Изучаем нейронные сети: с чего начать. Методы обучения нейронных сетей
В главе мы ознакомились с такими понятиями, как искусственный интеллект, машинное обучение и искусственные нейронные сети.
В этой главе я детально опишу модель искусственного нейрона, расскажу о подходах к обучению сети, а также опишу некоторые известные виды искусственных нейронных сетей, которые мы будем изучать в следующих главах.
Упрощение
В прошлой главе я постоянно говорил о каких-то серьезных упрощениях. Причина упрощений заключается в том, что никакие современные компьютеры не могут быстро моделировать такие сложные системы, как наш мозг. К тому же, как я уже говорил, наш мозг переполнен различными биологическими механизмами, не относящиеся к обработке информации.
Нам нужна модель преобразования входного сигнала в нужный нам выходной. Все остальное нас не волнует. Начинаем упрощать.
Биологическая структура → схема
В предыдущей главе вы поняли, насколько сложно устроены биологические нейронные сети и биологические нейроны. Вместо изображения нейронов в виде чудовищ с щупальцами давайте просто будем рисовать схемы.
Вообще говоря, есть несколько способов графического изображения нейронных сетей и нейронов. Здесь мы будем изображать искусственные нейроны в виде кружков.
Вместо сложного переплетения входов и выходов будем использовать стрелки, обозначающие направление движения сигнала.
Таким образом искусственная нейронная сеть может быть представлена в виде совокупности кружков (искусственных нейронов), связанных стрелками.
Электрические сигналы → числа
В реальной биологической нейронной сети от входов сети к выходам передается электрический сигнал. В процессе прохода по нейронной сети он может изменяться.

Электрический сигнал всегда будет электрическим сигналом. Концептуально ничего не изменяется. Но что же тогда меняется? Меняется величина этого электрического сигнала (сильнее/слабее). А любую величину всегда можно выразить числом (больше/меньше).
В нашей модели искусственной нейронной сети нам совершенно не нужно реализовывать поведение электрического сигнала, так как от его реализации все равно ничего зависеть не будет.
На входы сети мы будем подавать какие-то числа, символизирующие величины электрического сигнала, если бы он был. Эти числа будут продвигаться по сети и каким-то образом меняться. На выходе сети мы получим какое-то результирующее число, являющееся откликом сети.
Для удобства все равно будем называть наши числа, циркулирующие в сети, сигналами.
Синапсы → веса связей
Вспомним картинку из первой главы, на которой цветом были изображены связи между нейронами – синапсы. Синапсы могут усиливать или ослаблять проходящий по ним электрический сигнал.

Давайте характеризовать каждую такую связь определенным числом, называемым весом данной связи. Сигнал, прошедший через данную связь, умножается на вес соответствующей связи.
Это ключевой момент в концепции искусственных нейронных сетей, я объясню его подробнее. Посмотрите на картинку ниже. Теперь каждой черной стрелке (связи) на этой картинке соответствует некоторое число \(w_i \) (вес связи). И когда сигнал проходит по этой связи, его величина умножается на вес этой связи.

На приведенном выше рисунке вес стоит не у каждой связи лишь потому, что там нет места для обозначений. В реальности у каждой \(i \) -ой связи свой собственный \(w_i \) -ый вес.
Искусственный нейрон
Теперь мы переходим к рассмотрению внутренней структуры искусственного нейрона и того, как он преобразует поступающий на его входы сигнал.
На рисунке ниже представлена полная модель искусственного нейрона.

Не пугайтесь, ничего сложного здесь нет. Давайте рассмотрим все подробно слева направо.
Входы, веса и сумматор
У каждого нейрона, в том числе и у искусственного, должны быть какие-то входы, через которые он принимает сигнал. Мы уже вводили понятие весов, на которые умножаются сигналы, проходящие по связи. На картинке выше веса изображены кружками.
Поступившие на входы сигналы умножаются на свои веса. Сигнал первого входа \(x_1 \) умножается на соответствующий этому входу вес \(w_1 \) . В итоге получаем \(x_1w_1 \) . И так до \(n \) -ого входа. В итоге на последнем входе получаем \(x_nw_n \) .
Теперь все произведения передаются в сумматор. Уже исходя из его названия можно понять, что он делает. Он просто суммирует все входные сигналы, умноженные на соответствующие веса:
\[ x_1w_1+x_2w_2+\cdots+x_nw_n = \sum\limits^n_{i=1}x_iw_i \]
Математическая справка
Сигма – Википедия
Когда необходимо коротко записать большое выражение, состоящее из суммы повторяющихся/однотипных членов, то используют знак сигмы.
Рассмотрим простейший вариант записи:
\[ \sum\limits^5_{i=1}i=1+2+3+4+5 \]
Таким образом снизу сигмы мы присваиваем переменной-счетчику \(i \) стартовое значение, которое будет увеличиваться, пока не дойдет до верхней границы (в примере выше это 5).
Верхняя граница может быть и переменной. Приведу пример такого случая.
Пусть у нас есть \(n \) магазинов. У каждого магазина есть свой номер: от 1 до \(n \) . Каждый магазин приносит прибыль. Возьмем какой-то (неважно, какой) \(i \) -ый магазин. Прибыль от него равна \(p_i \) .
\[ P = p_1+p_2+\cdots+p_i+\cdots+p_n \]
Как видно, все члены этой суммы однотипны. Тогда их можно коротко записать следующим образом:
\[ P=\sum\limits^n_{i=1}p_i \]
Словами: «Просуммируй прибыли всех магазинов, начиная с первого и заканчивая \(n \) -ым». В виде формулы это гораздо проще, удобнее и красивее.
Результатом работы сумматора является число, называемое взвешенной суммой.
Взвешенная сумма (Weighted sum ) (\(net \) ) - сумма входных сигналов, умноженных на соответствующие им веса.
\[ net=\sum\limits^n_{i=1}x_iw_i \]
Роль сумматора очевидна – он агрегирует все входные сигналы (которых может быть много) в какое-то одно число – взвешенную сумму, которая характеризует поступивший на нейрон сигнал в целом. Еще взвешенную сумму можно представить как степень общего возбуждения нейрона.
Пример
Для понимания роли последнего компонента искусственного нейрона – функции активации – я приведу аналогию.
Давайте рассмотрим один искусственный нейрон. Его задача – решить, ехать ли отдыхать на море. Для этого на его входы мы подаем различные данные. Пусть у нашего нейрона будет 4 входа:
- Стоимость поездки
- Какая на море погода
- Текущая обстановка с работой
- Будет ли на пляже закусочная
Все эти параметры будем характеризовать 0 или 1. Соответственно, если погода на море хорошая, то на этот вход подаем 1. И так со всеми остальными параметрами.
Если у нейрона есть четыре входа, то должно быть и четыре весовых коэффициента. В нашем примере весовые коэффициенты можно представить как показатели важности каждого входа, влияющие на общее решение нейрона. Веса входов распределим следующим образом:
Нетрудно заметить, что очень большую роль играют факторы стоимости и погоды на море (первые два входа). Они же и будут играть решающую роль при принятии нейроном решения.
Пусть на входы нашего нейрона мы подаем следующие сигналы:
Умножаем веса входов на сигналы соответствующих входов:
Взвешенная сумма для такого набора входных сигналов равна 6:
\[ net=\sum\limits^4_{i=1}x_iw_i = 5 + 0 + 0 + 1 =6 \]
Вот на сцену выходит функция активации.
Функция активации
Просто так подавать взвешенную сумму на выход достаточно бессмысленно. Нейрон должен как-то обработать ее и сформировать адекватный выходной сигнал. Именно для этих целей и используют функцию активации.
Она преобразует взвешенную сумму в какое-то число, которое и является выходом нейрона (выход нейрона обозначим переменной \(out \) ).
Для разных типов искусственных нейронов используют самые разные функции активации. В общем случае их обозначают символом \(\phi(net) \) . Указание взвешенного сигнала в скобках означает, что функция активации принимает взвешенную сумму как параметр.
Функция активации (Activation function )(\(\phi(net) \) ) - функция, принимающая взвешенную сумму как аргумент. Значение этой функции и является выходом нейрона (\(out \) ).
Функция единичного скачка
Самый простой вид функции активации. Выход нейрона может быть равен только 0 или 1. Если взвешенная сумма больше определенного порога \(b \) , то выход нейрона равен 1. Если ниже, то 0.
Как ее можно использовать? Предположим, что мы поедем на море только тогда, когда взвешенная сумма больше или равна 5. Значит наш порог равен 5:
В нашем примере взвешенная сумма равнялась 6, а значит выходной сигнал нашего нейрона равен 1. Итак, мы едем на море.
Однако если бы погода на море была бы плохой, а также поездка была бы очень дорогой, но имелась бы закусочная и обстановка с работой нормальная (входы: 0011), то взвешенная сумма равнялась бы 2, а значит выход нейрона равнялся бы 0. Итак, мы никуда не едем.
В общем, нейрон смотрит на взвешенную сумму и если она получается больше его порога, то нейрон выдает выходной сигнал, равный 1.
Графически эту функцию активации можно изобразить следующим образом.

На горизонтальной оси расположены величины взвешенной суммы. На вертикальной оси - значения выходного сигнала. Как легко видеть, возможны только два значения выходного сигнала: 0 или 1. Причем 0 будет выдаваться всегда от минус бесконечности и вплоть до некоторого значения взвешенной суммы, называемого порогом. Если взвешенная сумма равна порогу или больше него, то функция выдает 1. Все предельно просто.
Теперь запишем эту функцию активации математически. Почти наверняка вы сталкивались с таким понятием, как составная функция. Это когда мы под одной функцией объединяем несколько правил, по которым рассчитывается ее значение. В виде составной функции функция единичного скачка будет выглядеть следующим образом:
\[ out(net) = \begin{cases} 0, net < b \\ 1, net \geq b \end{cases} \]
В этой записи нет ничего сложного. Выход нейрона (\(out \) ) зависит от взвешенной суммы (\(net \) ) следующим образом: если \(net \) (взвешенная сумма) меньше какого-то порога (\(b \) ), то \(out \) (выход нейрона) равен 0. А если \(net \) больше или равен порогу \(b \) , то \(out \) равен 1.
Сигмоидальная функция
На самом деле существует целое семейство сигмоидальных функций, некоторые из которых применяют в качестве функции активации в искусственных нейронах.
Все эти функции обладают некоторыми очень полезными свойствами, ради которых их и применяют в нейронных сетях. Эти свойства станут очевидными после того, как вы увидите графики этих функций.
Итак… самая часто используемая в нейронных сетях сигмоида - логистическая функция .

График этой функции выглядит достаточно просто. Если присмотреться, то можно увидеть некоторое подобие английской буквы \(S \) , откуда и пошло название семейства этих функций.
А вот так она записывается аналитически:
\[ out(net)=\frac{1}{1+\exp(-a \cdot net)} \]
Что за параметр \(a \) ? Это какое-то число, которое характеризует степень крутизны функции. Ниже представлены логистические функции с разным параметром \(a \) .

Вспомним наш искусственный нейрон, определяющий, надо ли ехать на море. В случае с функцией единичного скачка все было очевидно. Мы либо едем на море (1), либо нет (0).
Здесь же случай более приближенный к реальности. Мы до конца полностью не уверены (в особенности, если вы параноик) – стоит ли ехать? Тогда использование логистической функции в качестве функции активации приведет к тому, что вы будете получать цифру между 0 и 1. Причем чем больше взвешенная сумма, тем ближе выход будет к 1 (но никогда не будет точно ей равен). И наоборот, чем меньше взвешенная сумма, тем ближе выход нейрона будет к 0.
Например, выход нашего нейрона равен 0.8. Это значит, что он считает, что поехать на море все-таки стоит. Если бы его выход был бы равен 0.2, то это означает, что он почти наверняка против поездки на море.
Какие же замечательные свойства имеет логистическая функция?
- она является «сжимающей» функцией, то есть вне зависимости от аргумента (взвешенной суммы), выходной сигнал всегда будет в пределах от 0 до 1
- она более гибкая, чем функция единичного скачка – ее результатом может быть не только 0 и 1, но и любое число между ними
- во всех точках она имеет производную, и эта производная может быть выражена через эту же функцию
Именно из-за этих свойств логистическая функция чаще всего используются в качестве функции активации в искусственных нейронах.
Гиперболический тангенс
Однако есть и еще одна сигмоида – гиперболический тангенс. Он применяется в качестве функции активации биологами для более реалистичной модели нервной клетки.
Такая функция позволяет получить на выходе значения разных знаков (например, от -1 до 1), что может быть полезным для ряда сетей.
Функция записывается следующим образом:
\[ out(net) = \tanh\left(\frac{net}{a}\right) \]
В данной выше формуле параметр \(a \) также определяет степень крутизны графика этой функции.
А вот так выглядит график этой функции.

Как видите, он похож на график логистической функции. Гиперболический тангенс обладает всеми полезными свойствами, которые имеет и логистическая функция.
Что мы узнали?
Теперь вы получили полное представление о внутренней структуре искусственного нейрона. Я еще раз приведу краткое описание его работы.
У нейрона есть входы. На них подаются сигналы в виде чисел. Каждый вход имеет свой вес (тоже число). Сигналы на входе умножаются на соответствующие веса. Получаем набор «взвешенных» входных сигналов.
Затем взвешенная сумма преобразуется функцией активации и мы получаем выход нейрона .
Сформулируем теперь самое короткое описание работы нейрона – его математическую модель:
Математическая модель искусственного нейрона с \(n \) входами:
где
\(\phi \)
– функция активации
\(\sum\limits^n_{i=1}x_iw_i \)
– взвешенная сумма, как сумма \(n \)
произведений входных сигналов на соответствующие веса.
Виды ИНС
Мы разобрались со структурой искусственного нейрона. Искусственные нейронные сети состоят из совокупности искусственных нейронов. Возникает логичный вопрос – а как располагать/соединять друг с другом эти самые искусственные нейроны?
Как правило, в большинстве нейронных сетей есть так называемый входной слой , который выполняет только одну задачу – распределение входных сигналов остальным нейронам. Нейроны этого слоя не производят никаких вычислений.
Однослойные нейронные сети
В однослойных нейронных сетях сигналы с входного слоя сразу подаются на выходной слой. Он производит необходимые вычисления, результаты которых сразу подаются на выходы.
Выглядит однослойная нейронная сеть следующим образом:

На этой картинке входной слой обозначен кружками (он не считается за слой нейронной сети), а справа расположен слой обычных нейронов.
Нейроны соединены друг с другом стрелками. Над стрелками расположены веса соответствующих связей (весовые коэффициенты).
Однослойная нейронная сеть (Single-layer neural network ) - сеть, в которой сигналы от входного слоя сразу подаются на выходной слой, который и преобразует сигнал и сразу же выдает ответ.
Многослойные нейронные сети
Такие сети, помимо входного и выходного слоев нейронов, характеризуются еще и скрытым слоем (слоями). Понять их расположение просто – эти слои находятся между входным и выходным слоями.

Такая структура нейронных сетей копирует многослойную структуру определенных отделов мозга.

Название скрытый слой получил неслучайно. Дело в том, что только относительно недавно были разработаны методы обучения нейронов скрытого слоя. До этого обходились только однослойными нейросетями.
Многослойные нейронные сети обладают гораздо большими возможностями, чем однослойные.
Работу скрытых слоев нейронов можно сравнить с работой большого завода. Продукт (выходной сигнал) на заводе собирается по стадиям. После каждого станка получается какой-то промежуточный результат. Скрытые слои тоже преобразуют входные сигналы в некоторые промежуточные результаты.
Многослойная нейронная сеть (Multilayer neural network ) - нейронная сеть, состоящая из входного, выходного и расположенного(ых) между ними одного (нескольких) скрытых слоев нейронов.
Сети прямого распространения
Можно заметить одну очень интересную деталь на картинках нейросетей в примерах выше.
Во всех примерах стрелки строго идут слева направо, то есть сигнал в таких сетях идет строго от входного слоя к выходному.
Сети прямого распространения (Feedforward neural network ) (feedforward сети) - искусственные нейронные сети, в которых сигнал распространяется строго от входного слоя к выходному. В обратном направлении сигнал не распространяется.
Такие сети широко используются и вполне успешно решают определенный класс задач: прогнозирование, кластеризация и распознавание.
Однако никто не запрещает сигналу идти и в обратную сторону.
Сети с обратными связями
В сетях такого типа сигнал может идти и в обратную сторону. В чем преимущество?
Дело в том, что в сетях прямого распространения выход сети определяется входным сигналом и весовыми коэффициентами при искусственных нейронах.
А в сетях с обратными связями выходы нейронов могут возвращаться на входы. Это означает, что выход какого-нибудь нейрона определяется не только его весами и входным сигналом, но еще и предыдущими выходами (так как они снова вернулись на входы).

Возможность сигналов циркулировать в сети открывает новые, удивительные возможности нейронных сетей. С помощью таких сетей можно создавать нейросети, восстанавливающие или дополняющие сигналы. Другими словами такие нейросети имеют свойства кратковременной памяти (как у человека).
Сети с обратными связями (Recurrent neural network ) - искусственные нейронные сети, в которых выход нейрона может вновь подаваться на его вход. В более общем случае это означает возможность распространения сигнала от выходов к входам.
Обучение нейронной сети
Теперь давайте чуть более подробно рассмотрим вопрос обучения нейронной сети. Что это такое? И каким образом это происходит?
Что такое обучение сети?
Искусственная нейронная сеть – это совокупность искусственных нейронов. Теперь давайте возьмем, например, 100 нейронов и соединим их друг с другом. Ясно, что при подаче сигнала на вход, мы получим что-то бессмысленное на выходе.
Значит нам надо менять какие-то параметры сети до тех пор, пока входной сигнал не преобразуется в нужный нам выходной.
Что мы можем менять в нейронной сети?
Изменять общее количество искусственных нейронов бессмысленно по двум причинам. Во-первых, увеличение количества вычислительных элементов в целом лишь делает систему тяжеловеснее и избыточнее. Во-вторых, если вы соберете 1000 дураков вместо 100, то они все-равно не смогут правильно ответить на вопрос.
Сумматор изменить не получится, так как он выполняет одну жестко заданную функцию – складывать. Если мы его заменим на что-то или вообще уберем, то это вообще уже не будет искусственным нейроном.
Если менять у каждого нейрона функцию активации, то мы получим слишком разношерстную и неконтролируемую нейронную сеть. К тому же, в большинстве случаев нейроны в нейронных сетях одного типа. То есть они все имеют одну и ту же функцию активации.
Остается только один вариант – менять веса связей .
Обучение нейронной сети (Training) - поиск такого набора весовых коэффициентов, при котором входной сигнал после прохода по сети преобразуется в нужный нам выходной.
Такой подход к термину «обучение нейронной сети» соответствует и биологическим нейросетям. Наш мозг состоит из огромного количества связанных друг с другом нейросетей. Каждая из них в отдельности состоит из нейронов одного типа (функция активации одинаковая). Мы обучаемся благодаря изменению синапсов – элементов, которые усиливают/ослабляют входной сигнал.
Однако есть еще один важный момент. Если обучать сеть, используя только один входной сигнал, то сеть просто «запомнит правильный ответ». Со стороны будет казаться, что она очень быстро «обучилась». И как только вы подадите немного измененный сигнал, ожидая увидеть правильный ответ, то сеть выдаст бессмыслицу.
В самом деле, зачем нам сеть, определяющая лицо только на одном фото. Мы ждем от сети способности обобщать какие-то признаки и узнавать лица и на других фотографиях тоже.
Именно с этой целью и создаются обучающие выборки .
Обучающая выборка (Training set ) - конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит обучение сети.
После обучения сети, то есть когда сеть выдает корректные результаты для всех входных сигналов из обучающей выборки, ее можно использовать на практике.
Однако прежде чем пускать свежеиспеченную нейросеть в бой, часто производят оценку качества ее работы на так называемой тестовой выборке .
Тестовая выборка (Testing set ) - конечный набор входных сигналов (иногда вместе с правильными выходными сигналами), по которым происходит оценка качества работы сети.
Мы поняли, что такое «обучение сети» – подбор правильного набора весов. Теперь возникает вопрос – а как можно обучать сеть? В самом общем случае есть два подхода, приводящие к разным результатам: обучение с учителем и обучение без учителя.
Обучение с учителем
Суть данного подхода заключается в том, что вы даете на вход сигнал, смотрите на ответ сети, а затем сравниваете его с уже готовым, правильным ответом.
Важный момент. Не путайте правильные ответы и известный алгоритм решения! Вы можете обвести пальцем лицо на фото (правильный ответ), но не сможете сказать, как это сделали (известный алгоритм). Тут такая же ситуация.
Затем, с помощью специальных алгоритмов, вы меняете веса связей нейронной сети и снова даете ей входной сигнал. Сравниваете ее ответ с правильным и повторяете этот процесс до тех пор, пока сеть не начнет отвечать с приемлемой точностью (как я говорил в 1 главе, однозначно точных ответов сеть давать не может).
Обучение с учителем (Supervised learning ) - вид обучения сети, при котором ее веса меняются так, чтобы ответы сети минимально отличались от уже готовых правильных ответов.
Где взять правильные ответы?
Если мы хотим, чтобы сеть узнавала лица, мы можем создать обучающую выборку на 1000 фотографий (входные сигналы) и самостоятельно выделить на ней лица (правильные ответы).
Если мы хотим, чтобы сеть прогнозировала рост/падение цен, то обучающую выборку надо делать, основываясь на прошлых данных. В качестве входных сигналов можно брать определенные дни, общее состояние рынка и другие параметры. А в качестве правильных ответов – рост и падение цены в те дни.
Стоит отметить, что учитель, конечно же, не обязательно человек. Дело в том, что порой сеть приходится тренировать часами и днями, совершая тысячи и десятки тысяч попыток. В 99% случаев эту роль выполняет компьютер, а точнее, специальная компьютерная программа.
Обучение без учителя
Обучение без учителя применяют тогда, когда у нас нет правильных ответов на входные сигналы. В этом случае вся обучающая выборка состоит из набора входных сигналов.
Что же происходит при таком обучении сети? Оказывается, что при таком «обучении» сеть начинает выделять классы подаваемых на вход сигналов. Короче говоря – сеть начинает кластеризацию.
Например, вы демонстрируете сети конфеты, пирожные и торты. Вы никак не регулируете работу сети. Вы просто подаете на ее входы данные о данном объекте. Со временем сеть начнет выдавать сигналы трех разных типов, которые и отвечают за объекты на входе.
Обучение без учителя (Unsupervised learning ) - вид обучения сети, при котором сеть самостоятельно классифицирует входные сигналы. Правильные (эталонные) выходные сигналы не демонстрируются.
Выводы
В этой главе вы узнали все о структуре искусственного нейрона, а также получили полное представление о том, как он работает (и о его математической модели).
Более того, вы теперь знаете о различных видах искусственных нейронных сетей: однослойные, многослойные, а также feedforward сети и сети с обратными связями.
Вы также ознакомились с тем, что представляет собой обучение сети с учителем и без учителя.
Вы уже знаете необходимую теорию. Последующие главы – рассмотрение конкретных видов нейронных сетей, конкретные алгоритмы их обучения и практика программирования.
Вопросы и задачи
Материал этой главы надо знать очень хорошо, так как в ней содержатся основные теоретические сведения по искусственным нейронным сетям. Обязательно добейтесь уверенных и правильных ответов на все нижеприведенные вопросы и задачи.
Опишите упрощения ИНС по сравнению с биологическими нейросетями.
1. Сложную и запутанную структуру биологических нейронных сетей упрощают и представляют в виде схем. Оставляют только модель обработки сигнала.
2. Природа электрических сигналов в нейронных сетях одна и та же. Разница только в их величине. Убираем электрические сигналы, а вместо них используем числа, обозначающие величину проходящего сигнала.
Функцию активации часто обозначают за \(\phi(net) \) .
Запишите математическую модель искусственного нейрона.
Искусственный нейрон c \(n \) входами преобразовывает входной сигнал (число) в выходной сигнал (число) следующим образом:
\[ out=\phi\left(\sum\limits^n_{i=1}x_iw_i\right) \]
Чем отличаются однослойные и многослойные нейронные сети?
Однослойные нейронные сети состоят из одного вычислительного слоя нейронов. Входной слой подает сигналы сразу на выходной слой, который и преобразует сигнал, и сразу выдает результат.
Многослойные нейронные сети, помимо входного и выходного слоев, имеют еще и скрытые слои. Эти скрытые слои проводят какие-то внутренние промежуточные преобразования, наподобие этапов производства продуктов на заводе.
В чем отличие feedforward сетей от сетей с обратными связями?
Сети прямого распространения (feedforward сети) допускают прохождение сигнала только в одном направлении – от входов к выходам. Сети с обратными связями данных ограничений не имеют, и выходы нейронов могут вновь подаваться на входы.
Что такое обучающая выборка? В чем ее смысл?
Перед тем, как использовать сеть на практике (например, для решения текущих задач, ответов на которые у вас нет), необходимо собрать коллекцию задач с готовыми ответами, на которой и тренировать сеть. Это коллекция и называется обучающей выборкой.
Если собрать слишком маленький набор входных и выходных сигналов, то сеть просто запомнит ответы и цель обучения не будет достигнута.
Что понимают под обучением сети?
Под обучением сети понимают процесс изменения весовых коэффициентов искусственных нейронов сети с целью подобрать такую их комбинацию, которая преобразует входной сигнал в корректный выходной.
Что такое обучение с учителем и без него?
При обучении сети с учителем ей на входы подают сигналы, а затем сравнивают ее выход с заранее известным правильным выходом. Этот процесс повторяют до тех пор, пока не будет достигнута необходимая точность ответов.
Если сети только подают входные сигналы, без сравнения их с готовыми выходами, то сеть начинает самостоятельную классификацию этих входных сигналов. Другими словами она выполняет кластеризацию входных сигналов. Такое обучение называют обучением без учителя.
Итак, сегодня мы продолжим обсуждать тему нейронных сетей на нашем сайте, и, как я и обещал в первой статье (), речь пойдет об обучении сетей . Тема эта очень важна, поскольку одним из основных свойств нейронных сетей является именно то, что она не только действует в соответствии с каким-то четко заданным алгоритмом, а еще и совершенствуется (обучается) на основе прошлого опыта. И в этой статье мы рассмотрим некоторые формы обучения, а также небольшой практический пример.
Давайте для начала разберемся, в чем же вообще состоит цель обучения. А все просто – в корректировке весовых коэффициентов связей сети. Одним из самых типичных способов является управляемое обучение . Для его проведения нам необходимо иметь набор входных данных, а также соответствующие им выходные данные. Устанавливаем весовые коэффициенты равными некоторым малым величинам. А дальше процесс протекает следующим образом…
Мы подаем на вход сети данные, после чего сеть вычисляет выходное значение. Мы сравниваем это значение с имеющимся у нас (напоминаю, что для обучения используется готовый набор входных данных, для которых выходной сигнал известен) и в соответствии с разностью между этими значениями корректируем весовые коэффициенты нейронной сети. И эта операция повторяется по кругу много раз. В итоге мы получаем обученную сеть с новыми значениями весовых коэффициентов.
Вроде бы все понятно, кроме того, как именно и по какому алгоритму необходимо изменять значение каждого конкретного весового коэффициента. И в сегодняшней статье для коррекции весов в качестве наглядного примера мы рассмотрим правило Видроу-Хоффа , которое также называют дельта-правилом .
Дельта правило (правило Видроу-Хоффа).
Определим ошибку :
Здесь у нас – это ожидаемый (истинный) вывод сети, а – это реальный вывод (активность) выходного элемента. Помимо выходного элемента ошибки можно определить и для всех элементов скрытого слоя нейронной сети, об этом мы поговорим чуть позже.
Дельта-правило заключается в следующем – изменение величины весового коэффициента должно быть равно:
Где – норма обучения. Это число мы сами задаем перед началом обучения. – это сигнал, приходящий к элементу k от элемента j . А – ошибка элемента k .
Таким образом, в процессе обучения на вход сети мы подаем образец за образцом, и в результате получаем новые значения весовых коэффициентов. Обычно обучение заканчивается когда для всех вводимых образцов величина ошибки станет меньше определенной величины. После этого сеть подвергается тестированию при помощи новых данных, которые не участвовали в обучении. И по результатам этого тестирования уже можно сделать выводы, хорошо или нет справляется сеть со своими задачами.
С корректировкой весов все понятно, осталось определить, каким именно образом и по какому алгоритму будут происходить расчеты при обучении сети. Давайте рассмотрим обучение по алгоритму обратного распространения ошибок.
Алгоритм обратного распространения ошибок.
Этот алгоритм определяет два “потока” в сети. Входные сигналы двигаются в прямом направлении, в результате чего мы получаем выходной сигнал, из которого мы получаем значение ошибки. Величина ошибки двигается в обратном направлении, в результате происходит корректировка весовых коэффициентов связей сети. В конце статьи мы рассмотрим пример, наглядно демонстрирующий эти процессы.
Итак, для корректировки весовых значений мы будем использовать дельта-правило, которое мы уже обсудили. Вот только необходимо определить универсальное правило для вычисления ошибки каждого элемента сети после, собственно, прохождения через элемент (при обратном распространении ошибок).
Я, пожалуй, не буду приводить математические выводы и расчеты (несмотря на мою любовь к математике 🙂), чтобы не перегружать статью, ограничимся только итоговыми результатами:

Функция – это функция активности элемента. Давайте использовать логистическую функцию, для нее:
Подставляем в предыдущую формулу и получаем величину ошибки:
В этой формуле:
Наверняка сейчас еще все это кажется не совсем понятным, но не переживайте, при рассмотрении практического примера все встанет на свои места 😉
Собственно, давайте к нему и перейдем.
Перед обучением сети необходимо задать начальные значения весов – обычно они инициализируются небольшими по величине случайными значениями, к примеру из интервала (-0.5, 0.5). Но для нашего примера возьмем для удобства целые числа.
Рассмотрим нейронную сеть и вручную проведем расчеты для прямого и обратного “потоков” в сети.

На вход мы должны подать образец, пусть это будет (0.2, 0.5) . Ожидаемый выход сети – 0.4 . Норма обучения пусть будет равна 0.85 . Давайте проведем все расчеты поэтапно. Кстати, совсем забыл, в качестве функции активности мы будем использовать логистическую функцию:

Итак, приступаем…
Вычислим комбинированный ввод элементов 2 , 3 и 4 :
Активность этих элементов равна:
Комбинированный ввод пятого элемента:
Активность пятого элемента и в то же время вывод нейронной сети равен:
С прямым “потоком” разобрались, теперь перейдем к обратному “потоку”. Все расчеты будем производить в соответствии с формулами, которые мы уже обсудили. Итак, вычислим ошибку выходного элемента:
Тогда ошибки для элементов 2 , 3 и 4 равны соответственно:
Здесь значения -0.014, -0.028 и -0.056 получаются в результате прохода ошибки выходного элемента –0.014 по взвешенным связям в направлении к элементам 2 , 3 и 4 соответственно.
И, наконец-то, рассчитываем величину, на которую необходимо изменить значения весовых коэффициентов. Например, величина корректировки для связи между элементами 0 и 2 равна произведению величины сигнала, приходящего в элементу 2 от элемента 0 , ошибки элемента 2 и нормы обучения (все по дельта-правилу, которое мы обсудили в начале статьи):
Аналогичным образом производим расчеты и для остальных элементов:
Теперь новые весовые коэффициенты будут равны сумме предыдущего значения и величины поправки.
На этом обратный проход по сети закончен, цель достигнута 😉 Именно так и протекает процесс обучения по алгоритму обратного распространения ошибок. Мы рассмотрели этот процесс для одного набора данных, а чтобы получить полностью обученную сеть таких наборов должно быть, конечно же, намного больше, но алгоритм при этом остается неизменным, просто повторяется по кругу много раз для разных данных)
По просьбе читателей блога я решил добавить краткий пример обучения сети с двумя скрытыми слоями:

Итак, добавляем в нашу сеть два новых элемента (X и Y), которые теперь будут выполнять роль входных. На вход также подаем образец (0.2, 0.5) . Рассмотрим алгоритм в данном случае:
1. Прямой проход сети. Здесь все точно также как и для сети с одним скрытым слоем. Результатом будет значение .
2. Вычисляем ошибку выходного элемента:
3. Теперь нам нужно вычислить ошибки элементов 2, 3 и 4.
внутренних параметров под конкретную задачу.Алгоритм работы нейронной сети является итеративным, его шаги называют эпохами или циклами.
Эпоха - одна итерация в процессе обучения, включающая предъявление всех примеров из обучающего множества и, возможно, проверку качества обучения на контрольном множестве.
Процесс обучения осуществляется на обучающей выборке.
Обучающая выборка включает входные значения и соответствующие им выходные значения набора данных. В ходе обучения нейронная сеть находит некие зависимости выходных полей от входных.
Таким образом, перед нами ставится вопрос - какие входные поля (признаки) нам необходимо использовать. Первоначально выбор осуществляется эвристически, далее количество входов может быть изменено.
Сложность может вызвать вопрос о количестве наблюдений в наборе данных. И хотя существуют некие правила, описывающие связь между необходимым количеством наблюдений и размером сети, их верность не доказана.
Количество необходимых наблюдений зависит от сложности решаемой задачи. При увеличении количества признаков количество наблюдений возрастает нелинейно, эта проблема носит название "проклятие размерности". При недостаточном количестве данных рекомендуется использовать линейную модель .
Аналитик должен определить количество слоев в сети и количество нейронов в каждом слое .
Далее необходимо назначить такие значения весов и смещений, которые смогут минимизировать ошибку решения. Веса и смещения автоматически настраиваются таким образом, чтобы минимизировать разность между желаемым и полученным на выходе сигналами, которая называется ошибка обучения .
Ошибка обучения для построенной нейронной сети вычисляется путем сравнения выходных и целевых (желаемых) значений. Из полученных разностей формируется функция ошибок .
Функция ошибок - это целевая функция , требующая минимизации в процессе управляемого обучения нейронной сети .
С помощью функции ошибок можно оценить качество работы нейронной сети во время обучения. Например, часто используется сумма квадратов ошибок.
От качества обучения нейронной сети зависит ее способность решать поставленные перед ней задачи.
Переобучение нейронной сети
При обучении нейронных сетей часто возникает серьезная трудность, называемая проблемой переобучения (overfitting).
Переобучение , или чрезмерно близкая подгонка - излишне точное соответствие нейронной сети конкретному набору обучающих примеров, при котором сеть теряет способность к обобщению.
Переобучение возникает в случае слишком долгого обучения, недостаточного числа обучающих примеров или переусложненной структуры нейронной сети .
Переобучение связано с тем, что выбор обучающего (тренировочного) множества является случайным. С первых шагов обучения происходит уменьшение ошибки. На последующих шагах с целью уменьшения ошибки (целевой функции) параметры подстраиваются под особенности обучающего множества . Однако при этом происходит "подстройка" не под общие закономерности ряда, а под особенности его части - обучающего подмножества. При этом точность прогноза уменьшается.
Один из вариантов борьбы с переобучением сети - деление обучающей выборки на два множества (обучающее и тестовое).
На обучающем множестве происходит обучение нейронной сети . На тестовом множестве осуществляется проверка построенной модели. Эти
Самым важным свойством нейронных сетей является их способность обучаться на основе данных окружающей среды и в результате обучения повышать свою производительность. Повышение производительности происходит со временем в соответствии с определенными правилами. Обучение нейронной сети происходит посредством интерактивного процесса корректировки синаптических весов и порогов. В идеальном случае нейронная сеть получает знания об окружающей среде на каждой итерации процесса обучения.
С понятием обучения ассоциируется довольно много видов деятельности, поэтому сложно дать этому процессу однозначное определение. Более того, процесс обучения зависит от точки зрения на него. Именно это делает практически невозможным появление какого-либо точного определения этого понятия. Например, процесс обучения с точки зрения психолога в корне отличается от обучения с точки зрения школьного учителя. С позиций нейронной сети, вероятно, можно использовать следующее определение:
Обучение – это процесс, в котором свободные параметры нейронной сети настраиваются посредством моделирования среды, в которую эта сеть встроена. Тип обучения определяется способом подстройки этих параметров.
Это определение процесса обучения нейронной сети предполагает следующую последовательность событий:
- В нейронную сеть поступают стимулы из внешней среды.
- В результате первого пункта изменяются свободные параметры нейронной сети.
- После изменения внутренней структуры нейронная сеть отвечает на возбуждения уже иным образом.
Вышеуказанный список четких правил решения проблемы обучения нейронной сети называется алгоритмом обучения. Несложно догадаться, что не существует универсального алгоритма обучения, подходящего для всех архитектур нейронных сетей. Существует лишь набор средств, представленный множеством алгоритмов обучения, каждый из которых имеет свои достоинства. Алгоритмы обучения отличаются друг от друга способом настройки синаптических весов нейронов. Еще одной отличительной характеристикой является способ связи обучаемой нейронной сети с внешним миром. В этом контексте говорят о парадигме обучения, связанной с моделью окружающей среды, в которой функционирует данная нейронная сеть.
Существуют два концептуальных подхода к обучению нейронных сетей: обучение с учителем и обучение без учителя.
Обучение нейронной сети с учителем предполагает, что для каждого входного вектора из обучающего множества существует требуемое значение выходного вектора, называемого целевым. Эти вектора образуют обучающую пару. Веса сети изменяют до тех пор, пока для каждого входного вектора не будет получен приемлемый уровень отклонения выходного вектора от целевого.
Обучение нейронной сети без учителя является намного более правдоподобной моделью обучения с точки зрения биологических корней искусственных нейронных сетей. Обучающее множество состоит лишь из входных векторов. Алгоритм обучения нейронной сети подстраивает веса сети так, чтобы получались согласованные выходные векторы, т.е. чтобы предъявление достаточно близких входных векторов давало одинаковые выходы.
Добро пожаловать во вторую часть руководства по нейронным сетям. Сразу хочу принести извинения всем кто ждал вторую часть намного раньше. По определенным причинам мне пришлось отложить ее написание. На самом деле я не ожидал, что у первой статьи будет такой спрос и что так много людей заинтересует данная тема. Взяв во внимание ваши комментарии, я постараюсь предоставить вам как можно больше информации и в то же время сохранить максимально понятный способ ее изложения. В данной статье, я буду рассказывать о способах обучения/тренировки нейросетей (в частности метод обратного распространения) и если вы, по каким-либо причинам, еще не прочитали , настоятельно рекомендую начать с нее. В процессе написания этой статьи, я хотел также рассказать о других видах нейросетей и методах тренировки, однако, начав писать про них, я понял что это пойдет вразрез с моим методом изложения. Я понимаю, что вам не терпится получить как можно больше информации, однако эти темы очень обширны и требуют детального анализа, а моей основной задачей является не написать очередную статью с поверхностным объяснением, а донести до вас каждый аспект затронутой темы и сделать статью максимально легкой в освоении. Спешу расстроить любителей “покодить”, так как я все еще не буду прибегать к использованию языка программирования и буду объяснять все “на пальцах”. Достаточно вступления, давайте теперь продолжим изучение нейросетей.
Что такое нейрон смещения?

Перед тем как начать нашу основную тему, мы должны ввести понятие еще одного вида нейронов - нейрон смещения. Нейрон смещения или bias нейрон - это третий вид нейронов, используемый в большинстве нейросетей. Особенность этого типа нейронов заключается в том, что его вход и выход всегда равняются 1 и они никогда не имеют входных синапсов. Нейроны смещения могут, либо присутствовать в нейронной сети по одному на слое, либо полностью отсутствовать, 50/50 быть не может (красным на схеме обозначены веса и нейроны которые размещать нельзя). Соединения у нейронов смещения такие же, как у обычных нейронов - со всеми нейронами следующего уровня, за исключением того, что синапсов между двумя bias нейронами быть не может. Следовательно, их можно размещать на входном слое и всех скрытых слоях, но никак не на выходном слое, так как им попросту не с чем будет формировать связь.
Для чего нужен нейрон смещения?

Нейрон смещения нужен для того, чтобы иметь возможность получать выходной результат, путем сдвига графика функции активации вправо или влево. Если это звучит запутанно, давайте рассмотрим простой пример, где есть один входной нейрон и один выходной нейрон. Тогда можно установить, что выход O2 будет равен входу H1, умноженному на его вес, и пропущенному через функцию активации (формула на фото слева). В нашем конкретном случае, будем использовать сигмоид.
Из школьного курса математики, мы знаем, что если взять функцию y = ax+b и менять у нее значения “а”, то будет изменяться наклон функции (цвета линий на графике слева), а если менять “b”, то мы будем смещать функцию вправо или влево (цвета линий на графике справа). Так вот “а” - это вес H1, а “b” - это вес нейрона смещения B1. Это грубый пример, но примерно так все и работает (если вы посмотрите на функцию активации справа на изображении, то заметите очень сильное сходство между формулами). То есть, когда в ходе обучения, мы регулируем веса скрытых и выходных нейронов, мы меняем наклон функции активации. Однако, регулирование веса нейронов смещения может дать нам возможность сдвинуть функцию активации по оси X и захватить новые участки. Иными словами, если точка, отвечающая за ваше решение, будет находиться, как показано на графике слева, то ваша НС никогда не сможет решить задачу без использования нейронов смещения. Поэтому, вы редко встретите нейронные сети без нейронов смещения.
Также нейроны смещения помогают в том случае, когда все входные нейроны получают на вход 0 и независимо от того какие у них веса, они все передадут на следующий слой 0, но не в случае присутствия нейрона смещения. Наличие или отсутствие нейронов смещения - это гиперпараметр (об этом чуть позже). Одним словом, вы сами должны решить, нужно ли вам использовать нейроны смещения или нет, прогнав НС с нейронами смешения и без них и сравнив результаты.
ВАЖНО знать, что иногда на схемах не обозначают нейроны смещения, а просто учитывают их веса при вычислении входного значения например:
Input = H1*w1+H2*w2+b3
b3 = bias*w3
Так как его выход всегда равен 1, то можно просто представить что у нас есть дополнительный синапс с весом и прибавить к сумме этот вес без упоминания самого нейрона.
Как сделать чтобы НС давала правильные ответы?
Ответ прост - нужно ее обучать. Однако, насколько бы прост не был ответ, его реализация в плане простоты, оставляет желать лучшего. Существует несколько методов обучения НС и я выделю 3, на мой взгляд, самых интересных:- Метод обратного распространения (Backpropagation)
- Метод упругого распространения (Resilient propagation или Rprop)
- Генетический Алгоритм (Genetic Algorithm)
Что такое градиентный спуск?
Это способ нахождения локального минимума или максимума функции с помощью движения вдоль градиента. Если вы поймете суть градиентного спуска, то у вас не должно возникнуть никаких вопросов во время использования метода обратного распространения. Для начала, давайте разберемся, что такое градиент и где он присутствует в нашей НС. Давайте построим график, где по оси х будут значения веса нейрона(w) а по оси у - ошибка соответствующая этому весу(e).
Посмотрев на этот график, мы поймем, что график функция f(w) является зависимостью ошибки от выбранного веса. На этом графике нас интересует глобальный минимум - точка (w2,e2) или, иными словами, то место где график подходит ближе всего к оси х. Эта точка будет означать, что выбрав вес w2 мы получим самую маленькую ошибку - e2 и как следствие, самый лучший результат из всех возможных. Найти же эту точку нам поможет метод градиентного спуска (желтым на графике обозначен градиент). Соответственно у каждого веса в нейросети будет свой график и градиент и у каждого надо найти глобальный минимум.
Так что же такое, этот градиент? Градиент - это вектор который определяет крутизну склона и указывает его направление относительно какой либо из точек на поверхности или графике. Чтобы найти градиент нужно взять производную от графика по данной точке (как это и показано на графике). Двигаясь по направлению этого градиента мы будем плавно скатываться в низину. Теперь представим что ошибка - это лыжник, а график функции - гора. Соответственно, если ошибка равна 100%, то лыжник находиться на самой вершине горы и если ошибка 0% то в низине. Как все лыжники, ошибка стремится как можно быстрее спуститься вниз и уменьшить свое значение. В конечном случае у нас должен получиться следующий результат:

Представьте что лыжника забрасывают, с помощью вертолета, на гору. На сколько высоко или низко зависит от случая (аналогично тому, как в нейронной сети при инициализации веса расставляются в случайном порядке). Допустим ошибка равна 90% и это наша точка отсчета. Теперь лыжнику нужно спуститься вниз, с помощью градиента. На пути вниз, в каждой точке мы будем вычислять градиент, что будет показывать нам направление спуска и при изменении наклона, корректировать его. Если склон будет прямым, то после n-ого количества таких действий мы доберемся до низины. Но в большинстве случаев склон (график функции) будет волнистый и наш лыжник столкнется с очень серьезной проблемой - локальный минимум. Я думаю все знают, что такое локальный и глобальный минимум функции, для освежения памяти вот пример. Попадание в локальный минимум чревато тем, что наш лыжник навсегда останется в этой низине и никогда не скатиться с горы, следовательно мы никогда не сможем получить правильный ответ. Но мы можем избежать этого, снарядив нашего лыжника реактивным ранцем под названием момент (momentum). Вот краткая иллюстрация момента:

Как вы уже наверное догадались, этот ранец придаст лыжнику необходимое ускорение чтобы преодолеть холм, удерживающий нас в локальном минимуме, однако здесь есть одно НО. Представим что мы установили определенное значение параметру момент и без труда смогли преодолеть все локальные минимумы, и добраться до глобального минимума. Так как мы не можем просто отключить реактивный ранец, то мы можем проскочить глобальный минимум, если рядом с ним есть еще низины. В конечном случае это не так важно, так как рано или поздно мы все равно вернемся обратно в глобальный минимум, но стоит помнить, что чем больше момент, тем больше будет размах с которым лыжник будет кататься по низинам. Вместе с моментом в методе обратного распространения также используется такой параметр как скорость обучения (learning rate). Как наверняка многие подумают, чем больше скорость обучения, тем быстрее мы обучим нейросеть. Нет. Скорость обучения, также как и момент, является гиперпараметром - величина которая подбирается путем проб и ошибок. Скорость обучения можно напрямую связать со скоростью лыжника и можно с уверенностью сказать - тише едешь дальше будешь. Однако здесь тоже есть определенные аспекты, так как если мы совсем не дадим лыжнику скорости то он вообще никуда не поедет, а если дадим маленькую скорость то время пути может растянуться на очень и очень большой период времени. Что же тогда произойдет если мы дадим слишком большую скорость?

Как видите, ничего хорошего. Лыжник начнет скатываться по неправильному пути и возможно даже в другом направлении, что как вы понимаете только отдалит нас от нахождения правильного ответа. Поэтому во всех этих параметрах нужно находить золотую середину чтобы избежать не сходимости НС (об этом чуть позже).
Что такое Метод Обратного Распространения (МОР)?
Вот мы и дошли до того момента, когда мы можем обсудить, как же все таки сделать так, чтобы ваша НС могла правильно обучаться и давать верные решения. Очень хорошо МОР визуализирован на этой гифке:
А теперь давайте подробно разберем каждый этап. Если вы помните то в предыдущей статье мы считали выход НС. По другому это называется передача вперед (Forward pass), то есть мы последовательно передаем информацию от входных нейронов к выходным. После чего мы вычисляем ошибку и основываясь на ней делаем обратную передачу, которая заключается в том, чтобы последовательно менять веса нейронной сети, начиная с весов выходного нейрона. Значение весов будут меняться в ту сторону, которая даст нам наилучший результат. В моих вычисления я буду пользоваться методом нахождения дельты, так как это наиболее простой и понятный способ. Также я буду использовать стохастический метод обновления весов (об этом чуть позже).
Теперь давайте продолжим с того места, где мы закончили вычисления в предыдущей статье.
Данные задачи из предыдущей статьи

Данные: I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.
H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Результат - 0.33, ошибка - 45%.
Так как мы уже подсчитали результат НС и ее ошибку, то мы можем сразу приступить к МОРу. Как я уже упоминал ранее, алгоритм всегда начинается с выходного нейрона. В таком случае давайте посчитаем для него значение δ (дельта) по формуле 1.
 Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Так как у выходного нейрона нет исходящих синапсов, то мы будем пользоваться первой формулой (δ output), следственно для скрытых нейронов мы уже будем брать вторую формулу (δ hidden). Тут все достаточно просто: считаем разницу между желаемым и полученным результатом и умножаем на производную функции активации от входного значения данного нейрона. Прежде чем приступить к вычислениям я хочу обратить ваше внимание на производную. Во первых как это уже наверное стало понятно, с МОР нужно использовать только те функции активации, которые могут быть дифференцированы. Во вторых чтобы не делать лишних вычислений, формулу производной можно заменить на более дружелюбную и простую формула вида:
Таким образом наши вычисления для точки O1 будут выглядеть следующим образом.
Решение
O1output = 0.33
O1ideal = 1
Error = 0.45
δO1 = (1 - 0.33) * ((1 - 0.33) * 0.33) = 0.148
На этом вычисления для нейрона O1 закончены. Запомните, что после подсчета дельты нейрона мы обязаны сразу обновить веса всех исходящих синапсов этого нейрона. Так как в случае с O1 их нет, мы переходим к нейронам скрытого уровня и делаем тоже самое за исключение того, что формула подсчета дельты у нас теперь вторая и ее суть заключается в том, чтобы умножить производную функции активации от входного значения на сумму произведений всех исходящих весов и дельты нейрона с которой этот синапс связан. Но почему формулы разные? Дело в том что вся суть МОР заключается в том чтобы распространить ошибку выходных нейронов на все веса НС. Ошибку можно вычислить только на выходном уровне, как мы это уже сделали, также мы вычислили дельту в которой уже есть эта ошибка. Следственно теперь мы будем вместо ошибки использовать дельту которая будет передаваться от нейрона к нейрону. В таком случае давайте найдем дельту для H1:
Решение
H1output = 0.61
w5 = 1.5
δO1 = 0.148
δH1 = ((1 - 0.61) * 0.61) * (1.5 * 0.148) = 0.053
Теперь нам нужно найти градиент для каждого исходящего синапса. Здесь обычно вставляют 3 этажную дробь с кучей производных и прочим математическим адом, но в этом и вся прелесть использования метода подсчета дельт, потому что в конечном счете ваша формула нахождения градиента будет выглядеть вот так:
Здесь точка A это точка в начале синапса, а точка B на конце синапса. Таким образом мы можем подсчитать градиент w5 следующим образом:
Решение
H1output = 0.61
δO1 = 0.148
GRADw5 = 0.61 * 0.148 = 0.09
Сейчас у нас есть все необходимые данные чтобы обновить вес w5 и мы сделаем это благодаря функции МОР которая рассчитывает величину на которую нужно изменить тот или иной вес и выглядит она следующим образом:
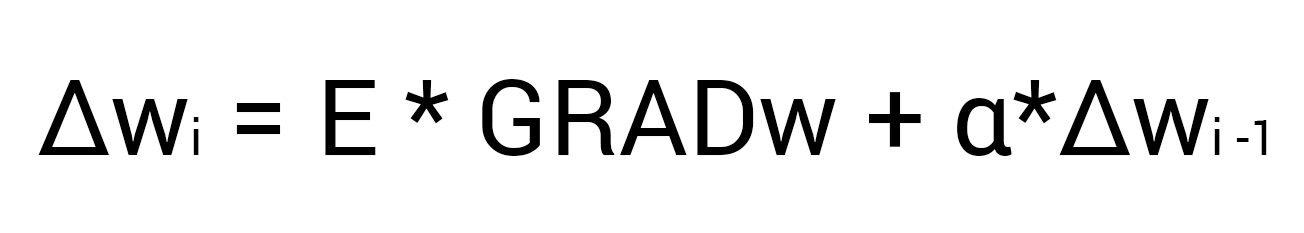
Настоятельно рекомендую вам не игнорировать вторую часть выражения и использовать момент так как это вам позволит избежать проблем с локальным минимумом.
Здесь мы видим 2 константы о которых мы уже говорили, когда рассматривали алгоритм градиентного спуска: E (эпсилон) - скорость обучения, α (альфа) - момент. Переводя формулу в слова получим: изменение веса синапса равно коэффициенту скорости обучения, умноженному на градиент этого веса, прибавить момент умноженный на предыдущее изменение этого веса (на 1-ой итерации равно 0). В таком случае давайте посчитаем изменение веса w5 и обновим его значение прибавив к нему Δw5.
Решение
E = 0.7
Α = 0.3
w5 = 1.5
GRADw5 = 0.09
Δw5(i-1) = 0
Δw5 = 0.7 * 0.09 + 0 * 0.3 = 0.063
w5 = w5 + Δw5 = 1.563
Таким образом после применения алгоритма наш вес увеличился на 0.063. Теперь предлагаю сделать вам тоже самое для H2.
Решение
H2output = 0.69
w6 = -2.3
δO1 = 0.148
E = 0.7
Α = 0.3
Δw6(i-1) = 0
δH2 = ((1 - 0.69) * 0.69) * (-2.3 * 0.148) = -0.07
GRADw6 = 0.69 * 0.148 = 0.1
Δw6 = 0.7 * 0.1 + 0 * 0.3 = 0.07
W6 = w6 + Δw6 = -2.2
И конечно не забываем про I1 и I2, ведь у них тоже есть синапсы веса которых нам тоже нужно обновить. Однако помним, что нам не нужно находить дельты для входных нейронов так как у них нет входных синапсов.
Решение
w1 = 0.45, Δw1(i-1) = 0
w2 = 0.78, Δw2(i-1) = 0
w3 = -0.12, Δw3(i-1) = 0
w4 = 0.13, Δw4(i-1) = 0
δH1 = 0.053
δH2 = -0.07
E = 0.7
Α = 0.3
GRADw1 = 1 * 0.053 = 0.053
GRADw2 = 1 * -0.07 = -0.07
GRADw3 = 0 * 0.053 = 0
GRADw4 = 0 * -0.07 = 0
Δw1 = 0.7 * 0.053 + 0 * 0.3 = 0.04
Δw2 = 0.7 * -0.07 + 0 * 0.3 = -0.05
Δw3 = 0.7 * 0 + 0 * 0.3 = 0
Δw4 = 0.7 * 0 + 0 * 0.3 = 0
W1 = w1 + Δw1 = 0.5
w2 = w2 + Δw2 = 0.73
w3 = w3 + Δw3 = -0.12
w4 = w4 + Δw4 = 0.13
Теперь давайте убедимся в том, что мы все сделали правильно и снова посчитаем выход НС только уже с обновленными весами.
Решение
I1 = 1
I2 = 0
w1 = 0.5
w2 = 0.73
w3 = -0.12
w4 = 0.13
w5 = 1.563
w6 = -2.2
H1input = 1 * 0.5 + 0 * -0.12 = 0.5
H1output = sigmoid(0.5) = 0.62
H2input = 1 * 0.73 + 0 * 0.124 = 0.73
H2output = sigmoid(0.73) = 0.675
O1input = 0.62* 1.563 + 0.675 * -2.2 = -0.51
O1output = sigmoid(-0.51) = 0.37
O1ideal = 1 (0xor1=1)
Error = ((1-0.37)^2)/1=0.39
Результат - 0.37, ошибка - 39%.
Как мы видим после одной итерации МОР, нам удалось уменьшить ошибку на 0.04 (6%). Теперь нужно повторять это снова и снова, пока ваша ошибка не станет достаточно мала.
Что еще нужно знать о процессе обучения?
Нейросеть можно обучать с учителем и без (supervised, unsupervised learning).Обучение с учителем - это тип тренировок присущий таким проблемам как регрессия и классификация (им мы и воспользовались в примере приведенном выше). Иными словами здесь вы выступаете в роли учителя а НС в роли ученика. Вы предоставляете входные данные и желаемый результат, то есть ученик посмотрев на входные данные поймет, что нужно стремиться к тому результату который вы ему предоставили.
Обучение без учителя - этот тип обучения встречается не так часто. Здесь нет учителя, поэтому сеть не получает желаемый результат или же их количество очень мало. В основном такой вид тренировок присущ НС у которых задача состоит в группировке данных по определенным параметрам. Допустим вы подаете на вход 10000 статей на хабре и после анализа всех этих статей НС сможет распределить их по категориям основываясь, например, на часто встречающихся словах. Статьи в которых упоминаются языки программирования, к программированию, а где такие слова как Photoshop, к дизайну.
Существует еще такой интересный метод, как обучение с подкреплением (reinforcement learning). Этот метод заслуживает отдельной статьи, но я попытаюсь вкратце описать его суть. Такой способ применим тогда, когда мы можем основываясь на результатах полученных от НС, дать ей оценку. Например мы хотим научить НС играть в PAC-MAN, тогда каждый раз когда НС будет набирать много очков мы будем ее поощрять. Иными словами мы предоставляем НС право найти любой способ достижения цели, до тех пор пока он будет давать хороший результат. Таким способом, сеть начнет понимать чего от нее хотят добиться и пытается найти наилучший способ достижения этой цели без постоянного предоставления данных “учителем”.
Также обучение можно производить тремя методами: стохастический метод (stochastic), пакетный метод (batch) и мини-пакетный метод (mini-batch). Существует очень много статей и исследований на тему того, какой из методов лучше и никто не может прийти к общему ответу. Я же сторонник стохастического метода, однако я не отрицаю тот факт, что каждый метод имеет свои плюсы и минусы.
Вкратце о каждом методе:
Стохастический (его еще иногда называют онлайн) метод работает по следующему принципу - нашел Δw, сразу обнови соответствующий вес.
Пакетный метод же работает по другому. Мы суммируем Δw всех весов на текущей итерации и только потом обновляем все веса используя эту сумму. Один из самых важных плюсов такого подхода - это значительная экономия времени на вычисление, точность же в таком случае может сильно пострадать.
Мини-пакетный метод является золотой серединой и пытается совместить в себе плюсы обоих методов. Здесь принцип таков: мы в свободном порядке распределяем веса по группам и меняем их веса на сумму Δw всех весов в той или иной группе.
Что такое гиперпараметры?
Гиперпараметры - это значения, которые нужно подбирать вручную и зачастую методом проб и ошибок. Среди таких значений можно выделить:- Момент и скорость обучения
- Количество скрытых слоев
- Количество нейронов в каждом слое
- Наличие или отсутствие нейронов смещения
Что такое сходимость?

Сходимость говорит о том, правильная ли архитектура НС и правильно ли были подобраны гиперпараметры в соответствии с поставленной задачей. Допустим наша программа выводит ошибку НС на каждой итерации в лог. Если с каждой итерацией ошибка будет уменьшаться, то мы на верном пути и наша НС сходится. Если же ошибка будет прыгать вверх - вниз или застынет на определенном уровне, то НС не сходится. В 99% случаев это решается изменением гиперпараметров. Оставшийся 1% будет означать, что у вас ошибка в архитектуре НС. Также бывает, что на сходимость влияет переобучение НС.
Что такое переобучение?
Переобучение, как следует из названия, это состояние нейросети, когда она перенасыщена данными. Это проблема возникает, если слишком долго обучать сеть на одних и тех же данных. Иными словами, сеть начнет не учиться на данных, а запоминать и “зубрить” их. Соответственно, когда вы уже будете подавать на вход этой НС новые данные, то в полученных данных может появиться шум, который будет влиять на точность результата. Например, если мы будем показывать НС разные фотографии яблок (только красные) и говорить что это яблоко. Тогда, когда НС увидит желтое или зеленое яблоко, оно не сможет определить, что это яблоко, так как она запомнила, что все яблоки должны быть красными. И наоборот, когда НС увидит что-то красное и по форме совпадающее с яблоком, например персик, она скажет, что это яблоко. Это и есть шум. На графике шум будет выглядеть следующим образом.
Видно, что график функции сильно колеблется от точки к точке, которые являются выходными данными (результатом) нашей НС. В идеале, этот график должен быть менее волнистый и прямой. Чтобы избежать переобучения, не стоит долго тренировать НС на одних и тех же или очень похожих данных. Также, переобучение может быть вызвано большим количеством параметров, которые вы подаете на вход НС или слишком сложной архитектурой. Таким образом, когда вы замечаете ошибки (шум) в выходных данных после этапа обучения, то вам стоит использовать один из методов регуляризации, но в большинстве случаев это не понадобиться.
Заключение
Надеюсь эта статья смогла прояснить ключевые моменты такого нелегко предмета, как Нейронные сети. Однако я считаю, что сколько бы ты статей не прочел, без практики такую сложную тему освоить невозможно. Поэтому, если вы только в начале пути и хотите изучить эту перспективную и развивающуюся отрасль, то советую начать практиковаться с написания своей НС, а уже после прибегать к помощи различных фреймворков и библиотек. Также, если вам интересен мой метод изложения информации и вы хотите, чтобы я написал статьи на другие темы связанные с Машинным обучением, то проголосуйте в опросе ниже за ту тему которую вам интересна. До встречи в будущих статьях:)Только зарегистрированные пользователи могут участвовать в опросе. Войдите , пожалуйста.



