di risposta del servizio, ecc.
- Costo del noleggio di tutti i servizi utilizzati.
In questo articolo parleremo dei principali metodi per eseguire il backup dei server che eseguono sistemi Linux e dei problemi più comuni che i principianti potrebbero incontrare in questa importantissima area dell'amministrazione di sistema.
Schema per l'organizzazione dell'archiviazione e del ripristino dalle copie di backup
Quando si sceglie uno schema organizzativo per il metodo di backup, è necessario prestare attenzione ai seguenti punti fondamentali:- I backup non possono essere archiviati nella stessa posizione dei dati di cui viene eseguito il backup. Se archivi un backup sullo stesso array di dischi dei tuoi dati, lo perderai se l'array di dischi principale è danneggiato.
- Il mirroring (RAID1) non può essere paragonato al backup. Il raid ti protegge solo da un problema hardware con uno dei dischi (e prima o poi si verificherà un problema del genere, poiché il sottosistema del disco è quasi sempre il collo di bottiglia sul server). Inoltre, quando si utilizzano raid hardware esiste il rischio di guasto del controller, ad es. è necessario conservarne un modello di riserva.
- Se archivi i backup all'interno di un rack in un DC o semplicemente all'interno di un DC, in questa situazione ci sono anche alcuni rischi (puoi leggere a riguardo, ad esempio,.
- Se si archiviano copie di backup in controller di dominio diversi, i costi di rete e la velocità di ripristino da una copia remota aumentano notevolmente.
Spesso il motivo del ripristino dei dati è il danneggiamento del file system o dei dischi. Quelli. i backup devono essere archiviati da qualche parte su un server di archiviazione separato. In questo caso il problema potrebbe essere la “larghezza” del canale di trasmissione dati. Se disponi di un server dedicato, è altamente consigliabile eseguire i backup su un'interfaccia di rete separata e non sulla stessa che scambia dati con i client. Altrimenti, le richieste del tuo cliente potrebbero non “entrare” nel canale di comunicazione limitato. Oppure, a causa del traffico dei clienti, i backup non verranno eseguiti in tempo.
Successivamente, è necessario pensare allo schema e ai tempi di recupero dei dati in termini di archiviazione dei backup. Potresti essere abbastanza soddisfatto del completamento di un backup in 6 ore di notte su una struttura di archiviazione con una velocità di accesso limitata, ma è improbabile che un ripristino in 6 ore sia adatto a te. Ciò significa che l’accesso alle copie di backup dovrebbe essere comodo e che i dati dovrebbero essere copiati abbastanza velocemente. Quindi, ad esempio, il ripristino di 1 TB di dati con una larghezza di banda di 1 Gb/s richiederà quasi 3 ore, e questo se non si è limitati dalle prestazioni del sottosistema del disco nello storage e nel server. E non dimenticare di aggiungere a questo il tempo necessario per rilevare il problema, il tempo necessario per decidere di eseguire il rollback, il tempo necessario per verificare l'integrità dei dati recuperati e la quantità di successiva insoddisfazione tra clienti/colleghi .
Backup incrementale
A incrementale il backup copia solo i file che sono cambiati rispetto al backup precedente. I successivi backup incrementali aggiungono solo i file che sono cambiati rispetto a quello precedente. In media, i backup incrementali richiedono meno tempo perché vengono copiati meno file. Tuttavia, il processo di ripristino dei dati richiede più tempo poiché è necessario ripristinare i dati dell'ultimo backup completo, oltre ai dati di tutti i successivi backup incrementali. In questo caso, a differenza della copia differenziale, i file modificati o nuovi non sostituiscono quelli vecchi, ma vengono aggiunti al supporto in modo indipendente.
La copia incrementale viene spesso eseguita utilizzando l'utilità rsync. Con il suo aiuto, puoi risparmiare spazio di archiviazione se il numero di modifiche al giorno non è molto elevato. Se i file modificati sono di grandi dimensioni, verranno copiati completamente senza sostituire le versioni precedenti.
Il processo di backup tramite rsync può essere suddiviso nei seguenti passaggi:
- Viene compilato un elenco di file sul server ridondante e nell'archivio, per ciascun file vengono letti i metadati (autorizzazioni, ora di modifica, ecc.) o un checksum (quando si utilizza la chiave —checksum).
- Se i metadati dei file differiscono, il file viene diviso in blocchi e per ciascun blocco viene calcolato un checksum. I blocchi che differiscono vengono caricati nell'archivio.
- Se viene apportata una modifica al file durante il calcolo del checksum o il trasferimento del file, il backup verrà ripetuto dall'inizio.
- Per impostazione predefinita, rsync trasferisce i dati tramite SSH, il che significa che ogni blocco di dati viene ulteriormente crittografato. Rsync può anche essere eseguito come demone e trasferire dati senza crittografia utilizzando il suo protocollo.
Informazioni più dettagliate su come funziona rsync possono essere trovate sul sito ufficiale.
Per ogni file, rsync esegue un numero molto elevato di operazioni. Se sul server sono presenti molti file o se il processore è molto caricato, la velocità di backup sarà notevolmente ridotta.
Per esperienza possiamo dire che i problemi sui dischi SATA (RAID1) iniziano dopo circa 200G di dati sul server. In effetti, tutto, ovviamente, dipende dal numero di inode. E in ogni caso, questo valore può spostarsi nell'una o nell'altra direzione.
Dopo un certo punto, il tempo di esecuzione del backup sarà molto lungo o semplicemente non verrà completato in un giorno.
Per non confrontare tutti i file, c'è lsyncd. Questo demone raccoglie informazioni sui file modificati, ad es. ne avremo già un elenco pronto per la sincronizzazione in anticipo. Tuttavia, è necessario tenere presente che ciò comporta un carico aggiuntivo sul sottosistema del disco.
Backup differenziale
A differenziale In un backup, viene eseguito ogni volta il backup di ogni file modificato dall'ultimo backup completo. La copia differenziale accelera il processo di ripristino. Tutto ciò di cui hai bisogno è l'ultimo backup completo e differenziale più recente. I backup differenziali stanno diventando sempre più popolari poiché tutte le copie dei file vengono eseguite in determinati momenti, il che è molto importante, ad esempio, in caso di infezione da virus.
Il backup differenziale viene eseguito, ad esempio, utilizzando un'utilità come rdiff-backup. Quando si lavora con questa utility, si presentano gli stessi problemi dei backup incrementali.
In generale, se si esegue una ricerca completa del file cercando differenze nei dati, i problemi di questo tipo di backup sono simili ai problemi con rsync.
Vorremmo notare separatamente che se nello schema di backup ogni file viene copiato separatamente, vale la pena eliminare/escludere i file che non ti servono. Ad esempio, potrebbero trattarsi di cache CMS. Tali cache contengono solitamente molti file di piccole dimensioni, la cui perdita non influirà sul corretto funzionamento del server.
Backup completo
Un backup completo di solito influisce sull'intero sistema e su tutti i file. I backup settimanali, mensili e trimestrali comportano la creazione di una copia completa di tutti i dati. Di solito viene eseguito il venerdì o durante il fine settimana, quando la copia di una grande quantità di dati non influisce sul lavoro dell'organizzazione. I backup successivi, eseguiti dal lunedì al giovedì fino al successivo backup completo, possono essere differenziali o incrementali, principalmente per risparmiare tempo e spazio di archiviazione. I backup completi dovrebbero essere eseguiti almeno settimanalmente.
La maggior parte delle pubblicazioni correlate consiglia di eseguire un backup completo una o due volte alla settimana e di utilizzare backup incrementali e differenziali per il resto del tempo. C'è una ragione per questo consiglio. Nella maggior parte dei casi è sufficiente un backup completo una volta alla settimana. Ha senso eseguirlo nuovamente se non si ha la possibilità di aggiornare un backup completo lato storage e di garantire la correttezza della copia di backup (questo potrebbe essere necessario, ad esempio, nei casi in cui per un motivo o per l'altro si non fidarti degli script che hai o del software di backup.
Infatti, un backup completo può essere diviso in 2 parti:
- Backup completo a livello di file system;
- Backup completo a livello di dispositivo.
Diamo un'occhiata alle loro caratteristiche usando un esempio:
root@komarov:~# df -h Dimensione file system utilizzata Divail Usa% Montato su /dev/mapper/komarov_system-root 3.4G 808M 2.4G 25% / /dev/mapper/komarov_system-home 931G 439G 493G 48% /home udev 383M 4.0K 383M 1% /dev tmpfs 107M 104K 107M 1% /run tmpfs 531M 0 531M 0% /tmp nessuno 5.0M 0 5.0M 0% /run/lock nessuno 531M 0 531M 0% /run/shm /dev/xvda1 138M 22M 109M 17% /avvio
Prenoteremo solo /casa. Tutto il resto può essere rapidamente ripristinato manualmente. Puoi anche distribuire un server con un sistema di gestione della configurazione e connettere la nostra /home ad esso.
Backup completo a livello di file system
Rappresentante tipico: discarica.L'utilità crea un "dump" del file system. È possibile creare non solo un backup completo, ma anche incrementale. dump funziona con la tabella degli inode e "comprende" la struttura dei file (quindi i file sparsi vengono compressi).
Il dump di un file system in esecuzione è "stupido e pericoloso" perché il file system potrebbe cambiare durante la creazione del dump. Deve essere creato da un'istantanea (poco dopo discuteremo più in dettaglio delle caratteristiche di lavorare con le istantanee), un file system montato o congelato.
Questo schema dipende anche dal numero di file e il suo tempo di esecuzione aumenterà con la quantità di dati sul disco. Allo stesso tempo, il dump ha una velocità operativa maggiore rispetto a rsync.
Se è necessario ripristinare non l'intera copia di backup, ma, ad esempio, solo un paio di file danneggiati accidentalmente), il recupero di tali file con l'utilità di ripristino potrebbe richiedere troppo tempo
Backup completo a livello di dispositivo
- mdraid e DRBD
Infatti il RAID1 viene configurato con un disco/raid sul server e un drive di rete, e di volta in volta (a seconda della frequenza dei backup) il disco aggiuntivo viene sincronizzato con il disco/raid principale sul server.Il vantaggio più grande è la velocità. La durata della sincronizzazione dipende solo dal numero di modifiche apportate nell'ultimo giorno.
Questo sistema di backup viene utilizzato abbastanza spesso, ma poche persone si rendono conto che le copie di backup ottenute con il suo aiuto potrebbero essere inefficaci, ed ecco perché. Una volta completata la sincronizzazione del disco, il disco contenente la copia di backup viene disconnesso. Se, ad esempio, stiamo eseguendo un DBMS che scrive i dati su un disco locale in porzioni, archiviando i dati intermedi in una cache, non vi è alcuna garanzia che finiscano anche sul disco di backup. Nella migliore delle ipotesi, perderemo alcuni dei dati modificati. Pertanto, tali backup difficilmente possono essere considerati affidabili. - LVM+gg
Le istantanee sono uno strumento meraviglioso per creare backup coerenti. Prima di creare uno snapshot, è necessario reimpostare la cache dell'FS e del software nel sottosistema del disco.
Ad esempio, con MySQL da solo sarebbe simile a questo:
$ sudo mysql -e "TABELLE FLUSH CON BLOCCO DI LETTURA;" $ sudo mysql -e "LOGS FLUSH;" $ sudo sync $ sudo lvcreate -s -p r -l100%free -n %s_backup /dev/vg/%s $ sudo mysql -e "SBLOCCA TABELLE;"
* I colleghi raccontano storie su come il "blocco di lettura" di qualcuno a volte portasse a situazioni di stallo, ma a mia memoria ciò non è mai accaduto.
I backup DBMS possono essere creati separatamente (ad esempio, utilizzando i log binari), eliminando così i tempi di inattività durante il ripristino della cache. Puoi anche creare dump nello spazio di archiviazione avviando lì un'istanza DBMS. Il backup di diversi DBMS è un argomento per pubblicazioni separate.
Puoi copiare un'istantanea utilizzando la ripresa (ad esempio, rsync con una patch per copiare i dispositivi a blocchi bugzilla.redhat.com/show_bug.cgi?id=494313), puoi bloccare per blocco e senza crittografia (netcat, ftp). È possibile trasferire i blocchi in forma compressa e montarli nell'archivio utilizzando AVFS e montare una partizione con backup tramite SMB sul server.
La compressione elimina i problemi di velocità di trasmissione, congestione del canale e spazio di archiviazione. Tuttavia, se non utilizzi AVFS nell'archivio, ci vorrà molto tempo per ripristinare solo una parte dei dati. Se usi AVFS, incontrerai la sua "umidità".
Un'alternativa alla compressione a blocchi è squashfs: puoi montare, ad esempio, una partizione Samba sul server ed eseguire mksquashfs, ma questa utility funziona anche con i file, ad es. dipende dalla loro quantità.
Inoltre, quando si crea squashfs, viene sprecata molta RAM, il che può facilmente portare a chiamare oom-killer.
Sicurezza
È necessario proteggersi da una situazione in cui l'archivio o il server vengono violati. Se il server viene violato, è meglio che l'utente che scrive i dati non abbia i diritti per eliminare/modificare i file nell'archivio.Se l'archivio viene violato, è consigliabile limitare al massimo i diritti dell'utente di backup sul server.
Se il canale di backup può essere intercettato, è necessaria la crittografia.
Conclusione
Ogni sistema di backup ha i suoi pro e contro. In questo articolo, abbiamo cercato di evidenziare alcune sfumature nella scelta di un sistema di backup. Speriamo che possano aiutare i nostri lettori.Di conseguenza, quando si sceglie un sistema di backup per il proprio progetto, è necessario condurre test sul tipo di backup selezionato e prestare attenzione a:
- tempo di backup nella fase corrente del progetto;
- tempo di backup nel caso in cui siano presenti molti più dati;
- carico del canale;
- caricare sul sottosistema del disco sul server e nello spazio di archiviazione;
- tempo per ripristinare tutti i dati;
- tempo di recupero per una coppia di file;
- la necessità di coerenza dei dati, in particolare dei database;
- consumo di memoria e presenza di chiamate oom-killer;
Come soluzioni di backup, puoi utilizzare supload e il nostro cloud storage.
I lettori che non possono lasciare commenti qui sono invitati a unirsi a noi sul blog.
tag:
- backup
- backup
- seleziona



